数据采集第三次作业
作业一
作业①:1、要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
2、输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(1)代码如下:
# -*- coding = utf-8 -*-
# @Time:2020/10/13 18:36
# @Author:CaoLanying
# @File:the_third_project1.py
# @Software:PyCharm
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import os
#图像爬取
def imageSpider(start_url):
global threads
global count #计数
try:
urls=[]
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read() #套路
dammit = UnicodeDammit(data,["utf-8","gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"html.parser")
images = soup.select("img") #获取图像标签
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
#print(url) #爬取的图片地址
count = count+1
T = threading.Thread(target=download,args=(url,count)) #线程个数
T.setDaemon(False) #非守护线程
T.start()
threads.append(T) #把线程加入到线程数组
except Exception as err:
print(err)
except Exception as err: \
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext = url[len(url)-4:] #ext是个“.”
else:
ext=""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
fobj = open("D:\\pythonProject\\Wulin'course\\images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
#start_url="http://www.weather.com.cn/weather/101280601.shtml"
#start_url="http://www.sziit.edu.cn"
start_url="http://xcb.fzu.edu.cn/#"
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
(2)结果图片:
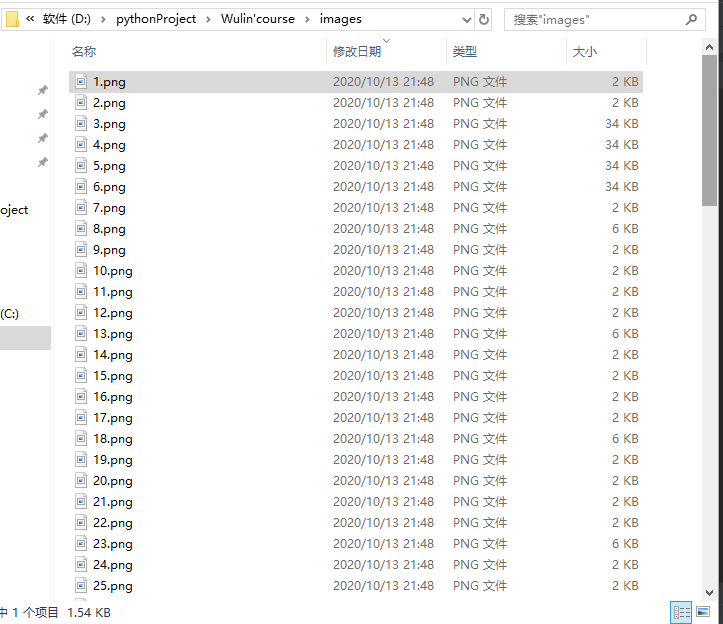
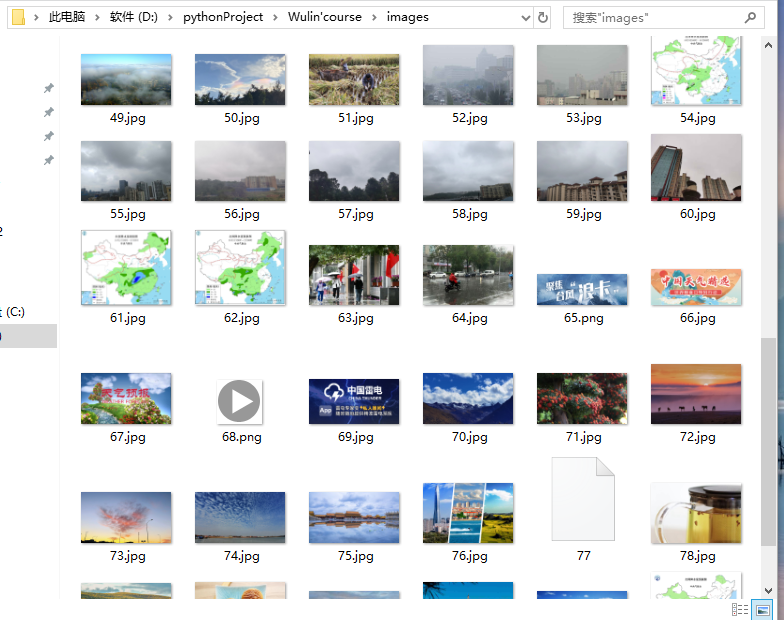
(3)心得体会:
1、遇到的问题:
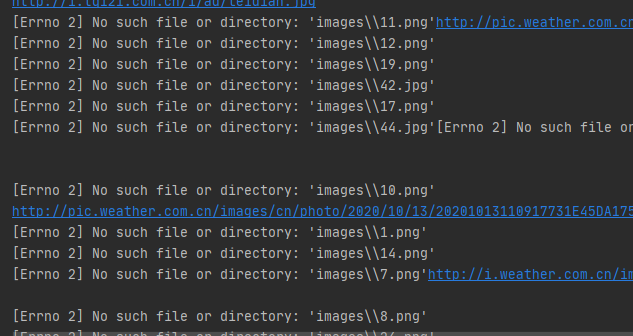
2、解决方法:
路径没写对,于是换成了绝对路径 fobj = open("D:\pythonProject\Wulin'course\images\" + str(count) + ext, "wb")
作业二
要求:使用scrapy框架复现作业①。输出信息:同作业①
(1)各个步骤及代码:

1、编写spider
import scrapy
from ..items import GetimagItem
class WeatherSpider(scrapy.Spider):
name = 'weather'
allowed_domains = ['p.weather.com']
start_urls = ['http://p.weather.com.cn/']
def parse(self, response):
img_url_list = response.xpath('//img/@src')
for url in img_url_list.extract():
item = GetimagItem()
item["url"] = url
print(url)
yield item
print("ok")
2、编写pipelines
# Define your item pipelines here
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import urllib
class GetimagPipeline(object):
count = 0 # process_item调用的次数
def process_item(self,item,spider):
GetimagPipeline.count += 1
try:
url = item["url"] #获得url地址
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:] # ext是个“.”
else:
ext = ""
req = urllib.request.Request(url)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:\\pythonProject\\Wulin'course\\images2\\" + str(GetimagPipeline.count) + ext, "wb") # 打开一个文件,这个
fobj.write(data) # 写入数据
fobj.close() # 关闭文件
print("downloaded " + str(GetimagPipeline.count) + ext)
except Exception as err:
print(err)
return item
3、设置settings
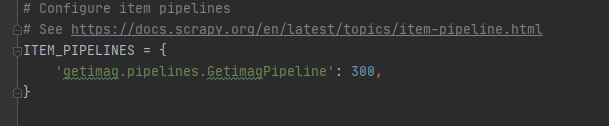
(2)结果图片:
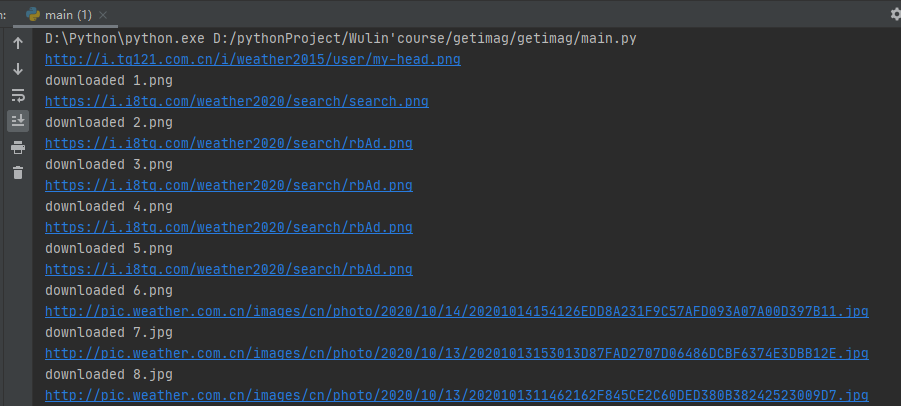
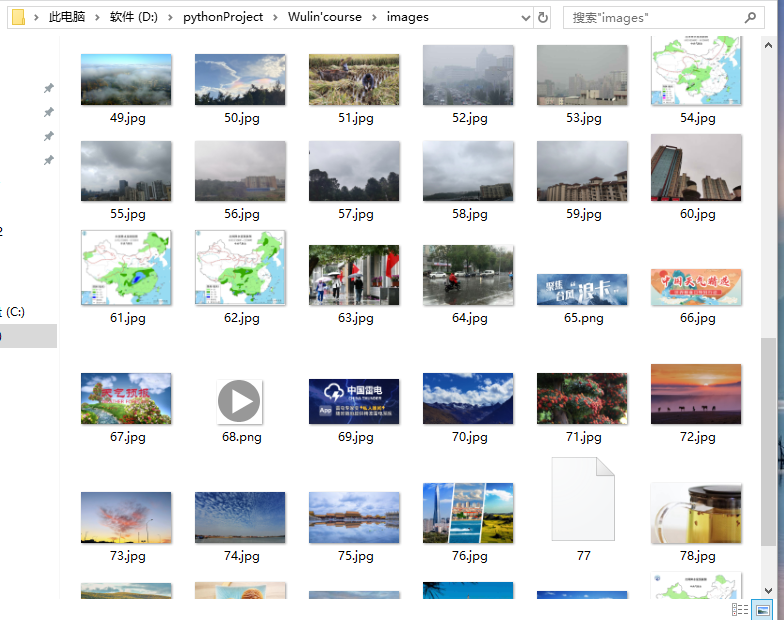
(3)心得体会:
了解到Scrapy框架是一个快速、高层次的基于Python的web爬虫框架,抓取web站点并从页面提取结构化数据。hhhh,但是第一次用的时候就是一头雾水,不知道应该在什么模块下写代码,仔细看看书上的例子之后,就有了一丝丝的灵感。更了解流程和各个框架之间的关系后就感觉编程起来很方便。为什么要使用Scrapy框架呢?因为它更容易构建大规模抓取项目;异步处理请求的速度快,且使用自动调节机制自动调整爬取速度。总之一句话,scrapy就是很强大!!
作业三
要求:使用scrapy框架爬取股票相关信息。候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55
2......
(1)代码如下:
总的框架:
1、编写items
# Define here the models for your scraped items
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
i = scrapy.Field()
f12 = scrapy.Field()
f14 = scrapy.Field()
f2 = scrapy.Field()
f3 = scrapy.Field()
f4 = scrapy.Field()
f5 = scrapy.Field()
f6 = scrapy.Field()
f7 = scrapy.Field()
pass
2、编写spider
import scrapy
import json
from ..items import StocksItem
class MystockSpider(scrapy.Spider):
name = 'mystock'
start_urls = ["http://75.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406817237975028352_1601466960670&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601466960895"]
#start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
# 调用body_as_unicode()是为了能处理unicode编码的数据
count = 0
result = response.text
result = result.replace('''jQuery112406817237975028352_1601466960670(''',"").replace(');','')#气死我了,最外层的“);”要去掉,不然一直报错。搞了好久
result = json.loads(result)
for f in result['data']['diff']:
count += 1
item = StocksItem()
item["i"] = str(count)
item["f12"] = f['f12']
item["f14"] = f['f14']
item["f2"] = f['f2']
item["f3"] = f['f3']
item["f4"] = f['f4']
item["f5"] = f['f5']
item["f6"] = f['f6']
item["f7"] = f['f7']
yield item
print("ok")
3、编写pipelines
# Define your item pipelines here
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from openpyxl import Workbook
class StocksPipeline(object):
wb = Workbook()
ws = wb.active # 激活工作表
ws.append(["序号","代码","名称","最新价(元)","涨跌幅","跌涨额(元)", "成交量","成交额(元)","涨幅"])
def process_item(self, item, spider):
line = [item['i'], item['f12'], item['f14'], item['f2'], item['f3'],item['f4'],item['f5'], item['f6'],item['f7']] # 把数据中每一项整理出来
self.ws.append(line) # 将数据以行的形式添加到xlsx中
self.wb.save(r'C:\Users\Administrator\Desktop\stock.xlsx') # 保存xlsx文件
return item
4、设置settings

(2)结果图片:
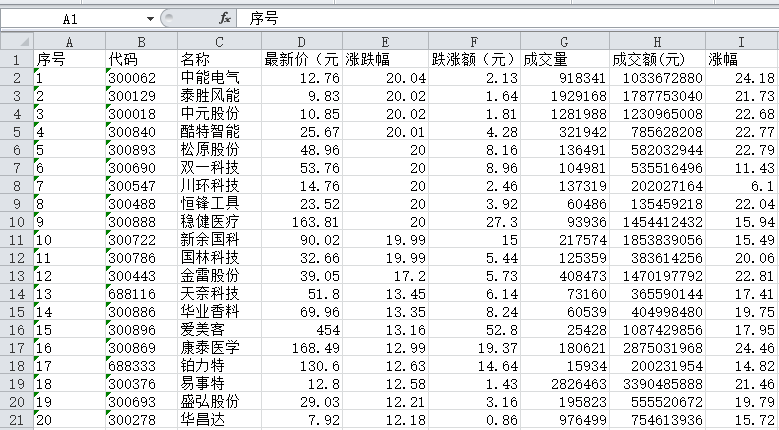
(3)心得体会:
**
有了第二个实验的经验,第三个作业就没那么难了。之前听老师说数据输出要漂亮一点,于是我就去看了,怎么把数据存在Excel表格里面,发现非常方便,而且也很实用。
主要用到了Scrapy的pipeline.py和python的开源库OpenPyxl。以后再试试其他存储方法。
**
1、遇到的问题:
舍友说,他的答案一直显示不出来在屏幕上,弄了好久。
我一开始也没注意这个问题,想到可能以后会遇到,先记录一下。
2、解决方法:
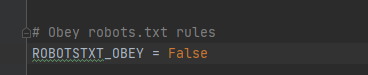
这个设置为ture
附加上srapy怎么使用Excel的方法:
关于pipeline
pipeline是scrapy中一个模块,数据被spider抓取之后会由pipeline处理。pipeline中通常会有几个“工序”,数据会按照顺序通过这几个“工序”。如果没有通过某项“工序”,会被抛弃掉。 **
pipeline一般有几种用途:
2. 确认已抓取数据(比如确认是否包含特定字段)
3.检查重复(过滤重复数据)
4.保存已抓取数据入数据库
我们在这里用到的是最后一个功能,只是保存为xlsx文件。
关于OpenPyxl
OpenPyxl是读写 Excel 2007 xlsx/xlsm文件的python库。废话不多说,直接上例子:
from openpyxl import Workbook
wb = Workbook() # class实例化
ws = wb.active # 激活工作表
ws['A1'] = 42 # A1表格输入数据
ws.append(['科比', '1997年', '后卫', '赛季报销']) # 添加一行数据
wb.save('/home/alexkh/nba.xlsx') # 保存文件
Scrapy保存为excel
Scrapy数据保存为excel就是在pipeline.py中处理。具体代码如下:
#coding=utf-8
from openpyxl import Workbook
class TuniuPipeline(object): # 设置工序一
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['新闻标题', '新闻链接', '来源网站', '发布时间', '相似新闻', '是否含有网站名']) # 设置表头
def process_item(self, item, spider): # 工序具体内容
line = [item['title'], item['link'], item['source'], item['pub_date'], item['similar'], item['in_title']] # 把数据中每一项整理出来
self.ws.append(line) # 将数据以行的形式添加到xlsx中
self.wb.save('/home/alexkh/tuniu.xlsx') # 保存xlsx文件
return item
为了让pipeline.py生效,还需要在settings.py文件中增加设置,内容如下:
ITEM_PIPELINES = {
'tuniunews.pipelines.TuniuPipeline': 200, # 200是为了设置工序顺序
}
参考资料
- Scrapy文档中关于Item Pipeline的部分
2.OpenPyxl官方文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号