学习Spring-Data-Jpa(二)---JPA基本注解
基本注解
1、@Entity :用于添加在实体类上,定义该JAVA类成为被JPA管理的实体,将映射到指定的数据库表。如定义一个实体类Category,它将映射到数据库中的category表中。
2、@Id :定义属性为数据库表中的主键列,一个实体里面必须有一个。
3、@Table:指定数据库的表名,与@Entity一同使用。
属性name:表的名字,如果不写,系统认为和实体类一致。
属性catalog,schema用于设置目录和此表所在schema,一般不需要填写;
属性uniqueConstraints,唯一性约束,只有创建表的时候有用,默认不需要;
属性indexes,索引,只有创建表的时候有用,默认不需要。
4、@Basic:表示属性是到数据库表字段的映射。如果实体的字段上没有任何注解,默认即为@Basic;
属性fetch,抓取方式,默认FetchType.EAGER(立即加载),FetchType.LAZY(延迟加载,主要应用在大字段上面);
属性optional,设置这个字段是否可以为null,默认是true。
5、@Transient:非持久化属性,表示该属性并非是一个到数据库表的字段的映射,与@Basic作用相反。JPA映射数据库的时候忽略它。
6、@Column:定义该属性对应数据库中的列名。
属性name,数据库中的列名。如果不写默认和实体属性名一致;
属性unique,是否唯一。默认false;
属性nullable,是否允许为空。默认为true;
属性insertable,执行insert操作的时候是否包含此字段,默认为true;
属性updatable,执行updatable操作的时候是否包含此字段,默认为true;
属性columnDefinition,表示该字段在数据库中的实际类型。
属性length,数据库字段的长度,默认255;
属性table,precision,scale,我没用到过,一般不设置。
7、@GeneratedValue:主键生成策略。
属性strategy,id的生成策略,GenerationType.TABLE,通过表产生主键,框架由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植;GenerationType.SEQUENCE,通过序列产生主键,通过@SequenceGenerator注解指定序列名,MySql不支持这种方式;GenerationType.IDENTITY,数据库id自增长,多用于MySql;GenerationType.AUTO,JPA自动选择合适的策略,默认选项。
属性generator:通过Sequence生成id,常见Orcale数据库id生成,需要配合@SequenceGenerator使用。
8、@Temporal:用来设置Date类型的属性映射到对应精度的字段。TemporalType.DATE,映射为数据库date,TemporalType.TIME映射为数据库time,TemporalType.TIMESTAMP,映射为datetime。(jdk8的话,可以使用新的时间类来替代Date)
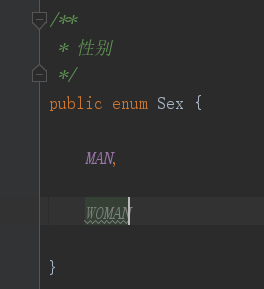
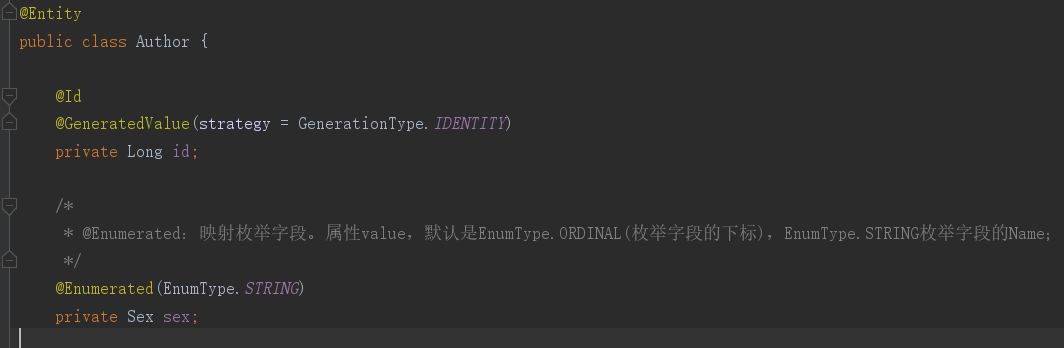
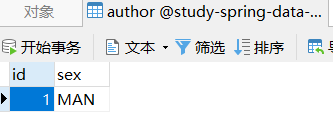
9、@Enumerated:映射枚举字段。属性value,默认是EnumType.ORDINAL(枚举字段的下标),EnumType.STRING枚举字段的Name;应用如下
10、@Lob,将属性字段映射成数据库支持的大对象类型,支持一下两种数据库类型的字段。
Clob(Character Large Objects)类型是长字符串类型,java.sql.Clob、Character[]、char[]和String将被映射成Clob类型。
Blob(Binary Large Objects)类型是字节类型,java.sql.Blob、Byte[]、byte[]和实现了Serializable接口的类型将被映射为Blob类型。
由于Clob、Blob占用内存空间较大,一般配合@Basic(fetch=FetchType.LAZY)将其设置为延迟加载。
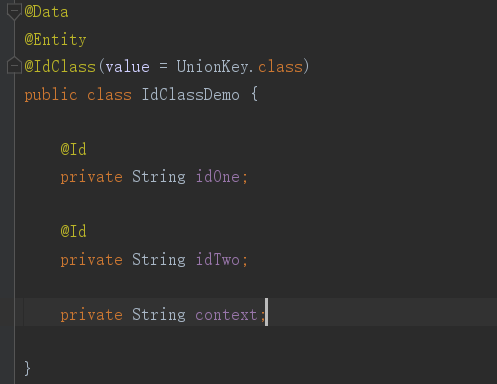
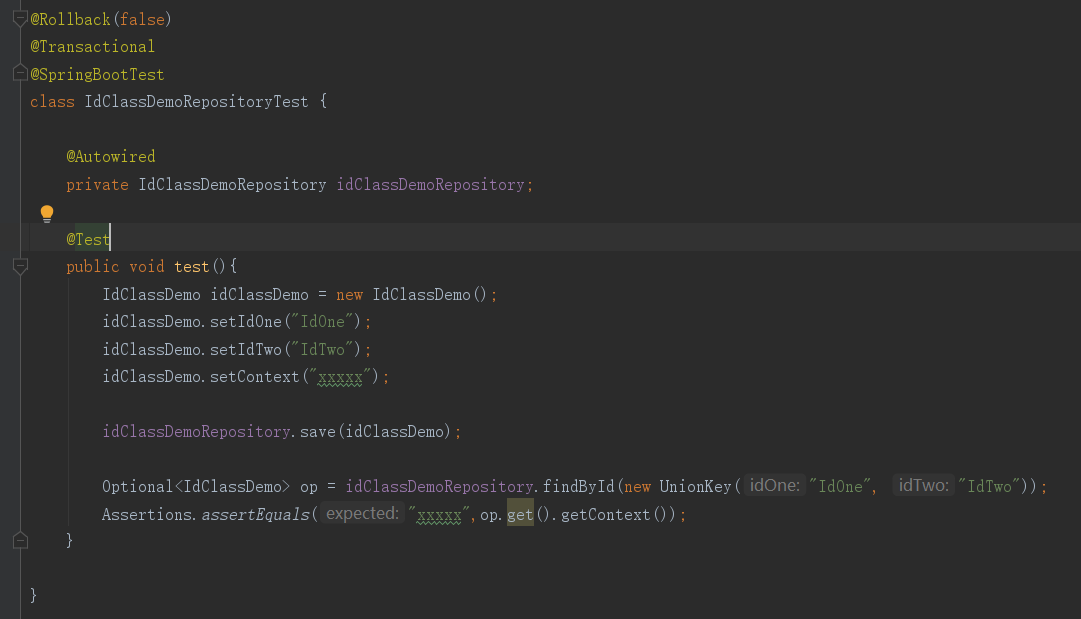
11、@IdClass:利用外部类的联合主键。
外部类要符合一下几点:必须实现java.io.Serializable接口;必须有默认的无参构造函数;必须覆盖equals和hashCode方法。

实体类要,在类上添加@IdClass并指定外部主键类,每个主键上都要添加@Id注解。
Repository接口要把主键改为外部主键类。

使用如下
源码地址:https://github.com/caofanqi/study-spring-data-jpa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号