第一次作业——结合三次小作业
作业1
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2......
(1)代码如下:
# -*- coding = utf-8 -*-
# @Time:2020/9/18 20:25
# @Author:CaoLanying
# @File:171809061曹兰英UniversitiesRanking.py
# @Software:PyCharm
import urllib.request
from bs4 import BeautifulSoup
def askURL(url):
# 模拟浏览器头部,向服务器请求
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
# 用户代理表示:告诉服务器我们是什么类型的机器,本质上告诉服务器,我们可以接受什么水平的信息
request = urllib.request.Request(url, headers=head) #添加头部信息
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html) #打印
except urllib.error.URLErrr as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def print(html):
soup = BeautifulSoup(html, "html.parser")
print("排名\t学校名称\t省市\t学校类型\t总分")
for tr in soup.find('tbody').children:
r = tr.find_all("td")
print(r[0].text.strip()+"\t"+r[1].text.strip()+"\t"+r[2].text.strip()+" "+r[3].text.strip()+" "+r[4].text.strip())
if __name__ == '__main__':
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=askURL(url)
print(html)
(2)结果图片:
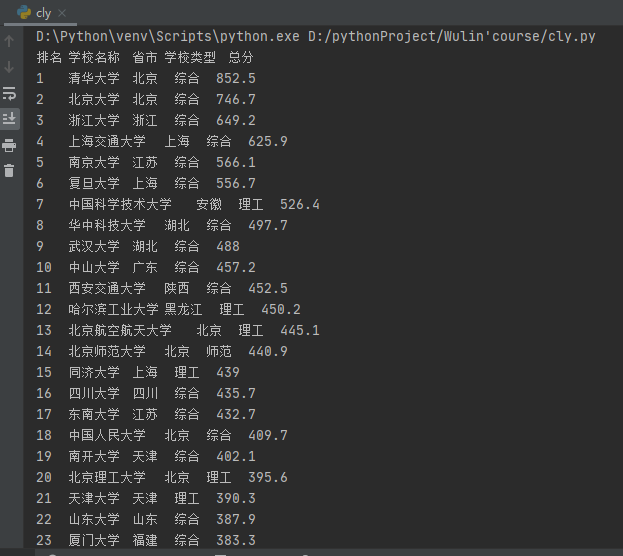
(3)心得体会:这是第一次爬虫作业,刚开始不知道怎么解决问题。发现网站变了,本来之前的网站标签比较有规律,写起来更简单。后来的网站就没啥规律,于是看了看同学怎么弄得。然后就明白了。红红火火恍恍惚惚
作业2
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
序号 价格 商品名
1 65.00 xxx
2......
(1)代码如下:
# -*- coding = utf-8 -*-
# @Time:2020/9/19 14:02
# @Author:CaoLanying
# @File:171809061曹兰英GoodsPrices.py
# @Software:PyCharm
import urllib.request
from bs4 import BeautifulSoup
import re
def main():
getData("http://search.dangdang.com/?key=%E4%B9%A6%E5%8C%85&act=input")
def askURL(url):
# 模拟浏览器头部,向服务器请求
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
# 用户代理表示:告诉服务器我们是什么类型的机器,本质上告诉服务器,我们可以接受什么水平的信息
request = urllib.request.Request(url, headers=head) #添加头部信息
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('gbk') #当当网用的是gbk的编码
#print(html) #打印
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 爬取网页
def getData(baseurl):
datalist = []
dataName = []
for i in range(1,3): #爬取页数为1-2页
url = baseurl + "&page_index=" +str(i)
html = askURL(url) # 保存获取到的网页源码
# 2 逐一解析数据
soup = BeautifulSoup(html,"html.parser")
# print(soup.prettify())
for items in soup.find_all('p',attrs={"class":"name","name":"title"}):
names = items.find_all('a')
for name in names:
title = name["title"]
#print(title) #取出书包名字
dataName.append(title)
#print(dataName)
for items in soup.find_all('span', attrs={"class": "price_n"}): #价格
datalist.append(items.string)
print("\n")
print("-------这是第%d页--------"%i)
print("商品名称\t","商品价格\t")
for i in range(0,len(datalist)-1):
print(dataName[i]+"\t"+datalist[i])
if __name__ == "__main__":
main()
(2)结果图片:
**
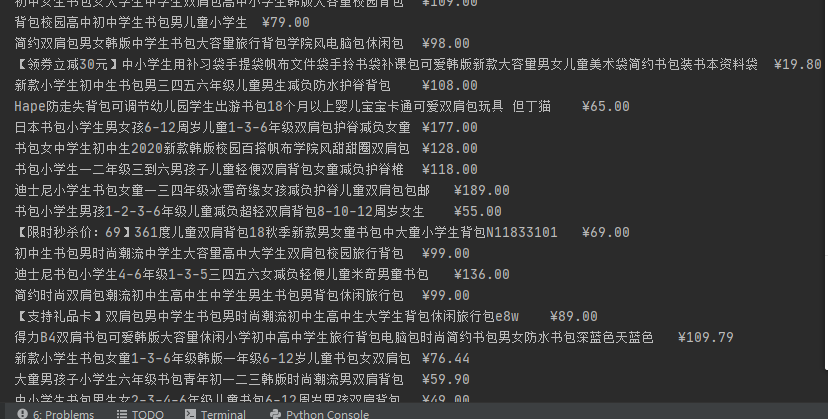

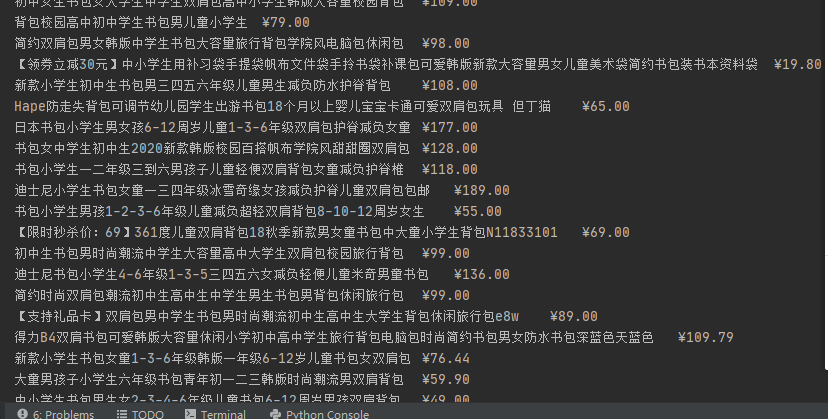
(3)心得体会:这是第二次爬虫作业,我觉得这次作业比较简单,除了要解决反爬问题,及加一个头部信息之外。网站的标签很有规律,比较好弄。分页啥的,也学会了,就是在原有url上加一个东西。
**
作业3
要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
(1)代码如下:
# -*- coding = utf-8 -*-
# @Time:2020/9/19 18:41
# @Author:CaoLanying
# @File:171809061曹兰英JPGFileDownload.py
# @Software:PyCharm
import urllib.request
from bs4 import BeautifulSoup
import re
findJpg = re.compile(r'(.*.jpg)')
def main():
getData("http://xcb.fzu.edu.cn/#")
def askURL(url):
# 模拟浏览器头部,向服务器请求
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
# 用户代理表示:告诉服务器我们是什么类型的机器,本质上告诉服务器,我们可以接受什么水平的信息
request = urllib.request.Request(url, headers=head) #添加头部信息
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8') #当当网用的是gbk的编码
#print(html) #打印
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def getData(url):
data = []
html = askURL(url)
soup = BeautifulSoup(html, "html.parser")
jpg = soup.find_all('img')
for a in jpg:
src = a['src']
# print(type(src))# 字符串类型
# print(src)
a = re.findall(findJpg,src)
if len(a)>0:
data.append(a)
count = 0
print("福大党委宣传部网站jpg图片")
for img in data:
#print(img)
a = "http://xcb.fzu.edu.cn"+"".join(img)
print(a)
'''
for item in soup.find_all("img"):
#print(item)
item = str(item)
jpg = re.findall(findJpg,item)
print(jpg)
'''
main()
(2)结果图片:

(3)心得体会:这是第三次爬虫作业。遇到问题就是,刚开始时下载的文件都是相对路径的,这一点是比较困扰我的。后来就用字符串的.join()变成了绝对路径,问题就解决了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号