
memcached完全剖析系列教程《转》memcached完全剖析系列教程–4.memcached的分布式算法
本文目录
· 根据余数计算分散
· 总结
memcached的分布式
正如第1次中介绍的那样, memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。服务器端仅包括 第2次、 第3次 前坂介绍的内存存储功能,其实现非常简单。至于memcached的分布式,则是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
memcached的分布式是什么意思?
这里多次使用了“分布式”这个词,但并未做详细解释。现在开始简单地介绍一下其原理,各个客户端的实现基本相同。
下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。
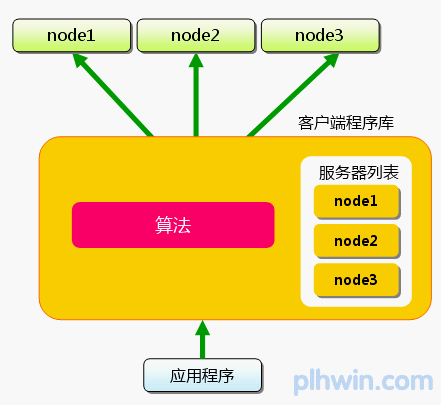
图1 分布式简介:准备
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
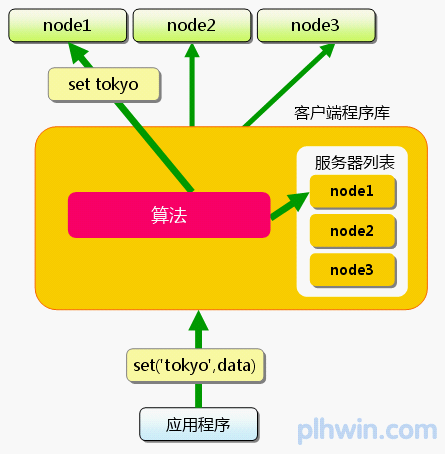
图2 分布式简介:添加时
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存
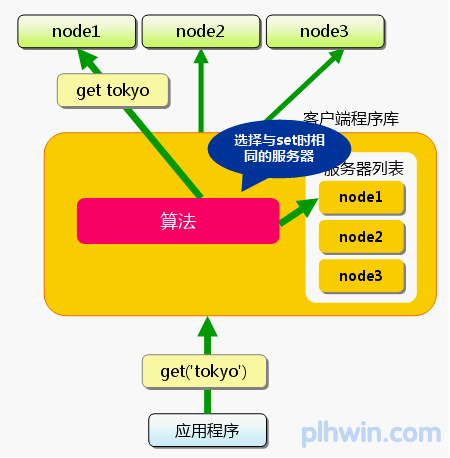
图3 分布式简介:获取时
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
接下来介绍第1次中提到的Perl客户端函数库Cache::Memcached实现的分布式方法。
Cache::Memcached的分布式方法
Perl的memcached客户端函数库Cache::Memcached是 memcached的作者Brad Fitzpatrick的作品,可以说是原装的函数库
Cache::Memcached – search.cpan.org
该函数库实现了分布式功能,是memcached标准的分布式方法。
根据余数计算分散
Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
下面将Cache::Memcached简化成以下的Perl脚本来进行说明。
use strict; use warnings; use String::CRC32; my @nodes = ('node1','node2','node3'); my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma'); foreach my $key (@keys) { my $crc = crc32($key); # CRC値 my $mod = $crc % ( $#nodes + 1 ); my $server = $nodes[ $mod ]; # 根据余数选择服务器 printf "%s => %sn", $key, $server; }
Cache::Memcached在求哈希值时使用了CRC。
String::CRC32 – search.cpan.org
首先求得字符串的CRC值,根据该值除以服务器节点数目得到的余数决定服务器。上面的代码执行后输入以下结果:
tokyo => node2 kanagawa => node3 chiba => node2 saitama => node1 gunma => node1
根据该结果,“tokyo”分散到node2,“kanagawa”分散到node3等。多说一句,当选择的服务器无法连接时,Cache::Memcached会将连接次数添加到键之后,再次计算哈希值并尝试连接。这个动作称为rehash。不希望rehash时可以在生成Cache::Memcached对象时指定“rehash => 0”选项。
根据余数计算分散的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。用Perl写段代码来验证其代价。
use strict; use warnings; use String::CRC32; my @nodes = @ARGV; my @keys = ('a'..'z'); my %nodes; foreach my $key ( @keys ) { my $hash = crc32($key); my $mod = $hash % ( $#nodes + 1 ); my $server = $nodes[ $mod ]; push @{ $nodes{ $server } }, $key; } foreach my $node ( sort keys %nodes ) { printf "%s: %sn", $node, join ",", @{ $nodes{$node} }; }
这段Perl脚本演示了将“a”到“z”的键保存到memcached并访问的情况。将其保存为mod.pl并执行。
首先,当服务器只有三台时:
$ mod.pl node1 node2 nod3
node1: a,c,d,e,h,j,n,u,w,x
node2: g,i,k,l,p,r,s,y
node3: b,f,m,o,q,t,v,z
结果如上,node1保存a、c、d、e……,node2保存g、i、k……,每台服务器都保存了8个到10个数据。
接下来增加一台memcached服务器。
$ mod.pl node1 node2 node3 node4
node1: d,f,m,o,t,v
node2: b,i,k,p,r,y
node3: e,g,l,n,u,w
node4: a,c,h,j,q,s,x,z
添加了node4。可见,只有d、i、k、p、r、y命中了。像这样,添加节点后键分散到的服务器会发生巨大变化。26个键中只有六个在访问原来的服务器,其他的全都移到了其他服务器。命中率降低到23%。在Web应用程序中使用memcached时,在添加memcached服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上,有可能会发生无法提供正常服务的情况。
mixi的Web应用程序运用中也有这个问题,导致无法添加memcached服务器。但由于使用了新的分布式方法,现在可以轻而易举地添加memcached服务器了。这种分布式方法称为 Consistent Hashing。
Consistent Hashing
关于Consistent Hashing的思想,mixi株式会社的开发blog等许多地方都介绍过,这里只简单地说明一下。
mixi Engineers’ Blog – スマートな分散で快適キャッシュライフ
ConsistentHashing – コンシステント ハッシュ法
Consistent Hashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
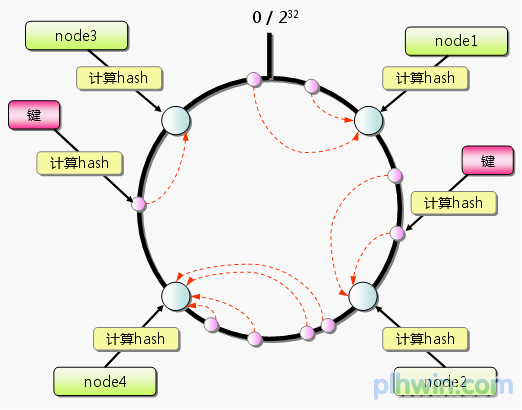
图4 Consistent Hashing:基本原理
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
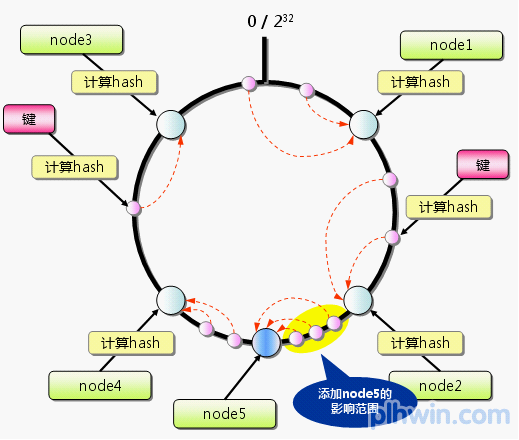
图5 Consistent Hashing:添加服务器
因此,Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 – n/(n+m)) * 100
支持Consistent Hashing的函数库
本连载中多次介绍的Cache::Memcached虽然不支持Consistent Hashing,但已有几个客户端函数库支持了这种新的分布式算法。第一个支持Consistent Hashing和虚拟节点的memcached客户端函数库是名为libketama的PHP库,由last.fm开发。
libketama – a consistent hashing algo for memcache clients – RJ ブログ – Users at Last.fm
至于Perl客户端,连载的第1次 中介绍过的Cache::Memcached::Fast和Cache::Memcached::libmemcached支持 Consistent Hashing。
· Cache::Memcached::Fast – search.cpan.org
· Cache::Memcached::libmemcached – search.cpan.org
两者的接口都与Cache::Memcached几乎相同,如果正在使用Cache::Memcached,那么就可以方便地替换过来。Cache::Memcached::Fast重新实现了libketama,使用Consistent Hashing创建对象时可以指定ketama_points选项。
my $memcached = Cache::Memcached::Fast->new({ servers => ["192.168.0.1:11211","192.168.0.2:11211"], ketama_points => 150 });
另外,Cache::Memcached::libmemcached 是一个使用了Brain Aker开发的C函数库libmemcached的Perl模块。 libmemcached本身支持几种分布式算法,也支持Consistent Hashing,其Perl绑定也支持Consistent Hashing。
· Tangent Software: libmemcached
总结
本次介绍了memcached的分布式算法,主要有memcached的分布式是由客户端函数库实现,以及高效率地分散数据的Consistent Hashing算法。下次将介绍mixi在memcached应用方面的一些经验,和相关的兼容应用程序
memcached完全剖析系列教程–5.memcached的应用和兼容程序
[ 2010-01-07 22:29 by plhwin | 访问:5,189次 | 查看评论
发表评论 ]
memcached的连载终于要结束了。到上次为止,我们介绍了与memcached直接相关的话题,本次介绍一些mixi的案例和实际应用上的话题,并介绍一些与memcached兼容的程序。
本文目录
· 服务器配置和数量
通过Cache::Memcached::Fast维持连接
公共数据的处理和rehash
· 监视
· 总结
mixi案例研究
mixi在提供服务的初期阶段就使用了memcached。随着网站访问量的急剧增加,单纯为数据库添加slave已无法满足需要,因此引入了memcached。此外,我们也从增加可扩展性的方面进行了验证,证明了memcached的速度和稳定性都能满足需要。现在,memcached已成为mixi服务中非常重要的组成部分。
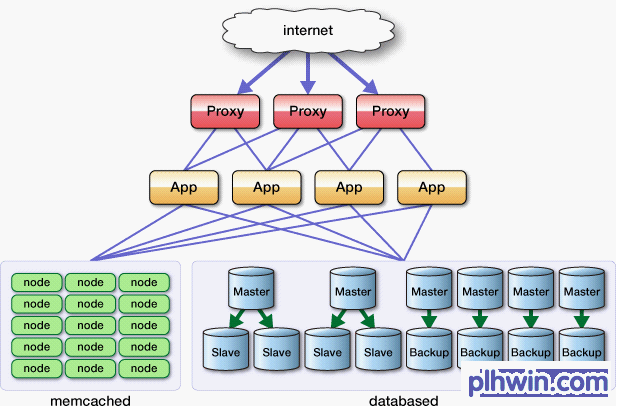
图1 现在的系统组件
服务器配置和数量
mixi使用了许许多多服务器,如数据库服务器、应用服务器、图片服务器、反向代理服务器等。单单memcached就有将近200台服务器在运行。 memcached服务器的典型配置如下:
· CPU:Intel Pentium 4 2.8GHz
· 内存:4GB
· 硬盘:146GB SCSI
· 操作系统:Linux(x86_64)
这些服务器以前曾用于数据库服务器等。随着CPU性能提升、内存价格下降,我们积极地将数据库服务器、应用服务器等换成了性能更强大、内存更多的服务器。这样,可以抑制mixi整体使用的服务器数量的急剧增加,降低管理成本。由于memcached服务器几乎不占用CPU,就将换下来的服务器用作memcached服务器了。
memcached进程
每台memcached服务器仅启动一个memcached进程。分配给memcached的内存为3GB,启动参数如下:
/usr/bin/memcached -p 11211 -u nobody -m 3000 -c 30720
由于使用了x86_64的操作系统,因此能分配2GB以上的内存。32位操作系统中,每个进程最多只能使用2GB内存。也曾经考虑过启动多个分配2GB以下内存的进程,但这样一台服务器上的TCP连接数就会成倍增加,管理上也变得复杂,所以mixi就统一使用了64位操作系统。
另外,虽然服务器的内存为4GB,却仅分配了3GB,是因为内存分配量超过这个值,就有可能导致内存交换(swap)。连载的第2次中前坂讲解过了memcached的内存存储“slab allocator”,当时说过,memcached启动时指定的内存分配量是memcached用于保存数据的量,没有包括“slab allocator”本身占用的内存、以及为了保存数据而设置的管理空间。因此,memcached进程的实际内存分配量要比指定的容量要大,这一点应当注意。
mixi保存在memcached中的数据大部分都比较小。这样,进程的大小要比指定的容量大很多。因此,我们反复改变内存分配量进行验证,确认了3GB的大小不会引发swap,这就是现在应用的数值。
memcached使用方法和客户端
现在,mixi的服务将200台左右的memcached服务器作为一个pool使用。每台服务器的容量为3GB,那么全体就有了将近600GB的巨大的内存数据库。客户端程序库使用了本连载中多次提到车的Cache::Memcached::Fast,与服务器进行交互。当然,缓存的分布式算法使用的是 第4次介绍过的 Consistent Hashing算法。
· Cache::Memcached::Fast – search.cpan.org
应用层上memcached的使用方法由开发应用程序的工程师自行决定并实现。但是,为了防止车轮再造、防止Cache::Memcached::Fast上的教训再次发生,我们提供了Cache::Memcached::Fast的wrap模块并使用。
通过Cache::Memcached::Fast维持连接
Cache::Memcached的情况下,与memcached的连接(文件句柄)保存在Cache::Memcached包内的类变量中。在mod_perl和FastCGI等环境下,包内的变量不会像CGI那样随时重新启动,而是在进程中一直保持。其结果就是不会断开与memcached的连接,减少了TCP连接建立时的开销,同时也能防止短时间内反复进行TCP连接、断开而导致的TCP端口资源枯竭。
但是,Cache::Memcached::Fast没有这个功能,所以需要在模块之外将Cache::Memcached::Fast对象保持在类变量中,以保证持久连接。
package Gihyo::Memcached; use strict; use warnings; use Cache::Memcached::Fast; my @server_list = qw/192.168.1.1:11211 192.168.1.1:11211/; my $fast; ## 用于保持对象 sub new { my $self = bless {}, shift; if ( !$fast ) { $fast = Cache::Memcached::Fast->new({ servers => @server_list }); } $self->{_fast} = $fast; return $self; } sub get { my $self = shift; $self->{_fast}->get(@_); }
上面的例子中,Cache::Memcached::Fast对象保存到类变量$fast中。
公共数据的处理和rehash
诸如mixi的主页上的新闻这样的所有用户共享的缓存数据、设置信息等数据,会占用许多页,访问次数也非常多。在这种条件下,访问很容易集中到某台memcached服务器上。访问集中本身并不是问题,但是一旦访问集中的那台服务器发生故障导致memcached无法连接,就会产生巨大的问题。
连载的第4次 中提到,Cache::Memcached拥有rehash功能,即在无法连接保存数据的服务器的情况下,会再次计算hash值,连接其他的服务器。
但是,Cache::Memcached::Fast没有这个功能。不过,它能够在连接服务器失败时,短时间内不再连接该服务器的功能。
my $fast = Cache::Memcached::Fast->new({ max_failures => 3, failure_timeout => 1 });
在failure_timeout秒内发生max_failures以上次连接失败,就不再连接该memcached服务器。我们的设置是1秒钟3次以上。
此外,mixi还为所有用户共享的缓存数据的键名设置命名规则,符合命名规则的数据会自动保存到多台memcached服务器中,取得时从中仅选取一台服务器。创建该函数库后,就可以使memcached服务器故障不再产生其他影响。
memcached应用经验
到此为止介绍了memcached内部构造和函数库,接下来介绍一些其他的应用经验。
通过daemontools启动
通常情况下memcached运行得相当稳定,但mixi现在使用的最新版1.2.5 曾经发生过几次memcached进程死掉的情况。架构上保证了即使有几台memcached故障也不会影响服务,不过对于memcached进程死掉的服务器,只要重新启动memcached,就可以正常运行,所以采用了监视memcached进程并自动启动的方法。于是使用了daemontools。
daemontools是qmail的作者DJB开发的UNIX服务管理工具集,其中名为supervise的程序可用于服务启动、停止的服务重启等。
这里不介绍daemontools的安装了。mixi使用了以下的run脚本来启动memcached。
#!/bin/sh if [ -f /etc/sysconfig/memcached ];then ./etc/sysconfig/memcached fi exec 2>&1 exec /usr/bin/memcached -p $PORT -u $USER -m $CACHESIZE -c $MAXCONN $OPTIONS
监视
mixi使用了名为“nagios”的开源监视软件来监视memcached。
在nagios中可以简单地开发插件,可以详细地监视memcached的get、add等动作。不过mixi仅通过stats命令来确认memcached的运行状态。
define command { command_name check_memcached command_line $USER1$/check_tcp -H $HOSTADDRESS$ -p 11211 -t 5 -E -s 'statsrnquitrn' -e 'uptime' -M crit }
此外,mixi将stats目录的结果通过rrdtool转化成图形,进行性能监视,并将每天的内存使用量做成报表,通过邮件与开发者共享。
memcached的性能
连载中已介绍过,memcached的性能十分优秀。我们来看看mixi的实际案例。这里介绍的图表是服务所使用的访问最为集中的memcached服务器。
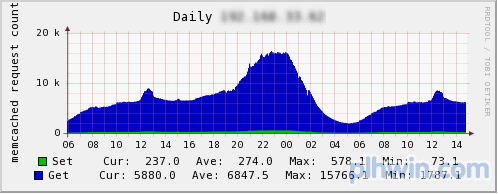
图2 请求数
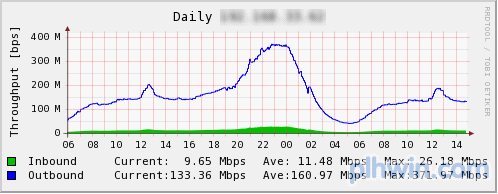
图3 流量
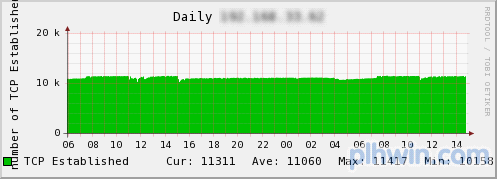
图4 TCP连接数
从上至下依次为请求数、流量和TCP连接数。请求数最大为15000qps,流量达到400Mbps,这时的连接数已超过了10000个。该服务器没有特别的硬件,就是开头介绍的普通的memcached服务器。此时的CPU利用率为:
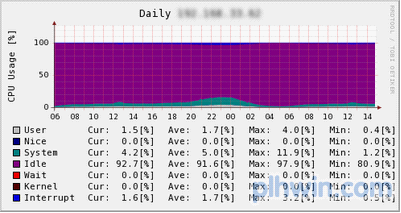
图5 CPU利用率
可见,仍然有idle的部分。因此,memcached的性能非常高,可以作为Web应用程序开发者放心地保存临时数据或缓存数据的地方。
兼容应用程序
memcached的实现和协议都十分简单,因此有很多与memcached兼容的实现。一些功能强大的扩展可以将memcached的内存数据写到磁盘上,实现数据的持久性和冗余。连载第3次 介绍过,以后的memcached的存储层将变成可扩展的(pluggable),逐渐支持这些功能。
这里介绍几个与memcached兼容的应用程序。
repcached:为memcached提供复制(replication)功能的patch。
Flared:存储到QDBM。同时实现了异步复制和fail over等功能。
memcachedb:存储到BerkleyDB。还实现了message queue。
Tokyo Tyrant:将数据存储到Tokyo Cabinet。不仅与memcached协议兼容,还能通过HTTP进行访问。
Tokyo Tyrant案例
mixi使用了上述兼容应用程序中的Tokyo Tyrant。Tokyo Tyrant是平林开发的 Tokyo Cabinet DBM的网络接口。它有自己的协议,但也拥有memcached兼容协议,也可以通过HTTP进行数据交换。Tokyo Cabinet虽然是一种将数据写到磁盘的实现,但速度相当快。
mixi并没有将Tokyo Tyrant作为缓存服务器,而是将它作为保存键值对组合的DBMS来使用。主要作为存储用户上次访问时间的数据库来使用。它与几乎所有的mixi服务都有关,每次用户访问页面时都要更新数据,因此负荷相当高。MySQL的处理十分笨重,单独使用memcached保存数据又有可能会丢失数据,所以引入了Tokyo Tyrant。但无需重新开发客户端,只需原封不动地使用Cache::Memcached::Fast即可,这也是优点之一。
关于Tokyo Tyrant的详细信息,请参考:
· mixi Engineers’ Blog – Tokyo Tyrantによる耐高負荷DBの構築
· mixi Engineers’ Blog – Tokyo (Cabinet|Tyrant)の新機能
总结
到本次为止,“memcached全面剖析”系列就结束了。我们介绍了memcached的基础、内部结构、分散算法和应用等内容。读完后如果您能对memcached产生兴趣,就是我们的荣幸。关于mixi的系统、应用方面的信息,请参考这里。感谢您的阅读。
From:
