数据采集第四次作业
作业一
作业①:要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
关键词:学生自由选择
输出信息:MYSQL的输出信息如下

(1)代码如下:
import scrapy
from ..items import BookkItem
from bs4 import UnicodeDammit
class MybookSpider(scrapy.Spider):
name = "mybook"
key = 'python'
source_url='http://search.dangdang.com/'
def start_requests(self):
url = MybookSpider.source_url+"?key="+MybookSpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookkItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
# link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
#if link:
# url = response.urljoin(link)
# yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
(2)结果图片:
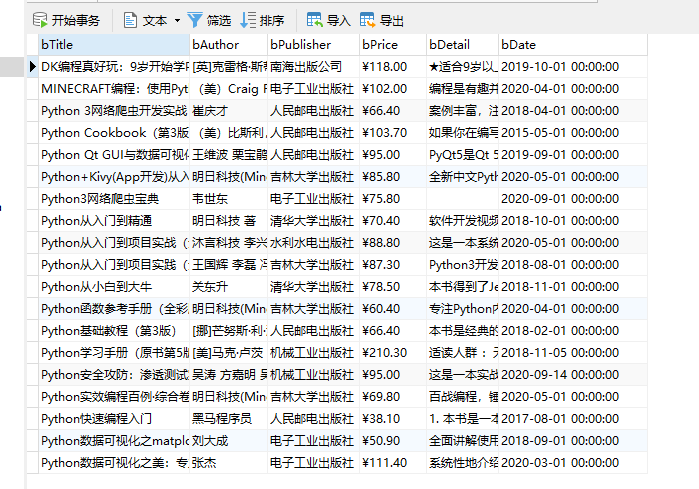
(3)心得体会:
安装Navicat没有破解,只能先免费试用14天。安装Mysql安装了两次,第一次不知道怎么没成功,后来按着教程,卸载干净再安装一次,就成功了。 有时候安装软件很长时间没安装成功就挺打击信心的。 照着书本的流程运行一遍代码,感觉理清了思路。作业二
作业②要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55
2......
(1)各个步骤及代码:
1、编写spider
import scrapy
import json
from ..items import StocksItem
class MystockSpider(scrapy.Spider):
name = 'mystock'
start_urls = ["http://75.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406817237975028352_1601466960670&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601466960895"]
#start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
# 调用body_as_unicode()是为了能处理unicode编码的数据
count = 0
result = response.text
result = result.replace('''jQuery112406817237975028352_1601466960670(''',"").replace(');','')#最外层的“);”要去掉,不然一直报错。
result = json.loads(result)
for f in result['data']['diff']:
count += 1
item = StocksItem()
item["i"] = str(count)
item["f12"] = f['f12']
item["f14"] = f['f14']
item["f2"] = f['f2']
item["f3"] = f['f3']
item["f4"] = f['f4']
item["f5"] = f['f5']
item["f6"] = f['f6']
item["f7"] = f['f7']
item["f15"] = f['f15']
item["f16"] = f['f16']
item["f17"] = f['f17']
item["f18"] = f['f18']
yield item
print("ok")
2、编写pipelines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class DemoPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='', db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
count = 0
def process_item(self, item, spider):
try:
self.count += 1
if self.opened:
self.cursor.execute(
"insert into stocks (No, Code, Name, Latest, RF, FR, Volume, Turnover, Increase,High,Low,Open,Close) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(str(self.count), item['f12'], item['f14'], str(item['f2']), str(item['f3'])+"%", str(item['f4']),
str(item['f5']), str(item['f6']), str(item['f7'])+"%",str(item['f15']), str(item['f16']), str(item['f17']),str(item['f18'])))
except Exception as err:
print(err)
return item
3、设置settings
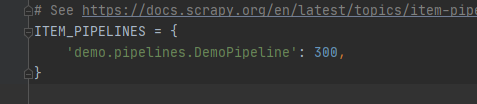
(2)结果图片:
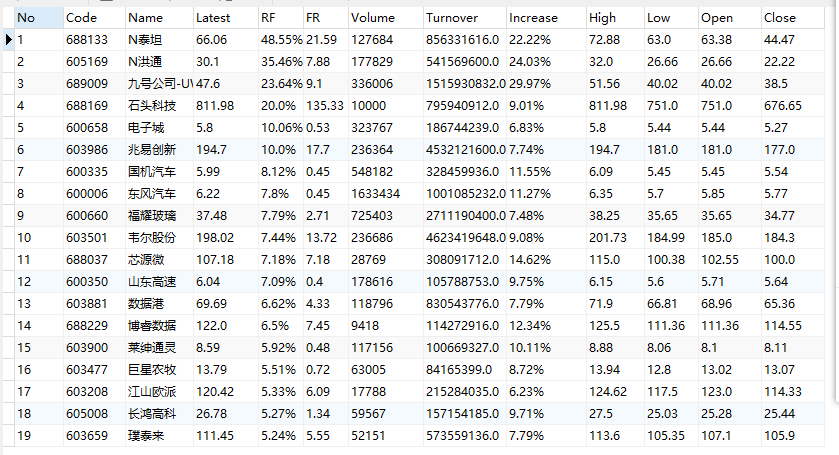
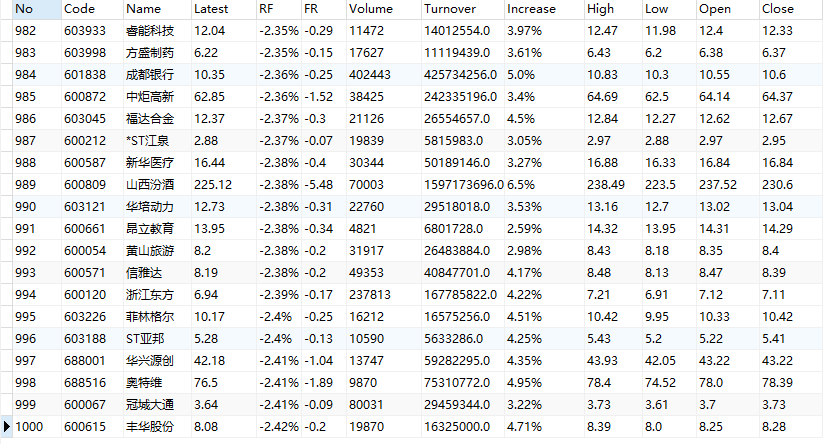
(3)心得体会:
这次作业还是在上次的股票基础上稍加改造,将数据写入数据库的应用的操作也是在课本上的代码稍加改变。大体的框架都有,自己只是改了点东西,就能完成这次作业。作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:招商银行网:http://fx.cmbchina.com/hq/
输出信息:MYSQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time
1 港币 86.60 86.60 86.26 85.65 15:36:30
2......
(1)代码如下:
1、编写items
import scrapy
class currencyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
2、编写spider
import scrapy
from ..items import currencyItem
from bs4 import UnicodeDammit
class MycurrencySpider(scrapy.Spider):
name = 'mycurrency'
start_urls = ['http://fx.cmbchina.com/hq/']
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
# 获取外汇信息
data = selector.xpath("//div[@id='realRateInfo']/table/tr")
for tr in data[1:]:
currency = tr.xpath("./td[@class='fontbold'][position()=1]/text()").extract_first()
tsp = tr.xpath("./td[@class='numberright'][position()=1]/text()").extract_first()
csp = tr.xpath("./td[@class='numberright'][position()=2]/text()").extract_first()
tbp = tr.xpath("./td[@class='numberright'][position()=3]/text()").extract_first()
cbp = tr.xpath("./td[@class='numberright'][position()=4]/text()").extract_first()
time = tr.xpath("./td[@align='center'][position()=3]/text()").extract_first()
item = currencyItem()
item["Currency"] = currency.strip() if currency else ""
item["TSP"] = tsp.strip() if tsp else ""
item["CSP"] = csp.strip() if csp else ""
item["TBP"] = tbp.strip() if tbp else ""
item["CBP"] = cbp.strip() if cbp else ""
item["Time"] = time.strip() if time else ""
yield item
except Exception as err:
print(err)
3、编写pipelines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
class CurrencyPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from mycurrency")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
print(self.count)
print(item["Currency"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["Time"])
print()
if self.opened:
self.cursor.execute(
"insert into mycurrency (ID,Currency,TSP,CSP,TBP,CBP,Time) values(%d,%s,%s,%s,%s,%s,%s)",
(self.count,item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
self.count += 1
except Exception as err:
print(err)
return item
4、设置settings

(2)结果图片:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号