数据采集第六次作业
作业①:
作业①:
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250

作业②:
(1)代码如下:
import urllib.request
from bs4 import BeautifulSoup
import re
from openpyxl import Workbook
import threading
def main():
getData("https://movie.douban.com/top250")
threads = []
for i in threads:
i.join()
def askURL(url):
# 模拟浏览器头部,向服务器请求
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
# 用户代理表示:告诉服务器我们是什么类型的机器,本质上告诉服务器,我们可以接受什么水平的信息
request = urllib.request.Request(url, headers=head) #添加头部信息
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
#print(html) #打印
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 爬取网页
def getData(baseurl):
global threads
wb = Workbook() # class实例化
count = 0
ws = wb.active # 激活工作表
title = ["排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数", "引用", "文件路径"]
ws.append(title)
for i in range(9): #爬取页数
images = []
url = baseurl + "?start=" +str(i*25)
html = askURL(url) # 保存获取到的网页源码
# 2 逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for tag in soup.find_all(attrs={"class": "item"}):
#print(tag)
count += 1
rank = tag.find('em').string
name = tag.find('span').string
people = tag.p.get_text().split('/')[0]
#print(people)
try:
director = re.findall(r"(导演.+?)主演", people)[0].replace(u"\xa0",u"").replace("导演:","").replace("","")
#print(director)
actor = re.findall(r"(主演.*)", people)[0].replace(u"\xa0", u"").replace("主演:", "").replace("", "")
#print(actor)
except Exception as e:
pass
#年份
time = tag.p.get_text().split('\n')[2].split('/')[0].replace(" ","")
country = tag.p.get_text().split('/')[-2]
style = tag.p.get_text().split('\n')[2].split('/')[-1]
score = tag.find_all('span')[4].get_text()
# 评价人数
valuation = tag.find_all('span')[-2].get_text()
regex = re.compile(r"\d+\.?\d*") # 使用正则表达式保留数字
num = (regex.findall(valuation))[0]
quote = tag.find(attrs={'class':'inq'}).string
image = tag.img.get('src')
imageName = name+str(count)+'.jpg'
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
line = [rank,name,director,actor,time,country,style,score,num,quote,imageName] # 把数据中每一项整理出来
ws.append(line) # 将数据以行的形式添加到xlsx中
wb.save(r'C:\Users\Administrator\Desktop\final1.xlsx') # 保存xlsx文件
def download(img_url,img_name):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
try:
if img_url[len(img_url)-4] == ".":
ext = img_url[len(img_url)-4:]
else:
ext = ""
req = urllib.request.Request(img_url,headers=head)
data = urllib.request.urlopen(req,timeout=100).read()
fobj = open("./images/" + img_name + ext,"wb")
fobj.write(data)
fobj.close()
except Exception as e:
print(e)
if __name__ == "__main__":
main()
(2)结果图片:
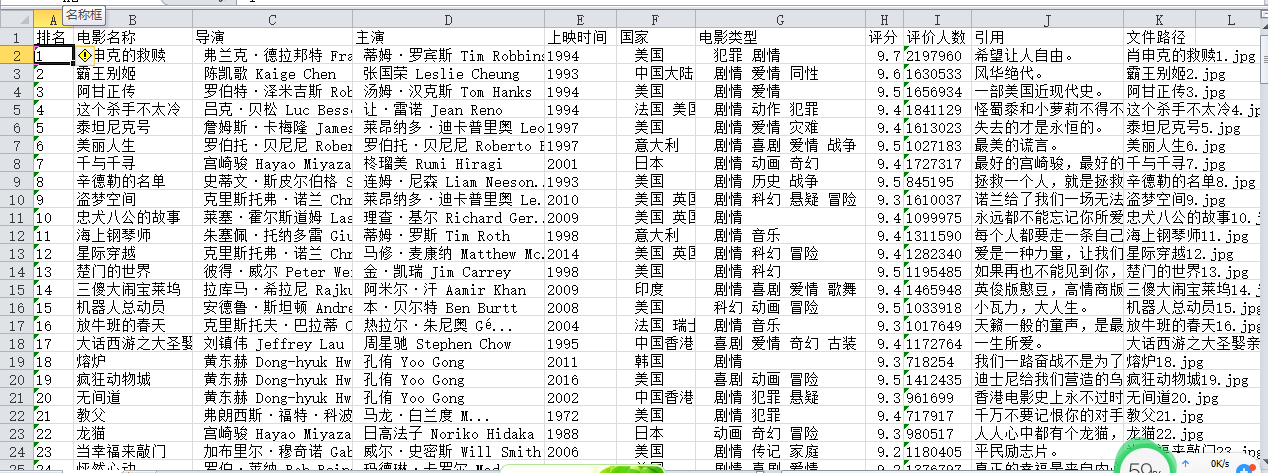
(3)心得体会:
1、用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据,每部电影的图片图片名字为电影名,采用多线程的方法爬取这次作业运用到上述知识点,算是对之前内容的巩固和复习。2、最令我无语的一点是,下载图片的时候好像被网站识别出来是机器爬取
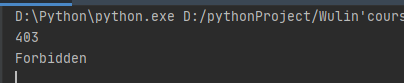
返回403错误,而且刚开始我不知道是这个原因,还以为是自己哪里写错了。后来听到同学讨论我才知道可能是被反爬了。怎么解决呢?先放置两天。第三天再来爬就OK了。
3、其次是这次作业的一个难点就是,为了能够让爬取的内容的格式像老师表达的那样美观,导演、主演的获取和分割是一个难点。因为他们都是在一个标签里面的内容,所以有点难分割,于是就捣鼓来捣鼓去,把他们分离。如果不分割就会显得非常不美观,本来想放弃,但是强迫症让我必须把他们变得整整齐齐。
作业②
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
关键词:学生自由选择
输出信息:MYSQL的输出信息如下:

(1)代码如下:
scrapy
import scrapy
from scrapy.http import Request
from ..items import UniversityItem
from bs4 import UnicodeDammit
class UniversitySpider(scrapy.Spider):
name = 'university'
start_urls = ["https://www.shanghairanking.cn/rankings/bcur/2020"]
#start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
# 获取外汇信息
data = selector.xpath('//*[@id="content-box"]/div[2]/table/tbody/tr') #找出所有学校
#print(data.extract())
for tr in data:
item = UniversityItem()
#print(tr.extract())
rank = tr.xpath("./td[position()=1]/text()").extract_first().replace("\n","").replace(" ","") #注意是当前标签的子标
item['rank'] = rank
item['name'] = tr.xpath("./td/a/text()").extract_first()
item['city'] = tr.xpath("./td[position()=3]/text()").extract_first().replace(" ", "").replace("\n","")
url = "https://www.shanghairanking.cn/"+tr.xpath("./td[position()=2]/a/@href").extract_first()
yield Request(url, meta={'item': item}, callback=self.parse_detail)
except Exception as err:
print(err)
def parse_detail(self, response):
item = response.meta['item']
# 获取到二层链接中要爬取的页面的xpath
item['info'] = response.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[6]/div[3]/div/p/text()').extract()[0]
item['officialURL'] = response.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div/div/table/tbody/tr[2]/td[1]/div/a/@href').extract()[0]
file = response.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div/div/table/tbody/tr[1]/td[1]/img/@src').extract()[0]
item['file'] = file
#print(file)
yield item
item
class UniversityItem(scrapy.Item):
rank = scrapy.Field()
name = scrapy.Field()
city = scrapy.Field()
officialURL = scrapy.Field()
info = scrapy.Field()
file = scrapy.Field()
pipeline
from itemadapter import ItemAdapter
import pymysql
import urllib
class UniversityPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from university")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
url = item['file']
req = urllib.request.Request(url)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:\\pythonProject\\Wulin'course\\images2\\" + item['rank']+".jpg",
"wb") # 打开一个文件,这个
fobj.write(data) # 写入数据
fobj.close() # 关闭文件
print(item["info"])
if self.opened:
self.cursor.execute(
"insert into university(`rank`,`name`,`city`,officialURL,`info`,`file`) values(%s,%s,%s,%s,%s,%s)",
(item["rank"], item["name"], item["city"], item["officialURL"],item["info"],item["rank"]+".jpg"))
self.count += 1
except Exception as err:
print(err)
return item
settings
BOT_NAME = 'university'
SPIDER_MODULES = ['university.spiders']
NEWSPIDER_MODULE = 'university.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'university (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
(2)结果图片:


(3)心得体会:
1、遇到报错,内容显示不出来,显示问号。其实是这个列值要加’’,这个符号。

2、这次实验通过Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。本次实验很好的运用到了上述知识点来解决问题。
3、再者对于院校信息的详细内容爬取需要用到scrapy的二级页面爬取,进入其他链接页面,以便爬取详细信息。学习到了如何进入二级页面爬取,算是有所收获。
作业③:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式如下
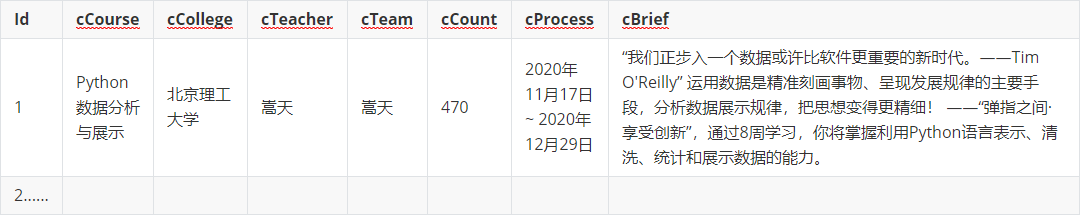
(1)代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import pymysql
def start_spider():
# 请求url
driver = webdriver.Chrome()
driver.get("https://www.icourse163.org/")
driver.maximize_window() # 页面呈现为最大的形式
driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']").click()
driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']//span[@class='ux-login-set-scan-code_ft_back']").click() # 选择另一种方式登录
time.sleep(1)
driver.find_elements_by_xpath("//div[@class='ux-tabs-underline']//ul[@class='ux-tabs-underline_hd']//li")[1].click() #选择手机登录
time.sleep(1)
temp_iframe_id = driver.find_elements_by_tag_name('iframe')[1].get_attribute('id')
driver.switch_to.frame(temp_iframe_id)
# 登录部分
driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('*******') #
time.sleep(2)
driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('*****')
time.sleep(1.5)
driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(2)
# 点击我的课程
driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']").click()
time.sleep(3)
count = 0
for link in driver.find_elements_by_xpath("//div[@class='course-card-wrapper']"):
# 课程名称
name = link.find_element_by_xpath('.//span[@class="text"]').text
#print("course name ", name)
school_name = link.find_element_by_xpath(".//div[@class='school']//a").text
#print("school ", school_name)
# 进入每个课程页面爬取详细内容
link.click()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(3)
driver.find_element_by_xpath("//div[@class='m-learnhead']//div[@class='f-fl info']//a[@hidefocus='true']").click()
time.sleep(3)
windows = driver.window_handles
driver.switch_to.window(windows[-1])
person = driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']")
m_teacher = person[0].find_element_by_xpath("//div[@class='cnt f-fl']//h3[@class='f-fc3']").text.strip()
team_member = ""
for j in range(1, len(person)):
team_member += person[j].text.strip().split("\n")[0]
team_member += " "
if len(team_member)<1:
team_member=m_teacher
join = driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text.strip().replace("已有",'')
introduction = driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text.strip()
process = driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']").text.strip().replace("开课时间:",'')
#print(name,school_name,m_teacher,team_member,join,process,introduction)
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="mydb", charset="utf8")
# 获取游标
cursor = conn.cursor()
# 插入数据,注意看有变量的时候格式
try:
cursor.execute(
"INSERT INTO final_mooc (`id`,`course`,`college`,`teacher`,`team`,`count`,`process`,`brief`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(count), name, school_name, m_teacher, team_member, join, process, introduction))
# 提交
except Exception as err:
print("error is ")
print(err)
# 关闭连接
conn.commit()
conn.close()
driver.close()
windows = driver.window_handles
driver.switch_to.window(windows[0])
time.sleep(1)
windows = driver.window_handles
for i in range(1, len(windows)):
driver.switch_to.window(windows[i])
time.sleep(0.5)
driver.close()
windows = driver.window_handles
driver.switch_to.window(windows[0])
def main():
start_spider()
if __name__ == '__main__':
main()
(2)结果图片:
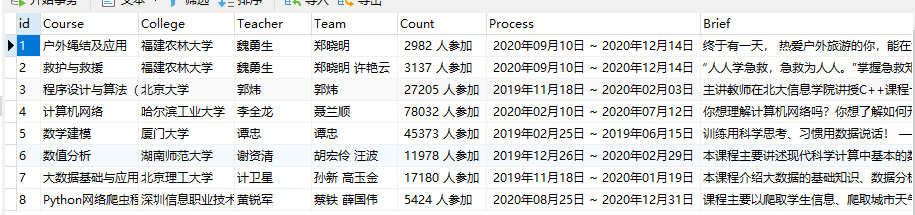

(3)心得体会:
1、对于登录操作一开始不知道如何下手,于这是上次写作业不写这个留下来的坑,于是好好看了老师的ppt,再加上百度,就能看出该怎么操作。 参考 https://www.cnblogs.com/ketangxiaohai/p/9216483.html2、遇到比较难的问题就是要点进一个个页面来详细获得每一个课程的内容,于是窗口打开问题就出现了。问题的解决driver.window_handles,切换不同窗口。
3、gif图,上网百度后,下载了gifcam,还挺好用的。新技能get。
4、这次作业能够运用到 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。获取了我mooc里面的课程内容,我的课程还挺少的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号