数据采集第五次作业
作业①:
- 要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
Selenium框架爬取京东商城某类商品信息及图片,关键词由设计者自行选取。 - 候选网站:http://www.jd.com/
- 关键词:学生自由选择。
- 输出信息:

(1)代码如下:
import datetime
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.keys import Keys
import urllib.request
import threading
import sqlite3
import os
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
firefox_options = Options()
#firefox_options.add_argument("——headless")
#firefox_options.add_argument("——disable-gpu")
self.driver = Firefox(options=firefox_options)
self.threads = []
self.No = 0
self.imgNo = 0
try:
self.con = sqlite3.connect("selenium.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table phones")
except:
pass
try:
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print("err0")
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print("err1")
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print("err2")
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print("err3")
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
(2)结果图片:


(3)心得体会:
爬取了京东商城有关于手机的东西,理清了一下思路。作业②
1.要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
2.候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.输出信息:
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
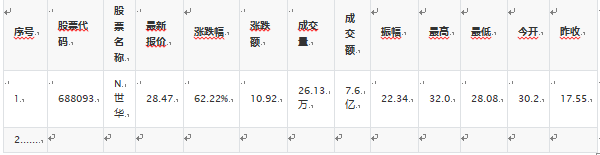
(1)代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import pymysql
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
# 声明一个list,存储dict
data_list = []
def start_spider(url):
# 请求url
browser.get(url)
# 显示等待商品信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "table_wrapper-table")
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
# 开始提取信息,找到ul标签下的全部li标签
count = 0
for link in browser.find_elements_by_xpath('//tbody/tr'):
count += 1
#代码
id_stock = link.find_element_by_xpath('./td[position()=2]').text
#股票名
name = link.find_element_by_xpath('.//td[@class="mywidth"]').text
#价格
new_price = link.find_element_by_xpath('.//td[@class="mywidth2"]').text
#涨跌幅
ud_range= link.find_element_by_xpath('.//td[@class="mywidth"]').text
#涨跌额
ud_num = link.find_element_by_xpath('./td[position()=6]').text
#成交量
deal_count = link.find_element_by_xpath('./td[position()=8]').text
#成交额
turnover = link.find_element_by_xpath('./td[position()=9]').text
# 振幅
amplitude = link.find_element_by_xpath('./td[position()=10]').text
# 最高
high = link.find_element_by_xpath('./td[position()=11]').text
# 最低
low = link.find_element_by_xpath('./td[position()=12]').text
# 今开
today = link.find_element_by_xpath('./td[position()=13]').text
# 昨收
yesterday = link.find_element_by_xpath('./td[position()=14]').text
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="mydb", charset="utf8")
# 获取游标
cursor = conn.cursor()
# 插入数据,注意看有变量的时候格式
try:
cursor.execute(
"INSERT INTO stocks (`id`,`id_stock`,`name`,`new_price`,`ud_range`,`ud_num`,`deal_count`,`turnover`,`amplitude`,`high`,`low`,`today`,`yesterday`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (count,id_stock,name,new_price,ud_range,str(ud_num),deal_count,turnover,amplitude,high,low,today,yesterday))
# 提交
except Exception as err:
print("error is ")
print(err)
# 关闭连接
conn.commit()
conn.close()
# 遍历
def main():
# url
str = ['hs','sh','sz']
for i in str:
url = 'http://quote.eastmoney.com/center/gridlist.html#'+i+'_a_board'
start_spider(url)
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()
(2)结果图片:
'hs'

'sh'

'sz'
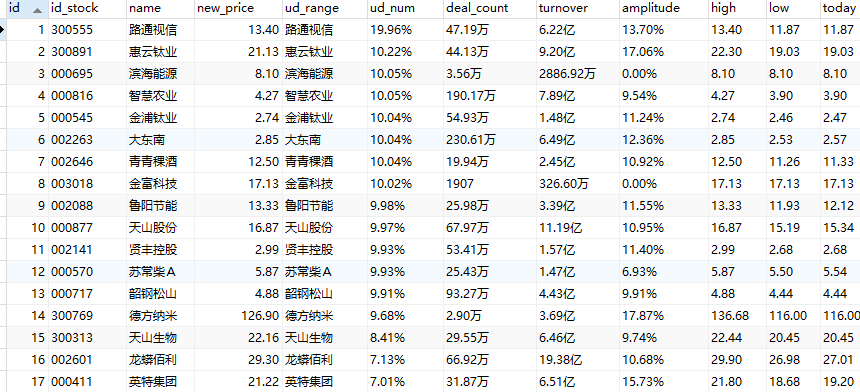
(3)心得体会:
感觉了解了html的格式之后,用xpath爬取就会非常方便。我的代码还是不够优雅。看起来重复的部分有点多,如果能有一个函数把xpath寻找的内容再封装一下,代码可能会更加简洁。但是最近好忙。作业③:
-
要求:熟练掌握 Selenium 查找HTML元素、实现用户登录、 爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介) -
候选网站:中国mooc网: https://www.icourse163.org
-
输出信息:
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
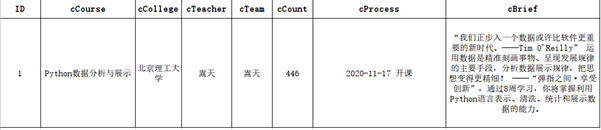
(1)代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import pymysql
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
url = "https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/"
# 声明一个list,存储dict
data_list = []
def start_spider():
# 请求url
browser.get(url)
# 显示等待商品信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "j-courseCardListBox")
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
# 开始提取信息,找到ul标签下的全部li标签
count = 0
for link in browser.find_elements_by_xpath('//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
count += 1
#课程号
# course_id = link.find_element_by_xpath('.//div[@class="p-name"]//em').text
#课程名称
course_name = link.find_element_by_xpath('.//span[@class=" u-course-name f-thide"]').text
print("course name ",course_name)
school_name = link.find_element_by_xpath('.//a[@class="t21 f-fc9"]').text
print("school ", school_name)
#主讲教师
m_teacher = link.find_element_by_xpath('.//a[@class="f-fc9"]').text
print("laoshi:", m_teacher)
#团队成员
try:
team_member = link.find_element_by_xpath('.//span[@class="f-fc9"]').text
except Exception as err:
team_member = 'none'
#print("团队:",team_member)
#参加人数
join = link.find_element_by_xpath('.//span[@class="hot"]').text
join.replace('参加','')
print("参加人数",join)
#课程进度
process = link.find_element_by_xpath('.//span[@class="txt"]').text
print('jingdu ',process)
#课程简介
introduction = link.find_element_by_xpath('.//span[@class="p5 brief f-ib f-f0 f-cb"]').text
print(introduction)
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="mydb", charset="utf8")
# 获取游标
cursor = conn.cursor()
# 插入数据,注意看有变量的时候格式
try:
cursor.execute(
"INSERT INTO mooc (`id`,`course`,`college`,`teacher`,`team`,`count`,`process`,`brief`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(count),course_name,school_name,m_teacher,team_member,join,process,introduction))
# 提交
except Exception as err:
print("error is ")
print(err)
# 关闭连接
conn.commit()
conn.close()
# 遍历
def main():
start_spider()
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()
(2)结果图片:
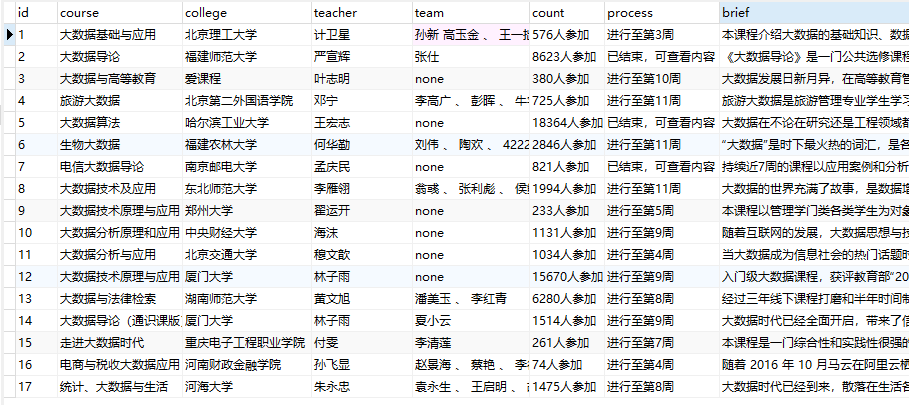

 浙公网安备 33010602011771号
浙公网安备 33010602011771号