01--ELK简介及安装,使用
一、ELK简介
通俗来讲,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称为 ELK stack,官方域名为 stactic.co,ELK stack 的主要优点有如下几个:
- 处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能
- 配置相对简单:elasticsearch全部使用 JSON 接口,logstash 使用模块配置,kibana 的配置文件部分更简单。
- 检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
- 集群线性扩展:elasticsearch 和 logstash 都可以灵活线性扩展 前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
ELK使用场景:
日志平台:利用elasticsearch的快速检索功能,在大量的数据当中可以快速查询需要的日志。
订单平台:利用elasticsearch的快速检索功能,在大量的订单当中检索我们所需要的订单。
搜索平台:利用elasticsearch的快速检索功能,在大量的数据中检索出我们所需要的数据。
Elasticsearch
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比如 Nginx、Tomcat、系统日志等功能。
Logstash
可以通过插件实现日志收集和转发,支持日志过滤,支持普通 log、自定义 json格式的日志解析
kibana
主要是通过接口调用 elasticsearch 的数据,并进行前端数据可视化的展现。
ELKstack部署环境的规划
| 公网ip | 主机名 | 部署服务 | 用途 |
|---|---|---|---|
| 192.168.15.51 | elkstack01 | elasticsearch、JDK | 存储日志的数据库 |
| 192.168.15.52 | elkstack02 | elasticsearch、JDK | 存储日志的数据库 |
| 192.168.15.53 | elkstack03 | Logstash、JDK | 收集日志、过滤日志 |
| 192.168.15.54 | elkstack04 | Redis、Kibana | 消息队列、日志展示 |
| 192.168.15.55 | nginx01 | nginx、filebeat | 修改nginx日志格式为json收集 |
| 192.168.15.56 | tomcat01 | tomcat、JDK、filebeat | 修改tomcat日志格式为json收集 |
安装包准备
| 安装包名 | 用途 |
|---|---|
| elasticsearch-7.12.1-x86_64.rpm | 存储日志的数据库 |
| elasticsearch-head.tar.gz | elasticsearch的web界面插件 |
| ogstash-7.12.1-x86_64.rpm | 日志收集、日志分析工具 |
| kibana-7.12.1-x86_64.rpm | 日志展示、日志查询工具 |
| filebeat-5.3.2-x86_64.rpm | 日志收集工具(比Logstash轻量) |
| jdk-8u121-linux-x64.tar.gz | JAVA容器(es、Logstash、tomcat需要) |
| nginx-1.10.3.tar.gz | 测试收集nginx日志 |
| apache-tomcat-8.0.38.tar.gz | 测试收集tomcat日志 |
| redis-3.2.8.tar.gz | 消息队列工具 |
二、ElasticSearch
一般部署elasticsearch有三种方式:
rpm包安装
源码包安装
docker安装
官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
官网其他版本安装包下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
1、rpm包安装
1)、集群规划
| 主机名 | 外网IP | 内外IP |
|---|---|---|
| es-01 | 192.168.15.51 | 172.16.1.51 |
| es-02 | 192.168.15.52 | 172.16.1.52 |
2)、集群配置
官方推荐集群配置30G。本地使用2核2G
3)、系统优化
#1.关闭selinux
[root@es-01 ~]# setenforce 0
#2.关闭防火墙
[root@es-01 ~]# systemctl disable firewalld
[root@es-02 ~]# ntpdate ntp.aliyun.com #做集群一定要同步时间
#3.设置时区
[root@es-01 ~]# timedatectl set-timezone Asia/Shanghai
#4.设置程序可以打开的文件数
[root@es-01 ~]# vim /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
#5.重启
reboot
4)、下载安装包(两台节点)
#下载epol源
[root@es-01 ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@es-01 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
[root@es-02 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
5)、安装(两台节点)
#elasticsearch是依赖于Java
[root@es-01 ~]# yum install java-1.8.0* -y
[root@es-01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
#安装elasticsearch
[root@es-01 ~]# yum install elasticsearch-7.12.1-x86_64.rpm -y
6)、elastcsearch设置内存锁定(两台节点)
[root@es-01 ~]# vim /usr/lib/systemd/system/elasticsearch.service
LimitAS=infinity
LimitMEMLOCK=infinity #在[service]层LimitAS行下边添加此行内容
[root@es-01 ~]# systemctl daemon-reload
7)、修改elasticsearch锁定内存大小
[root@es-01 ~]# vim /etc/elasticsearch/jvm.options
-Xms1g #最大锁定内存1g
-Xmx1g #最小锁定内存1g
8)、修改elasticsearch的配置文件
#1.主节点配置
[root@es-01 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es-01 ~]# grep -E '^[^#]' /etc/elasticsearch/elasticsearch.yml
# 设置集群名称
cluster.name: elk-cluster
# 设置集群节点名称(节点名称在集群中唯一)
node.name: es-node-01
# 设置数据存放目录
path.data: /var/lib/elasticsearch
# 设置日志存放目录
path.logs: /var/log/elasticsearch
#内存锁设置(在CentOS7中支持内存锁并且要修改启动脚本)
bootstrap.memory_lock: true
# 设置监听的IP
network.host: 0.0.0.0
# 设置监听的端口
http.port: 9200
# 设置主节点
cluster.initial_master_nodes: ["192.168.15.51"]
#2.从节点配置
[root@es-01 ~]# scp /etc/elasticsearch/elasticsearch.yml 192.168.15.52:/etc/elasticsearch/
[root@es-02 ~]# vim /etc/elasticsearch/elasticsearch.yml
# 设置集群名称
cluster.name: elk-cluster
# 设置集群节点名称(节点名称在集群中唯一)
node.name: es-node-02
# 设置数据存放目录
path.data: /var/lib/elasticsearch
# 设置日志存放目录
path.logs: /var/log/elasticsearch
# 设置内存锁定
bootstrap.memory_lock: true
# 设置监听的IP
network.host: 0.0.0.0
# 设置监听的端口
http.port: 9200
# 设置主节点
cluster.initial_master_nodes: ["192.168.15.51"]
9)、启动
[root@es-01 ~]# systemctl start elasticsearch.service
[root@es-01 ~]# netstat -nutlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address
......
tcp6 0 0 :::9200 :::* LISTEN 2891/java
tcp6 0 0 :::9300 :::* LISTEN 2891/java
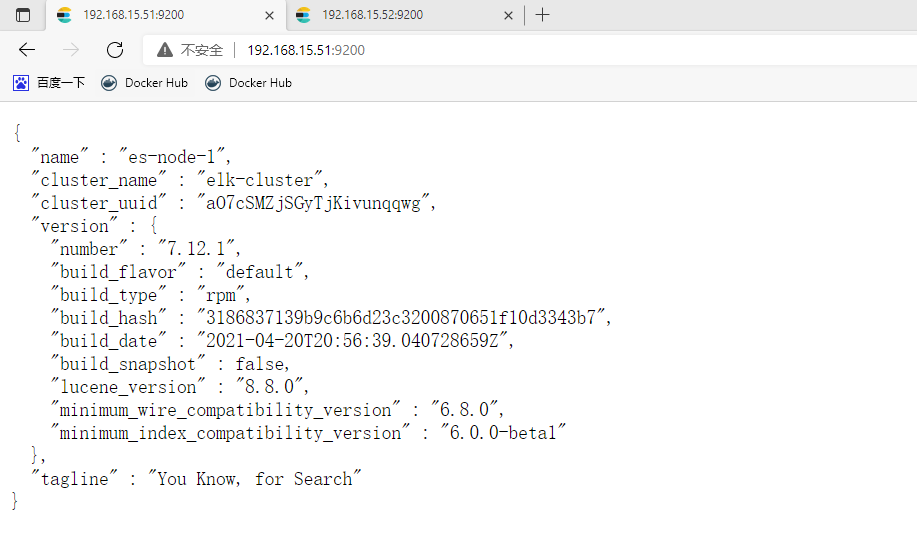
2、源码包安装(简单)
# 下载源码包
[root@es-01 ~]# wget https://github.com/elastic/elasticsearch/archive/refs/tags/v7.12.1.tar.gz
# 解压
[root@es-01 ~]# tar -xf v7.12.1.tar.gz -C /usr/local
# elasticsearch是依赖于Java
[root@es-01 /opt]# yum install java-1.8.0* -y
[root@es-01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
[root@es-01 /opt]# yum install elasticsearch-7.12.1-x86_64.rpm -y
3、docker安装 (主节点安装)
docker run -p 9200:9200 -p 9300:9300 -e "cluster.name=xxx" docker.elastic.co/elasticsearch/elasticsearch:7.12.1
4、安装集群head插件 (主节点安装)
head插件主要是图形化elastic search
1)、安装docker (主节点安装)
yum remove docker docker-common docker-selinux docker-engine -y
sudo yum install -y gcc gcc-c++ yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum clean all
yum makecache
yum install docker-ce -y
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xj6uu5rz.mirror.aliyuncs.com"]
}
EOF
# 启动docker
systemctl start --now docker
2)拉取镜像并后台运行 (主节点)
[root@es-01 ~]# docker run -d -p 9100:9100 alvinos/elasticsearch-head
e9c8f62358c1ddae141ab4eff64d19d3cce1b4944a4ed75d4907541f6a0f33e6

3)设置elasticsearch跨域访问 (两节点)
[root@es-01 ~]# vim /etc/elasticsearch/elasticsearch.yml
http.port: 9200
#开启跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
[root@es-01 ~]# systemctl restart elasticsearch.service
4)开始连接

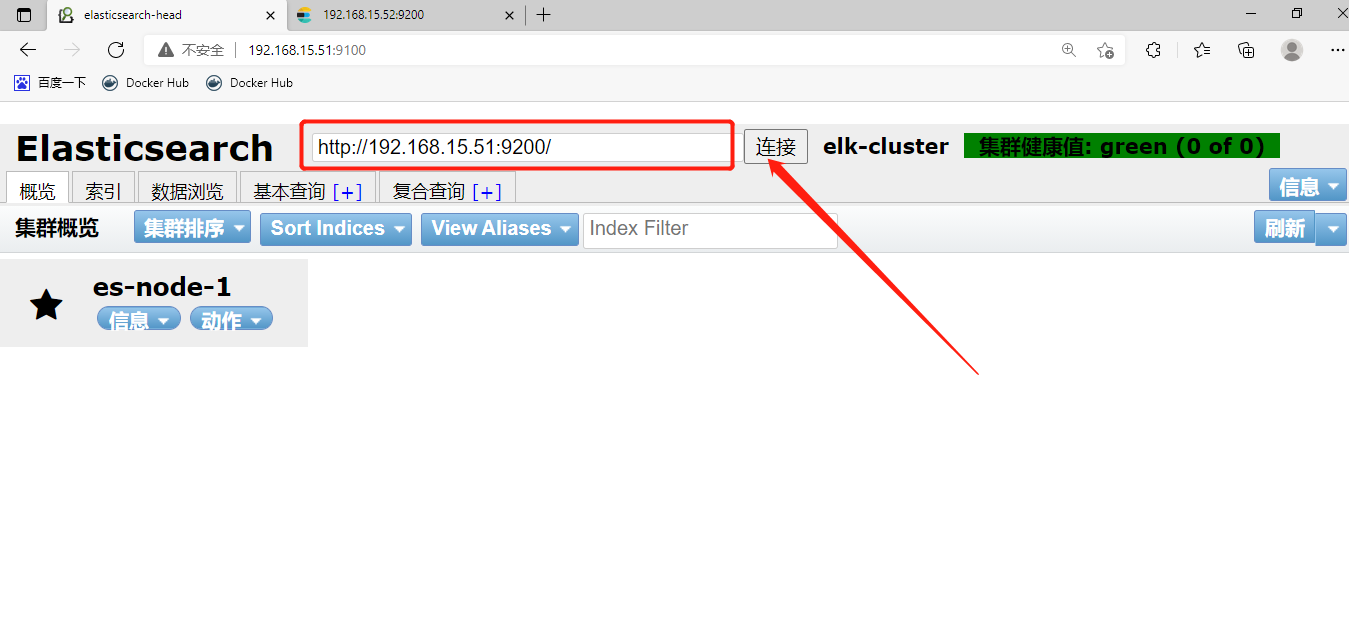
5、部署elasticsearch主从
elasticsearch是主从数据节点分离的,按照节点还可以分为热数据节点和冷数据节点。
1)、部署主节点
#设置时区
[root@es-01 ~]# timedatectl set-timezone Asia/Shanghai
#设置程序可以打开的文件数
[root@es-01 ~]# vim /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
#重启
reboot
#修改配置文件
[root@es-01 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.initial_master_nodes: ["192.168.15.51"] #在此行下添加以下内容
# # 设置选举策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点
discovery.zen.ping.unicast.hosts: ["192.168.15.51","192.168.15.52"]
# # 设置是否的主节点
node.master: true
#重启服务
[root@es-01 ~]# systemctl restart elasticsearch.service
2)、部署从节点
从节点系统优化与主节点一样
#修改从节点配置文件
[root@es-02 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.initial_master_nodes: ["192.168.15.51"] #在此行下添加以下内容
# # 设置选举策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点
discovery.zen.ping.unicast.hosts: ["192.168.15.51","192.168.15.52"]
# # 设置是否的主节点
node.master: false
#重启服务
[root@es-02 ~]# systemctl restart elasticsearch.service

#图形化界面如果出不来,是数据不一致
#故障报错解决:
做到这一步极其容易出现数据不一致的问题,反应到登录网页上就上明明好像能正常访问,其实它的的UUID是错误的。为此可以先删除/var/lib/elasticsearch/*下面的东西,然后再重启elasticsearch。这样就可以了。
[root@es-02 ~]# systemctl stop elasticsearch.service
[root@es-02 ~]# rm -rf /var/lib/elasticsearch/*
[root@es-02 ~]# tail -f /var/log/elasticsearch/elaina-es.log #实时监控集群日志发现问题
[root@es-02 ~]# systemctl start elasticsearch.service #新窗口执行启动命令
6、测试集群性能
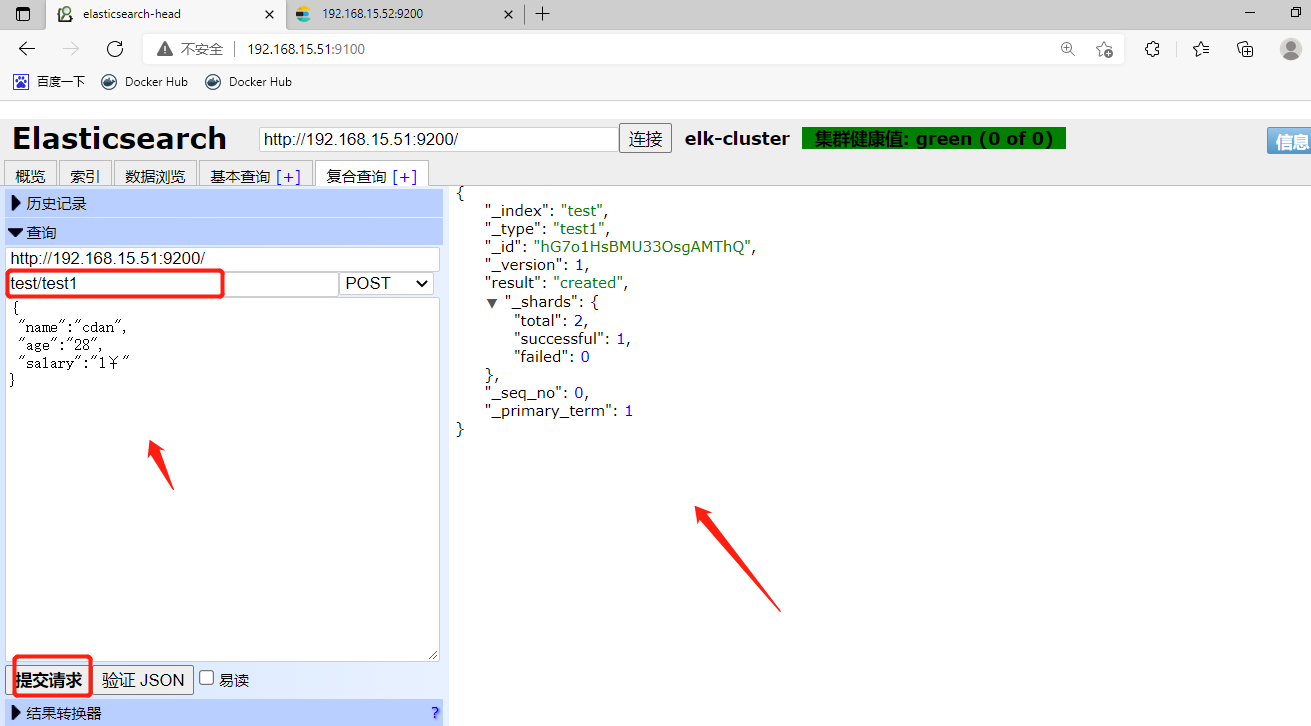

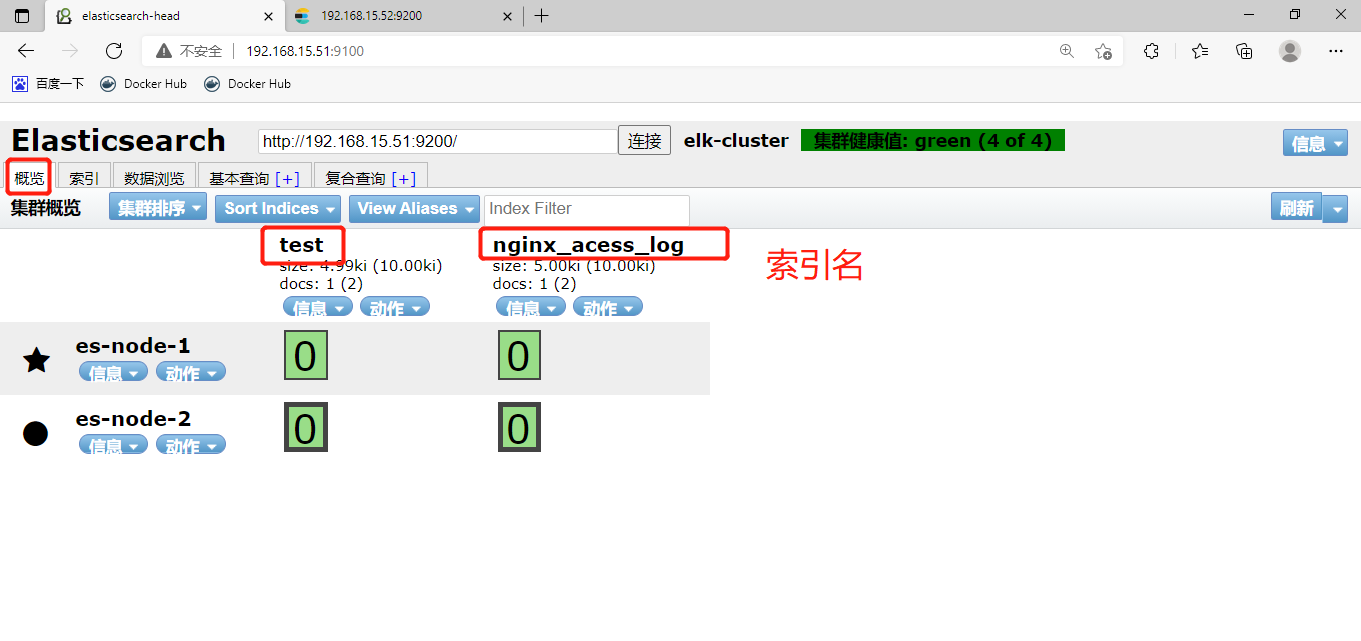

主节点和副本节点的区别
主节点的职责: 统计各node节点状态信息、集群状态信息统计、索引的创建和删除、索引分配的管理、关闭node节点等。
副本节点的职责: 同步数据,等待机会成为Master(当主节点宕机或者重启时)。
7、elasticsearch监控
#通过命令获取集群的状态
[root@es-01 ~]# curl ?sXGET http://192.168.15.51:9200/_cluster/health?pretty=true
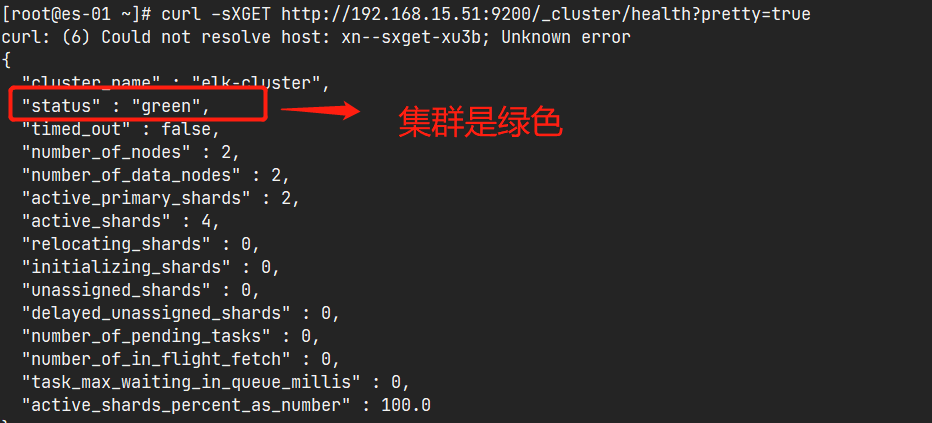
通过浏览器访问:http://192.168.15.15:9200/_cluster/health?pretty=true, 例如对 status 进行分析,如果等于green(绿色)就是运行在正常,等于yellow(黄色)表示副本分片丢失,red(红色)表示主分片丢失。
二、LogStach
Logstash 是一个开源的数据收集引擎,可以水平伸缩,而且 logstash 整个 ELK 当中拥有最多插件的一个组件,其可以接收来自不同来源的数据并统一输出到指定的且可以是多个不同目的地。
1、部署LogStach
部署logstach分别有三种方式:
1、rpm包安装
2、源码包安装
3、docker安装
2、rpm安装
# 下载安装包
[root@es-01 /opt]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-x86_64.rpm
# 安装
[root@es-01 /opt]# yum install logstash-7.12.1-x86_64.rpm -y
# 对数据目录设置权限
[root@es-01 /opt]# chown -R logstash.logstash /usr/share/logstash/
3、使用logstach
输出
- 输入输出到shell控制台
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug }}'
解释:
-e 参数
input: 从标准输入
stdin: 在标准输入读取时间
output:标准输出
stdout:打印在标准输出
rubydebug默认是写json
- logstach输出到文件当中
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { file { path => "/tmp/log-%{+YYYY.MM.dd}-messages.log"}}'
- logstach输出到elasticsearch当中
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch {hosts => ["192.168.15.51:9200"] index => "mytest-%{+YYYY.MM.dd}" }}'
- logstach输出到redis当中
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output {redis { host => "172.16.1.71" port => "6379" data_type => "list" key => "logstash-%{type}" }}'
读取
- logstach读取日志文件
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { file { path => "/var/log/messages" } } output { elasticsearch {hosts => ["192.168.15.51:9200"] index => "system-log-%{+YYYY.MM.dd}" }}'
- 在标准输出中读取
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-stdin-%{+YYYY.MM.dd}" }}'
- logstach在http中读取 (有误)
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { http { host => "192.168.15.18" port => "9200" } } output { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-http-%{+YYYY.MM.dd}" }}'
分类
- 从多个文件中读取文件
path => "/var/log/messages" #日志路径
type => "systemlog" #事件的唯一类型
start_position => "beginning" #第一次收集日志的位置
stat_interval => "3" #日志收集的间隔时间
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-stdin-%{+YYYY.MM.dd}" }}'
- 分类输出多个数据仓库
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { if [type] == "systemlog" { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-systemlog-%{+YYYY.MM.dd}" }} if [type] == "systemcron" { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-systemcron-%{+YYYY.MM.dd}" } } }'
- 使用配置文件
[root@es-01 ~]# touch test.conf
[root@es-01 ~]# vim test.conf
[root@es-01 ~]# cat test.conf
input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { if [type] == "systemlog" { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-systemlog-%{+YYYY.MM.dd}" }} if [type] == "systemcron" { elasticsearch {hosts => ["172.16.1.20:9200"] index => "system-systemcron-%{+YYYY.MM.dd}" } } }
# 测试配置文件
[root@es-01 ~]# /usr/share/logstash/bin/logstash -f test.conf -t
# 使用配置文件
[root@es-01 ~]# /usr/share/logstash/bin/logstash -f test.conf
三、kibana
Kibana 是一个通过调用 elasticsearch 服务器进行图形化展示搜索结果的开源项目。
1、部署kibana
下载解压安装包,一定要装与ES相同的版本
下载地址: https://www.elastic.co/downloads/kibana
# 下载安装包
[root@es-02 /opt]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
#安装
[root@es-02 opt]# yum install -y kibana-7.12.1-x86_64.rpm
#修改配置
[root@es-02 opt]# vim /etc/kibana/kibana.yml
[root@es-02 opt]# grep -n "^[a-Z]" /etc/kibana/kibana.yml
2:server.port: 5601 #打开监听的端口
7:server.host: "0.0.0.0" #监听地址,0代表所有
32:elasticsearch.hosts: ["http://192.168.15.51:9200"] #elasticsearch服务器的地址
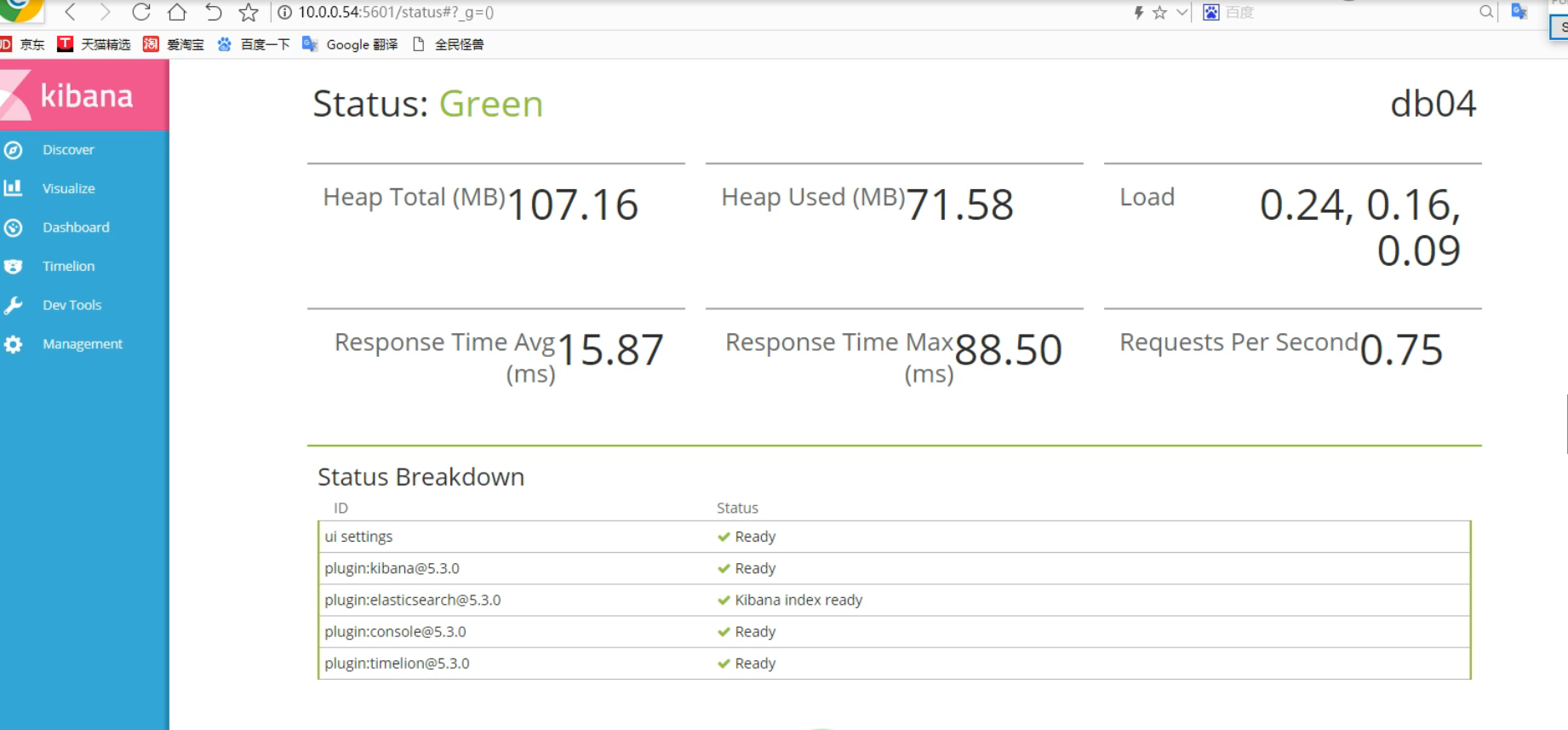
#启动并验证
[root@es-02 opt]# systemctl start kibana.service
[root@es-02 opt]# netstat -nutlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 4635/node
tcp6 0 0 :::9100 :::* LISTEN 2858/docker-proxy
tcp6 0 0 :::9200 :::* LISTEN 3460/java
tcp6 0 0 :::9300 :::* LISTEN 3460/java
[root@es-02 ~]# yum install -y redis*
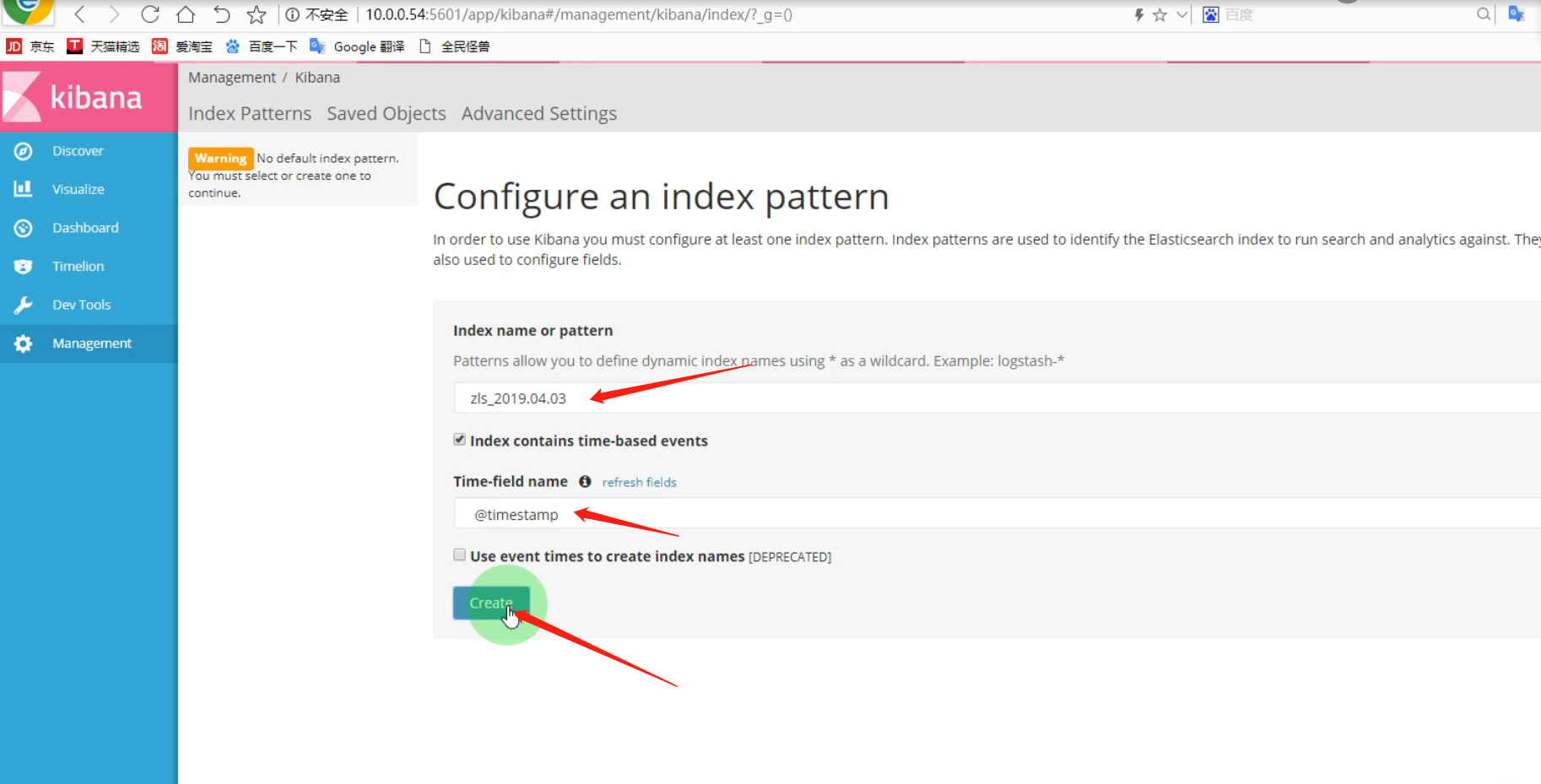
kibana中添加ES索引

在上图右边红框出写入ES索引名,下图中红框部分,就是ES中的索引,也是日志名称。
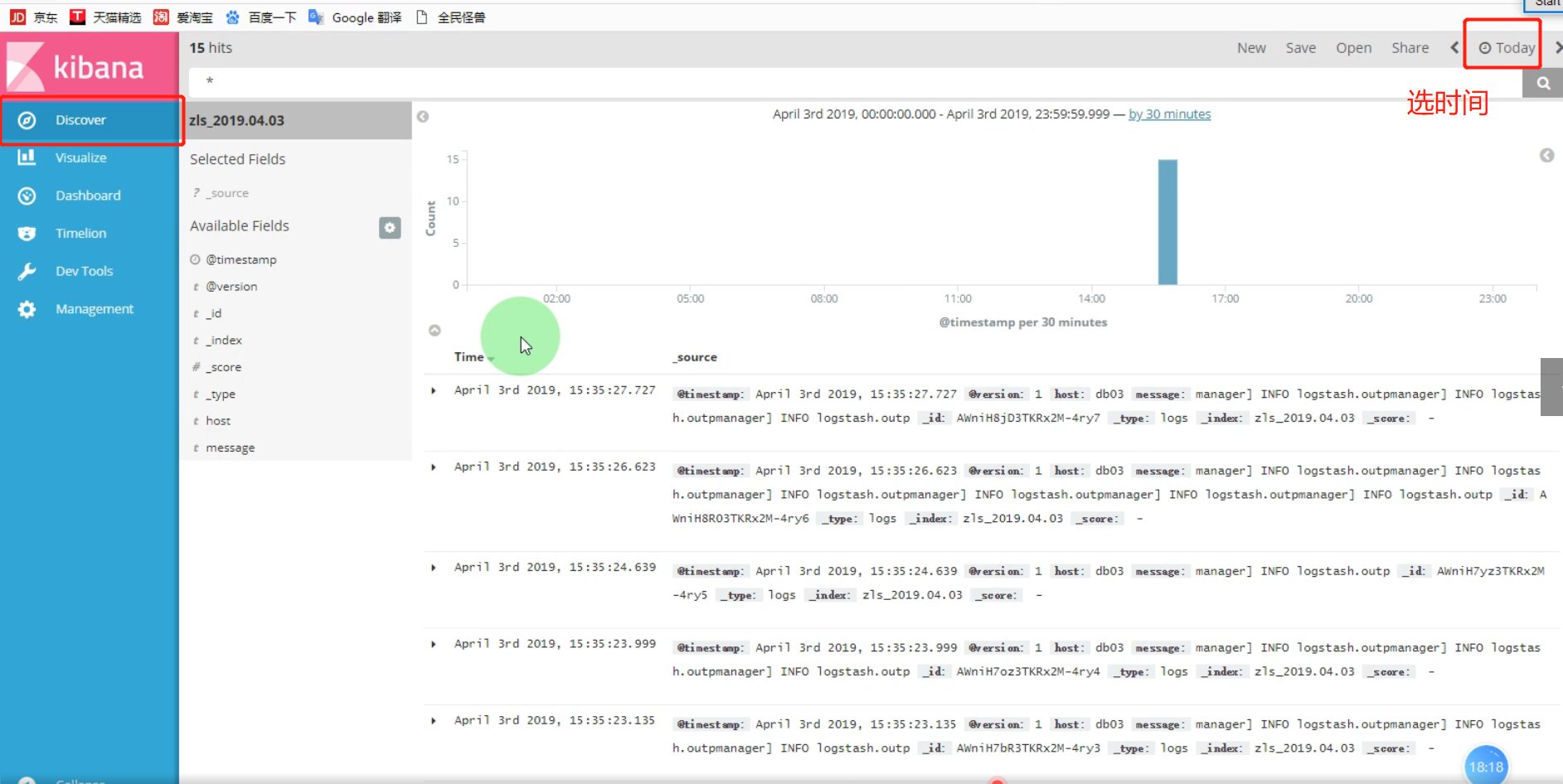

2、kibana区域定义及说明
绿色区域
时间区域,选择想要查看日志的时间段:
第一个是快速查询,可以查看今天,这周,这个月,这一年,昨天…… 等时段的日志
第二个是查看具体那个时间段之前,到现在为止的一段时间的日志
第三个是精确查找,可以根据日志,具体到某个时间点,可精确到秒
黄色区域
功能区域,查看日志,画图工具,图形展示,时间轴,开发工具,管理工具
黑色区域
日志列表区,选择自己想看的日志,日志名以项目名开头,后面是对应的域名。 例:[zls_]YYYY.MM.DD 标红的为日期格式。
红色区域
搜索区,使用Lucene语法搜索想要内容。
白色区域
展示区 ,日志的详细信息,及过滤日志后会高亮显示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号