爬虫scrapy框架入门
O、知识框架

一、初步概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
1.requests+selenium能解决90%的爬虫需求&scrapy加速
2.scrapy使用了Twisted异步网络框架,加快下载速度。Twisted学习:https://www.cnblogs.com/chenyang920/p/7923364.html异步且非阻塞。
3.视频学习:https://www.bilibili.com/video/av37438466
笔记1:scrapy框架 | 爬虫课程,
笔记2:https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/tutorial.html
4.工具使用
Xpath在线测试:https://www.toolnb.com/tools/xpath.html
在线url编码解码工具:http://www.jsons.cn/urlencode/
抓包:postman——https://www.postman.com/downloads/
sojoson.v5网页加密:https://www.sojson.com/jsjiemi.html
二、安装
1. pythonIDE安装scrapy
在anaconda的Prompt控制台直接使用pip install scrapy,遇到building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools,需要先安装Twisted框架,查找安装过程:Collecting Twisted>=13.1.0 (from scrapy)..Downloading…。记住Twisted的版本号,点击https://www.lfd.uci.edu/~gohlke/pythonlibs/这个网址下载对应的whl文件,在Prompt控制台上,进入该文件位置,利用pip install xxx命令安装该文件,再使用pip install scrapy,即可安装成功。
2.搞定Header
首先在Chrome控制台抓到的数据上点击鼠标左键→Copy→Copy as cURL。再访问https://curl.trillworks.com/,在“curl command”中将刚才拷贝的cURL粘贴进去,右边将自动生成Python代码。
3.使用Fidder抓包
https://www.cnblogs.com/zhaoyanjun/p/7068905.html
三、scrapy工作流程
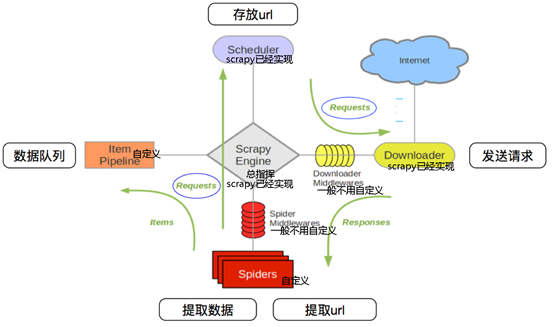
1.调度器把requests-->引擎-->下载中间件--->下载器
2.下载器发送请求,获取响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
3.爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器
4.爬虫提取数据--->引擎--->管道
5.管道进行数据的处理和保存
四、实战
1.在Anaconda Prompt控制台下切换到工作路径(xxx为自定义名字):
1)创建一个scrapy项目:scrapy startproject xxx
2)生成一个爬虫:scrapy genspider xxx xxx.com,前一个为爬虫名,后一个为允许爬取的范围。
3)在项目文件夹下面启动爬虫:scrapy crawl xxx
2.extract()与extract_first()
extract()返回一个包含有字符串的列表,extract_first() 返回列表中的第一个字符串,列表为空没有返回None。
3.Pipeline
1)setting里面将Pipeline启动,多个Pipeline权重越小优先级越高。
2)为了让数据在Pipeline中传递,要用return。
3)Pipeline中的process_item方法名不能修改为其他的名称。
4. spider中的parse方法必须有。
5. response.xpath方法的返回结果是一个类list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法。
6.yield
1)yield使得这个函数编程一个生成器。
2)yield能够传递的对象只能是:BaseItem,Request,dict,None。
3)遍历这个函数的返回值的时候,挨个把数据读到内存,不会造成内存的瞬间占用过高。
7.logging
1)若要控制台不输出日志,在setting.py中设置:LOG_LEVEL="WARNING"。保存日志只需加上LOG_FILE=xxx.txt。(也可在运行命令时附加-s LOG_FILE=xxx.txt)。
2)import logging,实例化logger的方式在任何文件中使用logger输出内容。
3)普通项目:import logging,logging.basicConfig(…)#设置日志输出的样式和格式,实例化一个logger=logging.getLogger(….namin),在其他文件中调用Logger使用。
8.翻页请求
1)找到下一页的url地址。
2)构造url地址的请求,scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False]) 注:中括号中的参数为可选参数。
callback:表示当前的url的响应交给哪个函数处理。
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,如下载延迟、请求深度等。
dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动。
method:指定POST或GET请求。
headers:接收一个字典,其中不包括cookies。
cookies:接收一个字典,专门放置cookies。
body:接收一个字典,为POST的数据。
3)传递给引擎。yield scrapy.Request(url,callback)
4)在settings中设置ROBOTS协议。
# False表示忽略网站的robots.txt协议,默认为True——ROBOTSTXT_OBEY = False
5)item
定义item即提前规划好哪些字段需要抓取,scrapy.Field()仅仅是提前占坑。在python大多数框架中,大多数框架都会自定义自己的数据类型(在python自带的数据结构基础上进行封装),目的是增加功能,增加自定义异常。
Item使用之前需要先导入并且实例化,之后的使用方法和使用字典相同
9.scrapy模拟登录
1)携带cookies直接获取需要登录后的页面:重构scrapy的starte_rquests方法(如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie);cookie不能够放在headers中,在构造请求时有专门的cookies参数,能够接受字典形式的cookie;在setting中设置ROBOTS协议、USER_AGENT
2)找到url地址,发送post请求存储cookie。
3)找到对应的form表单,自动解析input标签,自动解析post请求的url地址,自动带上数据,自动发送请求。通过scrapy.FormRequest能够发送post请求,同时需要添加formdata参数作为请求体,以及callback——scrapy.FormRequest(url,formdata={需要用户填写的键对值},…)。scrapy.FormRequest.from_response()发送表单请求,接收的是response。
10.scrapy调试
使用scrapy.shelle.inspect_response函数实现:
from scrapy.shell import inspect_response
inspect_response(response, self),
Ctrl-D(Windows下Ctrl-Z)来退出终端,恢复爬取。
11.scrapy提升框架爬取数据效率
1)增加并发线程开启数量:settings配置文件中,修改CONCURRENT_REQUESTS = 100,默认为32,可适当增加;
2)降低日志级别:运行scrapy时会产生大量日志占用CPU,为减少CPU使用率,可修改log输出级别,settings配置文件中LOG_LEVEL='ERROR' 或 LOG_LEVEL = 'INFO' 。
3)禁止cookie
scrapy默认自动保存cookie,占用CPU,如果不是真的需要cookie,可设置为不保存cookie,以减少CPU使用率,settings配置文件中:COOKIES_ENABLED = False 解开注释
4)禁止请求重试:
对于失败的请求会重新发送,则会减慢爬取速度,因此可以在对丢失少量数据也不影响时,禁止重试,settings配置文件中加:RETRY_ENABLED = False ;
5)减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以让卡住的链接快速被放弃,从而提升效率,在settings配置文件中进行编写:DOWNLOAD_TIMEOUT = 10设置超时时间;
6)禁止重定向:REDIRECT_ENABLED = FALSE
7)使用user_agent池
8)使用ip代理池
9)设置延迟:DOWNLOAD_DELAY=3,避免被发现。
10)不按照robots.txt:ROBOTSTXT_OBEY = FALSE
11)配置请求头:DEFAULT_REQUEST_HEADERS={{….}}
12.scrapy爬取JS生成的页面
1)利用第三方中间件来提供JS渲染服务:scraoy-splash等,Splash是一个javascript渲染服务。
2)利用pip安装scrapy-splash库:pip install scrapy-splash
3)安装docker:Windows10专业版安装docker
①开启Hyper-V:应用和功能——>程序和功能——>启用或关闭Windows功能——>选中Hyper-V。
②下载安装Docker Toolbox Desktop:https://www.docker.com/get-srarted注册站号并登录,下载Windows版本:Docker for Windows Installer安装文件,一路Next,点击Finish完成安装。
③镜像加速:Docker运行后,系统右下角托盘Docker图标内右键选择Settings,配置窗口左侧导航菜单选择Daemon,修改Registrymirrors为”registry-mirrors”:[“https://registry.docker-cn.com”]
④Win+r输入cmd回车,输入命令docker pull scrapinghub/splash拉取镜像
⑤输入命令:docker run -p 8050:8050 scrapinghub/splash运行scrapinghub/splash。
⑥在scrapy的settings.py中配置splash服务:
1) 添加splash服务器地址:SPLASH_URL = ‘http://localhost:8050’
2) 将splash middleware添加到DOWNLOADER_MIDDLEWARE中:
DOWNLOADER_MIDDLEWARES = {
‘scrapy_splash.SplashCookiesMiddleware’:723,
‘scrapy_splash.SplashMiddleware’:725,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’:810,
}
3)Enable SplashDeduplicateArgsMiddleware:
SPIDER_MIDDLEWARES={‘scrapy_splash.SplashDeduplicateArgsMiddleware’:100}
4)Set a custom DUPEFILTER_CLASS:
DUPEFILTER_CLASS = ‘scrapy_splash.SplashAwareDupeFilter’
5)a custom cache storage backend:
HTTPCACHE_STORAGE = ‘scrapy_splash.SplashAwareFSCacheStorage’
6)使用 scrapy_splash库中的SplashRequest进行请求爬取即可。
以上配置修改时使用Ctrl+F在代码中查找相应位置进行修改。

