一、python基础相关知识体系
python基础
a. Python(解释型语言、弱类型语言)和其他语言的区别?
一、编译型语言:一次性,将全部的程序编译成二进制文件,然后在运行。(c,c++ ,go)
运行速度快。开发效率低
二、解释型语言:当你的程序运行时,一行一行的解释,并运行。(python , PHP)
运行速度相对较慢,但是调试代码很方便,开发效率高
三、混合型:(C#,Java)
python特点:
- python代码结构清晰简洁、简单易学
- 开发效率非常高,Python有非常强大的第三方库
- 可移植性--由于python开源本质,Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性--可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性--可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
2、python解释器


CPython 当我们从Python官方网站下载并安装好Python 3.6后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。 CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。 IPython IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。 CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。 PyPy PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。 绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。 Jython Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。 IronPython IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。 小结: Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
3、 请至少列举5个 PEP8 规范(越多越好)
1、缩进使用4个空格键。不建议使用tab
2、运算符左右隔空一格
3、类名首字母大写
4、函数命名全部使用小写,可以用下划线分割
5、常量或全局变量使用大写,可以用下划线分割
6、不建议import os,time
7、建议使用块注释
4、 通过代码实现如下转换
print("转换为二进制为:", bin(dec)) int("01010101",2)
print("转换为八进制为:", oct(dec))
print("转换为十六进制为:", hex(dec))
5、请编写一个函数实现将IP地址转换成一个整数

def addr2dec(addr): "将点分十进制IP地址转换成十进制整数" items = [int(x) for x in addr.split(".")] print(items) return sum(items[i] << [24, 16, 8, 0][i] for i in range(4)) print(addr2dec("10.3.9.12"))
6、ascii、unicode、utf-8、gbk 区别?
python2内容进行编码(默认ascii),而python3对内容进行编码的默认为utf-8。
ascii 最多只能用8位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。 1-->48 A-->65 a-->97
unicode 规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
UTF-8 是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:
A 1个字节 欧洲 一个字 2个字节 亚洲 一个子 3个字节
gbk A : 1个字节 中 :两个字节
v1 = 1 or 3
#1
v2 = 1 and 3
#3
v3 = 0 and 2 and 1 #0
v4 = 0 and 2 or 1 #1
v5 = 0 and 2 or 1 or 4 #1
v6 = 0 or False and 1 #False
7、字节码和机器码的区别?
机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。
字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
8、列举 Python2和Python3的区别?
1、默认解释器编码:
py2: ascii
py3: utf-8
2、字符串:
py2: str:字符串 -->字节
unicode:u"shh"
py3: bytes 和 str
3、range和xrange
py2 range返回list xrange返回生成器
py3 range返回生成器
4、py2 int、long
py3 int
5、py2 yield
py3 yiled、 yield from
6、py2 新式类和经典类
py3 新式类
7、py2 raw_input py3 input
8、py2 print py3 print()
9、Python3和Python2中 int 和 long的区别?
python3去除了long类型,现在只有一种整型——int,但它的行为就像python2版本的long
10、 布尔值为False的常⻅值都有那些?
0 空列表字符串 负数 不成立的表达式 None 等
11、文件操作时:xreadlines和readlines的区别?
readlines 返回一个列表
xreadlines 返回一个生成器
12、数据类型
不可哈希:list dict set 可哈希:int str bool None tuple
- 字符串 strip()去除
find()找不到返回-1 、index()找不到报错
split()分割
join()拼接
replace()替换
- 字典 pop() 删除 创建字典的三种方法:1、直接表达 2、dict(name="cao") 3、dict.formkeys(["key","key"],value)
update()
clear()清空
get()
dict.items() - 元组tuple 只读 按str索引方法去查 - 列表 append()
inset()按索引增加
extend()迭代增加
conut()
sort()排序
index()
rserver()反转 - 集合 add() update() remove() del() pop() clear() 交集$ 并集| 差集-
collections Python内建的一个集合模块,提供了许多有用的集合类。
Counter是一个简单的计数器,例如,统计字符出现的个数:
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
defaultdict使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
13、*arg和**kwarg作用
*args :接收所有按照位置传的参数,接收到的是参数组成的元祖
**kwargs :接收所有按照关键字传的参数,接收到的是参数组成的字典
14、Python垃圾回收机制?
引用计数 (对象被引用时+1,引用的对象被删除时-1)
标记清除
分代回收(系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,垃圾收集的频率随着“代”的存活时间的增大而减小)
15、深浅拷贝
在Python中对象的赋值其实就是对象的引用。当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已。
浅拷贝:拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制
深拷贝:外围和内部元素都进行了拷贝对象本身,而不是引用。也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制。
###############################
浅拷贝copy ,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,与原内存地址不变。
l1 = [1,[22,33,44],3,4,] l2 = l1.copy() l1[1].append('55') print(l1,id(l1),id(l1[1])) #[1, [22, 33, 44, '55'], 3, 4] 1787518244744 1787518244808 print(l2,id(l2),id(l2[1])) #[1, [22, 33, 44, '55'], 3, 4] 1787518244616 1787518244808 ############ l1[1].append("cao") print(l1) #[1, [22, 33, 44, '55', 'cao'], 3, 4] print(l2) #[1, [22, 33, 44, '55', 'cao'], 3, 4] ######################### l1[0] = "chao" print(l1) #['chao', [22, 33, 44, '55'], 3, 4] print(l2) #[1, [22, 33, 44, '55'], 3, 4]
深拷贝deepcopy,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
import copy l1 = [1,[22,33,44],3,4,] l2 = copy.deepcopy(l1) print(id(l1[1])) print(id(l2[1])) print("="*20) l1[0] = 111 print(l1) print(l2) print("="*20) l1[1].append('barry') print(l1) print(l2) ############ 1742824920904 1742824920520 ==================== [111, [22, 33, 44], 3, 4] [1, [22, 33, 44], 3, 4] ==================== [111, [22, 33, 44, 'barry'], 3, 4] [1, [22, 33, 44], 3, 4]
16、一行代码实现9*9乘法表
print('\n'.join([' '.join(['%s*%s=%-2s' % (j, i, i * j) for j in range(1, i + 1)]) for i in range(1, 10)]))
17、求结果
v = dict.fromkeys(['k1','k2'],[]) print(v) v["k1"].append(666) print(v) v["k1"] = 777 print(v)
{'k1': [], 'k2': []}
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
##############
def num():
return [lambda x:x+1 for i in range(4)]
print([m(2) for m in num()]) #[3,3,3,3]
print([m(1) for m in num()]) #[2,2,2,2]
################
print([ i % 2 for i in range(10) ]) #[0,1,0,1,0,1,0,1,0,1]
print(( i % 2 for i in range(10) )) #生成器
###################
a. 1 or 2 1
b. 1 and 2 2
c. 1 < (2==2) False
d. 1 < 2 == 2 Ture
not > and > or
函数
- 函数参数传递的是什么? 引用、内存地址
#魔性的用法:默认参数尽量避免使用可变数据类型 类型一: lst = [] def func(l = lst): #默认参数 l.append(1) print(l) func() #[1] func() #[1,1] 默认参数只会被执行一次:第一次调用函数时,默认参数被初始化为【】,以后每次调用时都会使用已经初始化的【】。 类型二: lst = [] def func(l = lst): l.append(1) print(l) func([]) #[1] func([]) #[1] 类型三: def func(a1,a2=[]): a2.append(a1) print(a2) func(1) #[1,] func(3,[]) #[3,] func(4) #[1,4] 类型四: def func(a1,a2=[]): a2.append(a1) return a2 l1 = func(1) print(l1) # [1,] l2 = func(3,[]) print(l2) # [3, ] l3 = func(4) print(l3) # [1,4] 类型五: def func(a1,a2=[]): a2.append(a1) return a2 l1 = func(1) # l1=[1,4] l2 = func(3,[]) # l2=[3,] l3 = func(4) # l3=[1,4] print(l2) print(l1) print(l3)
17、lambda、三元表达式
简单的函数: my_lambda = lambda arg : arg + 1
简单的条件语句: val= "cao" if 1==1 else "chao"
各种推导式
列表生成式 s1=[i*2 for i in range(5)] print(s1) 生成器表达式 s=(i*2 for i in range(5) ) print(s.__next__()) print(next(s))
基于列表生成式和lambda应用
val = [lambda :i + 1 for i in range(10)] [function,funtion...] print(val,type(val)) #<class 'list'> print(val[0],type(val[0])) #<class 'function'> data = val[0]() print(data) #10
应用到闭包函数:
当调用函数的时候,都会优先在外部作用域中查找i变量,这时列表生产式中循环立马执行,最后i赋值为9
18、闭包
def foo(): m=3 n=5 def bar(): a=4 return m+n+a return bar >>>bar = foo() >>>bar() 12
简单的说,这种内部函数可以使用外部函数变量的行为,就叫闭包。
闭包的意义与应用:延迟计算:
闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域
#应用领域:延迟计算(原来我们是传参,现在我们是包起来)
装饰器就是闭包函数的一种应用场景
19、- 常见内置函数:
- map - filter
map()函数接收两个参数,一个是函数,一个是可迭代对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。 def mul(x): return x*x n=[1,2,3,4,5] res=list(map(mul,n)) print(res) #[1, 4, 9, 16, 25] filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False, filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。 def is_odd(x): return x % 2 == 1 v=list(filter(is_odd, [1, 4, 6, 7, 9, 12, 17])) print(v) #[1, 7, 9, 17]
- isinstance - type
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
- zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。 >>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
- reduce
from functools import reduce
reduce() 函数会对参数序列中元素进行累积。 用传给reduce中的函数 function(有两个参数)先对集合中的第1、2个元素进行操作,得到的结果再与第三个数据用function函数运算,最后得到一个结果。 >>>def add(x, y) : # 两数相加 ... return x + y ... >>> reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5 15 >>> reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数 15
生成器、迭代器、装饰器
20、生成器
生成器:一个函数调用时返回一个迭代器,或 函数中包含yield语法,那这个函数就会变成生成器;
应用场景:
- range/xrange - py2: range(1000),立即创建;xrange(1000)生成器; - py3: range(1000)生成器; 没有xrange
-redis获取值
hscan_iter 利用yield封装hscan创建生成器,实现分批去redis中获取数据
21、迭代器
迭代器:含有__iter__和__next__方法 (包含__next__方法的可迭代对象就是迭代器)
特点:
访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容(惰性计算)
不能随机访问集合中的某个值 ,只能从头到尾依次访问
访问到一半时不能往回退
便于循环比较大的数据集合,节省内存
可迭代对象:一个类内部实现__iter__方法且返回一个迭代器。
应用场景:
- wtforms中对form对象进行循环时候,显示form中包含的所有字段。
- 列表、字典、元组
总结:如果想要让一个对象可以被for循环,那么就需要在当前类中定义__iter__
22、装饰器
问题:什么是装饰器?
在对原函数不进行修改时,在函数执行前和执行后添加功能
问题:手写装饰器
import functools
def warpper(func):
@functools.wraps(func) #保留原函数信息
def inner(*args,**kwargs):
#执行函数前
return func(*args,**kwargs)
#执行函数后
return inner
# 1. 执行wapper函数,并将被装饰的函数当做参数。 wapper(index)
# 2. 将第一步的返回值,重新赋值给 新index = wapper(老index)
@warpper #index=warpper(index)
def index(x):
return x+100
问题:应用场景
django: csrf 内置认证、缓存
flask: 路由、before_request
带参数装饰器:flask:路由
CBV as_view()
23、偏函数
偏函数: import functools def func(a1, a2, a3): return a1 + a2 + a3 new_func = functools.partial(func, 11, 2) #将11,2依次传入到func函数的前两个参数 print(new_func(3))
应用场景
falsk中取值时 通过localproxy 、偏函数、localstack、local
24、谈谈面向对象认识
-继承、封装、多态(简单描述)
python中一切皆对象
封装:
其实就是将很多数据封装到一个对象中,类似于把很多东西放到一个箱子中,
如:一个函数如果好多参数,起始就可以把参数封装到一个对象再传递。
应用场景:
- django rest framework中的request对象。
- flask中:request_context/app_context对象
继承:
如果多个类中都有共同的方法,那么为了避免反复编写,就可以将方法提取到基类中实现,让所有派生类去继承即可。
应用场景:
- rest frmawork 视图
- 版本、认证、分页
多态:
python本身就是多态的,崇尚鸭子模型,只要会呱呱叫我么就认为它是鸭子。
class A: def send(self): print("A") class B: def f(self): print("B") def func(arg): arg.send() obj = A() func(obj)
-双下划线:
__getattr__
-CBV
-django配置文件
-wtforms中的Form()示例化中 将"_fields中的数据封装到From类中"
__mro__ wtform中 FormMeta中继承类的优先级 __dict__ __new__ ,实例化但是没有给当前对象 wtforms,字段实例化时返回:不是StringField,而是UnboundField rest frawork many=Turn 中的序列化
单例模式 __call__ flask 请求的入口app.run() 字段生成标签时:字段.__str__ => 字段.__call__ => 插件.__call__ __iter__ 循环对象是,自定义__iter__ wtforms中BaseForm中循环显示所有字段时定义了__iter__ -metaclass - 作用:用于指定当前类使用哪个类来创建 - 场景:在类创建之前定制操作 示例:wtforms中,对字段进行排序。
25、super作用
子类继承父类的方法,其继承顺序按照__mro__
26、静态方法和类方法区别
staticmethod
classmethod 需要传入参数cls当前类
两种方法都不需要实例化就可以使用l类.方法或对象.方法
26、⾯向对象深度优先和广度优先是什么?
Python的类可以继承多个类,Python的类如果继承了多个类,那么其寻找方法的方式有两种
当类是经典类时,多继承情况下,会按照深度优先方式查找
当类是新式类时,多继承情况下,会按照广度优先方式查找
简单点说就是:经典类是纵向查找,新式类是横向查找
经典类和新式类的区别就是,在声明类的时候,新式类需要加上object关键字。在python3中默认全是新式类
27、什么是函数什么是方法
from types import MethodType,FunctionType class Foo(object): def fetch(self): pass Foo.fetch 此时fetch为函数 print(isinstance(Foo.fetch,MethodType)) print(isinstance(Foo.fetch,FunctionType)) # True obj = Foo() obj.fetch 此时fetch为方法 print(isinstance(obj.fetch,MethodType)) # True print(isinstance(obj.fetch,FunctionType))
28、单例模式
单例模式:一个类只能有一个实例化对象
应用场景:Django中的admin组件中admin.site()就是由单例模式创建的,其中封装了所有的表对象
#基于new
class Singleton(object):
每一次实例化的时候,返回同一个instance对象 def __new__(cls,*args,**kwargs): if not hasattr(cls,"instance"): cls.instace=super(Singleton,cls).__new__(cls,*args,**kwargs) return cls.instace a=Singleton() b=Singleton() print(a,b) print(a is b)
#基于装饰器
def Singleton(cls):
_instance={}
def _singleton(*args,**kwargs):
if cls not in _instance:
_instance[cls]=cls(*args,**kwargs)
return _instance[cls]
return _singleton
@Singleton
class A(object):
a=1
def __init__(self,x=None):
self.x=x
c=A(2)
b=A(3)
print(c is b)
模块
29、常用模块
os、sys、json、re、logging、random、time、requests、beautifulsoup,
os模块是与操作系统交互的一个接口 ,提供了很多方法来处理文件和目录
os.remove(‘path/filename’) 删除文件 os.rename(oldname, newname) 重命名文件 os.walk() 生成目录树下的所有文件名 os.chdir('dirname') 改变目录 os.getcwd() 取得当前工作目录 os.path.getsize() 返回文件大小
sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
logging :记录日志,分为五种级别,debug,info ,warning,error,critical
random
random.random() 0-1随机数
random.randint(1,9) 1-9 随机整数
requests 获取页面html和xml
json 序列化
30、re正则
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 \b 匹配一个单词的结尾 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符 用法说明 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
1、写一个邮箱、手机号、IP
#匹配手机号 import re def phone(arg): s=re.match("^(13|14|15|18)[0-9]{9}$",arg) if s: return "正确" return "错误" print(phone("23722751552"))
#匹配邮箱
re.match("^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$",arg)
#匹配IP
re.match("\b(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\b",arg)
?: 优先匹配
\b 匹配一个单词的结尾
31、match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
1 import re 2 s="fnfffidvvgf" 3 4 m=re.match("fi",s) 5 print(m) #None 6 s=re.search("fi",s).group() 7 print(s) #fi
32、贪婪匹配与非贪婪匹配
贪婪匹配: 匹配1次或多次<.+> 匹配0次或多次<.*>
非贪婪匹配:匹配0次或1次<.?>
34. 如何⽤⼀代码⽣成[1,4,9,16,25,36,49,64,81,100]
[i**2 for i in range(1,11)]
35 、⼀⾏代码实现删除列表中重复的值
list(set([1,2,45,5,2]))
36、用Python实现一个二分查找的函数
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def search(someone, li): l = -1 h = len(li) while l + 1 != h: m = int((l + h) / 2) if li[m] < someone: l = m else: h = m p = h if p >= len(li) or li[p] != someone: print("元素不存在") else: str = "元素索引为%d" % p print(str) search(1, li) # 元素索引为2
37、给出路径找文件
方法一: 使用os.walk file-- 是你所要便利的目录的地址, 返回的是一个三元组(root,dirs,files)。 root 所指的是当前正在遍历的这个文件夹的本身的地址 dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录) files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录) def open_2(file): for root, dirs , files in os.walk(file): print("ss",files) for filename in files: print(os.path.abspath(os.path.join(root, filename))) #返回绝对路径 open_2("F:\搜索") 方法二: import os def open(files): for dir_file in os.listdir(files): # print("ss",dir_file) #递归获取所有文件夹和文件 files_dir_file = os.path.join(files, dir_file) if os.path.isdir(files_dir_file): #是不是文件夹 open(files_dir_file) else: print(files_dir_file) open("F:\搜索") 并将下面的所有文件内容写入到一个文件中 def open_2(file): for root, dirs , files in os.walk(file): for filename in files: with open(os.path.abspath(os.path.join(root, filename)), "r") as f: for i in f.readlines(): print(i) with open("./cao.txt","a",encoding="utf-8") as f2: f2.write(i) f2.write("\n") open_2("F:\搜索")
38、创建、删除文件
1 # 创建一个文件 2 open("chao.txt","w",encoding="utf-8") 3 import os
#删除文件 4 os.remove("chao.txt")
39、第三方软件安装
1、pip3 包管理器
2、源码安装
-下载、解压
-python setup.py bulid
-python setup.py install
40、1、2、3、4、5 能组成多少个互不相同且⽆重复的三位数
使用python内置的排列组合函数(不放回抽样排列) product 笛卡尔积 (有放回抽样排列) permutations 排列 (不放回抽样排列) combinations 组合,没有重复 (不放回抽样组合) combinations_with_replacement 组合,有重复 (有放回抽样组合) import itertools print(len(list(itertools.permutations('12345', 3)))) # 60
50、什么是反射
反射的核心本质就是以字符串的形式去导入个模块,通过字符串的形式操作对象相关的属性
Django中的 CBV就是基于反射实现的。
导入模块:
x=__import__("time")
print(x.time())
51、metaclass作用?以及应用场景?
指定当前类是由那个类创建的
默认为type
- 场景:在类创建之前定制操作
- 示例:wtforms中,对字段进行排序。
52、异常处理理写法以及如何主动跑出异常(应⽤用场景)
try: fh = open("testfile", "w") try: fh.write("这是一个测试文件,用于测试异常!!") finally: print "关闭文件" fh.close() except IOError: print "Error: 没有找到文件或读取文件失败" raise抛异常 inputValue=input("please input a int data :") if type(inputValue)!=type(1): raise ValueError else: print inputValue
53、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
整数、字符创、字典、列表、bool、None
重写default() import json import datetime dic = { 'k1':123, 'ctime':datetime.datetime.now() } class MyJSONEncoder(json.JSONEncoder): def default(self,o): if isinstance(o,datetime.datetime): return o.strftime("%Y-%m-%d") else: return super(MyJSONEncoder,self).default(o) v=json.dumps(dic,cls=MyJSONEncoder) print(v)
54、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办
json.dumps(xxxx,ensure_ascii=False)
55、有用过with statement吗?它的好处是什么?
上下文管理器:
在使用Python编程中,可以会经常碰到这种情况:有一个特殊的语句块,在执行这个语句块之前需要先执行一些准备动作;当语句块执行完成后,需要继续执行一些收尾动作。 例如:当需要操作文件或数据库的时候,首先需要获取文件句柄或者数据库连接对象,当执行完相应的操作后,需要执行释放文件句柄或者关闭数据库连接的动作。 又如,当多线程程序需要访问临界资源的时候,线程首先需要获取互斥锁,当执行完成并准备退出临界区的时候,需要释放互斥锁。 对于这些情况,Python中提供了上下文管理器(Context Manager)的概念,可以通过上下文管理器来定义/控制代码块执行前的准备动作,以及执行后的收尾动作。
在Python中,可以通过with语句来方便的使用上下文管理器,
with语句可以在代码块运行前进入一个运行时上下文(执行__enter__方法),并在代码块结束后退出该上下文(执行__exit__方法)。
操作文件:with open
Flask中的离线脚本:
with app.app_context():
pass
56、简述 yield和yield from关键字。
yiled:1、一个函数中含有yield关键字,此函数为生成器,
2、生成器调用是不会立即执行,必须使用next()(结束是会报错)或send()或for调用执行
3、yield可以返回值也可以取值(生产者消费者模式)
4、调用生成器send方法传递数据时,必须先调用next(生成器)或者生成器.send(None)方法
yield from 可以让生成器,直接在其他函数中调用,
网络编码
56、OSI 七层协议
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
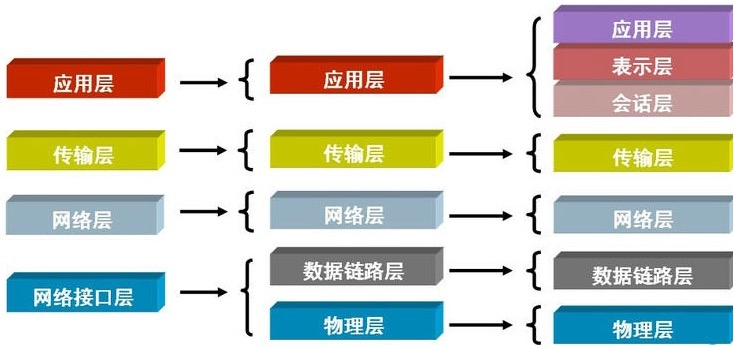
物理层:主要是基于电器特性发送高低电压(电信号),高电压1,低电压0,设备有网卡、网线、集线器,中继器,双绞线等! 单位:bit比特
数据链路层:定义了电信号的分组方式(电信号0和1没有实际意义)规定了报头(18字节)和数据 设备有:网桥、以太网交换机、网卡 单位:帧
网络层:主要功能是将ip地址翻译成对应的mac物理地址 路由 arp协议
传输层:建立端口到端口之间的通信 tcp协议udp协议
会话层:建立客户端与服务端连接
表示层:对来自应用层的命令和数据进行解释,并按照一定的格式传送给会话层
应用层:规定应用程序的数据格式
57、什么是C/S架构和B/S架构
C/S架构:
client端与server端的服务架构(客户端可以包含一个或多个在用户的电脑上运行的程序)
B/S架构:隶属于C/S架构的
Broswer端(网页端)与server端
优点:统一了所有应用程序的入口、使用方便、轻量级
58、三次握手四次挥手
三次握手:
SYC=1(建立连接) ACK(确认请求)
1、客户端(Client)向服务端(Server)发送一次请求(请求连接)
2、服务端确认并回复客户端(ACK=1, SYC=1,并在seq基础上产生一个随机数发给客户端)
3、客户端检验确认请求(ACK=1) 此时客户端与服务端就建立了连接
四次挥手:
FAN=1(断连接) ACK=1(确认请求)
1、客户端向服务端发一次请求(FAN=1)
2、服务端回复客户端 (ACK=1) (断开客户端—>服务端)
3、服务端再向客户端发请求(FAN=1) (因为有数据传输,所以2、3不能合并)
4、客户端确认请求(ACK=1) (断开服务端--->客户端)
59、为何基于tcp协议的通信⽐基于udp协议的通信更可靠
tcp是基于连接的,必须先启动服务端,然后再启动客户端去连接服务端(三次握手,四次挥手)
udp是无连接的,先启动那一端都可以 (应用:QQ聊天) (可能会产生丢包,因为服务端不监听客户端只负责发送数据,不管客户端是否收到数据)
60、什么是socket?简述基于tcp协议的套接字通信流程
两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket
TCP协议操作:
服务器端: 客户端
创建套接字 创建套接字
绑定ip和端口 绑定ip和端口
监听 连接服务器
accept等待连接 通信(收recv,发send)
通信(收recv,发send)
UDP:传输速度快
不面向连接,不能保证数据的完整性
服务器端: 客户端:
创建套接字 绑定套接字
绑定ip和端口 通信(收recvfrom,发sendto)
通信(收recvfrom,发sendto)
61、什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
粘包只会在tcp中产生,因为tcp是面向连接的、面向流(可以将多个小数据合并成一个大的数据包发送)这样以来,接收方不知道 数据包中的数据是以什么未分割数据的,就会产生粘包
而udp是无连接的、面向消息的(他不会将多个消息合并成一个大消息发送的,即使是空消息也会发送(自动加上消息头的))
两种情况:
1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
62、IO多路复用的作用?
监听多个socket是否发生变化
- select,内部循环检测socket是否发生变化;最多检测1024个socket
- poll, 内部循环检测socket是否发生变化;
- epoll, 使用回调函数的机制(自定义了三个函数)任务完成时自动调用的函数
63、交换机与路由器的区别
交换机 路由器(小型交换机)
数据链接层 网络层
利用mac地址确定传输数据的目的地 利用网关ip地址确定传输数据的目的地
有防火墙
64、什么是防火墙以及作用?
防火墙是内部网与外部网之间的一种访问控制设备。
它可通过监测、限制、更改跨越防火墙的数据流,尽可能地对外部屏蔽网络内部的信息、结构和运行状况, 以此来实现网络的安全保护。
65、什么是局域网和广域网?
局域网:是指在小范围内由多台计算机互联成的计算机组 广域网:
66、子网掩码
ip和子网掩码做按位与运算,可以得到网关ip
子网掩码是用来判断任意两台计算机的IP地址是否属于同一个子网络的根据。
并发编程
65、进程、线程、协程的区别
进程:正在执行的一个程序或者一个任务,而执行任务的是cpu
每个进程都有自己的独立内存空间,不同进程通过进程间通信IPC(队列,管道)来通信。
开进程消耗比较大,且上下文进程间的切换开销比较大,
相比线程数据相对比较稳定安全。
线程:线程是进程的一个实体,是CPU调度和分派的基本单位
线程间通信主要通过共享内存,开线程资源开销小,上下文切换很快,但相比进程不够稳定容易丢失数据。
协程:是一种“微线程”,实际并不存在,是程序员人为创造出来的控制程序调度的(程序执行一段代码,切换执行另一段代码)它可以实现单线程下的并发、
1、程序执行遇到IO切换,性能提高,实现了并发
2、无IO时切换,性能降低
优点:
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2. 单线程内就可以实现并发的效果,最大限度地利用cpu
1、进程多与线程比较
1.线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
2.一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
3.进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
4.开启进程比开线程资源开销大,线程上下文切换比进程上下文切换要快得多。因为线程共享进程内的资源
2、协程与线程进行比较
1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
进程是系统分配系统资源的最小单位,进程之中可以有多个线程,一个进程中的所有资源共享,进程之间资源不会共享;
线程是系统进行任务调度的最小单位,一个进程中的线程共享该进程的系统资源,线程是轻量级的进程;
协程又称微线程,轻量级线程,执行具有原子性,执行需要程序员来调用度,可以执行效率高
3、多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
4、使用concurrent.futures开线程池和进程池
5、进程锁与线程锁
进程锁:
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 1 队列和管道都是将数据存放于内存中 2 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
线程锁:
GIL和Lock
解决死锁问题使用递归锁(Rlock)
73、进程锁和线程锁的作用?
进程锁:为了避免多个进程同时同享一个资源,加锁限制同一时间只能有一个进程修改数据,从而保证数据安全 (可以使用队列和管道)
线程锁:同一时间只能一个线程访问加锁的资源,但是其他线程可以访问未加锁的资源
66、GIL锁
GIL是全局解释器锁,它的本质是一把互斥锁,将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。(同一时刻同一进程中只有一个线程被执行)
66、GIL与lock的区别
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
结论:保护不同的数据就应该加不同的锁。
GIL 与Lock是两把锁,保护的数据不一样,GIL是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),
Lock是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理
67、进程池和线程池
进程池;
from concurrent.futures import ProcessPoolExecutor import time,os def piao(name,n): print('%s '%(name)) time.sleep(2) return n**3 if __name__=='__main__': p = ProcessPoolExecutor(4) objs= [] for i in range(10): obj = p.submit(piao,'sb %s'%i,i) objs.append(obj) p.shutdown(wait=True) print("主",os.getpid()) for obj in objs: print(obj.result())
from concurrent.futures import ProcessPoolExecutor import time,os def piao(name,n): print('%s is pioing %s'%(name,os.getpid())) return n**2 if __name__=='__main__': p = ProcessPoolExecutor(4) for i in range(10): res = p.submit(piao,'alex %s'%i,i).result() print(res) p.shutdown(wait=True) print('主',os.getpid())
线程池:
from concurrent.futures import ThreadPoolExecutor from threading import current_thread import time,random def task(n): print('%s is running' %current_thread().getName()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': # t=ProcessPoolExecutor() #默认是cpu的核数 # import os # print(os.cpu_count()) t=ThreadPoolExecutor(3) #默认是cpu的核数*5 objs=[] for i in range(10): obj=t.submit(task,i) objs.append(obj) t.shutdown(wait=True) for obj in objs: print(obj.result()) print('主',current_thread().getName())
68、threading.local的作用?
为每一个线程开辟一块内存空间存数据
69、进程之间如何进行通信?
1、管道(无名管道、有名管道)
2、消息队列
3、信号量
4、信号
5、共享内存地址
6、socket
70、什么是arp协议?
通过ip地址获取mac地址的一种协议
71、什么是并发和并行?
并发:是一种伪并行,单个cpu可以利用多道技术实现“并发”
并行:多个任务可以同时运行,多cpu才能实现
72、解释什么是异步非阻塞?
- 非阻塞:程序执行过程中遇到IO不等待 - 代码: sk = socket.socket() sk.setblocking(False) #会报错,捕获异常 - 异步: - 通过执行回调函数:当达到某个指定的状态之后,自动调用特定函数。
75、什么是域名解析?
把域名解析成ip :先去本地hosts文件中解析,如果没有再去DNS域名解析服务器解析
76、如何修改本地hosts文件?
hosts:网址与ip的关系映射
77、生产者消费者模型应用场景及优势?
创建一个缓冲区,减少了生产者与消费者这件的依赖关系、支持并发、解决了生产者快慢的问题
78、什么是cdn?
用户可以就近取得所需的内容,提高用户访问网站的响应速度。(解决了Internet网络拥挤的状态)
相关技术:负载均衡、缓存、动态内容分发与复制(将静态网页、图像、流媒体复制放入各个cdn中)
79、LVS是什么及作用?
LVS(liunx虚拟服务器):是一个虚拟的服务器集群系统:
LVS主要用于多服务器的负载均衡。它工作在网络层,可以实现高性能,高可用的服务器集群技术
80、keepalived是什么及作用?
Keepalived的作用是检测服务器的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器
作用:
管理LVS负载均衡软件、实现LVS集群节点的状态检查
做web架构的高可用
81、什么是负载均衡?
将请求分发到不同的服务器上去响应,并且让每个服务器的负载达到均衡的状态
种类:
- 基于重定向
- 基于DNS域名解析
- 基于网络层
- 基于数据链路层
- 反向代理
82、实现高可用的方法
- 主从复制
- 分布式集群
- 双机双工
83、公司项目1000用户,QPS=1000 ,如果用户猛增10000w?项目如何提高的并发?
- 数据库读写分离
- 负载均衡
- 设置缓存
84、haproxy是什么以及作用?
haproxy:是一种提供高可用、负载均衡以及基于tcp或http的应用程序代理
作用:
- 提供正向代理、反向代理
- 代理服务器,可以提供缓存功能加速客户端访问,同时可以对缓存数据进行有效性检查
- 内容路由:根据流量以及内容类型将请求转发至特定的服务器
- 转码器:支持压缩功能,将数据以压缩形式发送给客户端
85、Nginx是什么及作用?
1、nginx是一个轻量级的Web服务器(反向代理服务器、负载均衡服务器)
2、作用:
(1)保证内网的安全,可以使用方向代理WAF(Web防火墙)功能,阻止web攻击(大型网站,通常将反向代理作为公网访问地址,Web服务器是内网)
(2)负载均衡,通过反向代理服务器来优化网站的负载,其特点是占有内存少,并发能力强
3、正向代理与反向代理
比喻:a(客户端)、b(代理)、c(服务端)三个人,正向代理是:a通过b向c借钱(a是知道c存在的)
反向代理是:a向b借钱,b向c借钱(a不知道c的存在)
86、什么是rpc及应用场景?
rpc(远程过程调用):可以让程序在不同的内存空间(不同的系统)实现远程数据通信和互相调用
流程:客户端调用rpc接口------>rpc-------->服务端
应用场景:比如两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数或者方法,由于不在一个内存空间,不能直接调用,这时候需要通过就可以应用RPC框架的实现来解决
87、简述 asynio模块的作用和应用场景。
asynio模块可以实现异步网络操作、并发、协程
88、简述 gevent模块的作用和应用场景。
python通过gevent中的greenlet实现协程,
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent自动切换协程,就保证总有greenlet在运行,而不是等待IO。
使用gevent实现单线程并发 爬虫(gevent中的pool或joinall) web聊天室
89、twisted框架的使用和应用?
twisted是一个用python语言编写的事件驱动网络框架,
特点是:内部基于一个事件循环(reactor),当外部事件执行时遇到IO等待则挂起,执行下一个,IO等待完成后返回一个Deferred对象,Deferred对象会自动触发回调机制调用相应的函数处理
数据库
1、列举常见的关系型数据库和非关系型都有那些?
- 关系型(有表结构):Mysql、oracle、sql server 、db2、sqllite、access
- 菲关系(key-value):mongodb、redis、memcache
优缺点:关系型:容易理解(二维表结构)、支持sql复杂查询、支持事务(保持数据一致性)
非关系:数据基于键值对存储、查询速度快,数据没有耦合性、扩展性强、
2、引擎
innodb 支持事务(回滚)、表锁、行锁(select id,name from user where id=2 for update)
myisam 支持全文索引、表锁(- select * from user for update)
3、简述数据库范式?
-
无重复列
-
表中属性必须依赖于主键
-
非主属性相关信息(关联表信息)不能依赖于主键 (消除数据冗余)
4、设计表
权限表、BBS、权限
注意:FK M2M
5、数据操作
多表联查:
select * from tb1,tb2 没有where条件时,笛卡尔乘积效果
left join 以左表为基准,显示所以的内容,右表没有对应项时,显示null
select * from tb1 left join tb2 on tb1.id=tb2.id;
inner join 只显示两张表共同内容
select * from tb1 inner join tb2 on tb1.id=tb2.id;
union 显示两张表所以内容
select * from tb1 left join tb2 on tb1.id=tb2.id union select * from tb2 left join tb1 on tb1.id=tb2.id;
分组函数
select 部门ID,max(id) from 用户表 group by 部门ID having count(id)>3
group by 字段 having 判断条件 (固定语法)分组和聚合函数搭配
6、索引
创建索引:
创建表+索引
create table tb( id int not null primary key
name varchar(32),
pwd varchar(32)
unique tb_pwd (pwd))
普通索引:create index tb_name on tb(name)
联合索引:create index tb_name_age on tb(name,age)
原理:B+/哈希索引 查找速度快;更新速度慢
1、索引一定是为搜索条件的字段创建的
2、innodb表的索引会存放于s1.ibd文件中,而myisam表的索引则会有单独的索引文件table1.MYI
单列:
1、普通索引 index 加速查找
2、唯一索引 unique 加速查找+不能重复
3、主键索引 primary key 加速查找+不能重复+不能为空
多列:
1、联合索引
2、联合唯一索引
3、联合主键索引
联合索引遵从最左前缀原则
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
其它操作:
索引合并:利用多个单例索引查找
覆盖索引:在索引表中就能查到想要的数据
创建了索引,但无法命中
- like '%xx' select * from tb1 where name like '%cn'; - 使用函数 select * from tb1 where reverse(name) = 'wupeiqi'; - or select * from tb1 where nid = 1 or email = 'seven@live.com'; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = 'seven'; select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex' - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where name = 999; - != select * from tb1 where name != 'alex' 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where name > 'alex' 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 - order by select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc;
7、事务
一组sql批量执行,要么全部执行成功、要么全部失败 遵循原子性、一致性、持久性、隔离性
start transaction; 开始事务 增、删、改 update user set balance=900 where name='wsb'; #买支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 update user set balance=1090 where name='ysb'; #卖家拿到90元 commit; 提交事务
rollback; 回滚
8、数据库锁
问题:如何基于数据库实现商城商品计数器?
select * from user for update
乐观锁(读)
悲观锁(写)
8、存储过程、视图、函数、触发器
存储过程、视图、函数、触发器、都是保存在数据库中
触发器:在数据库中对某张表进行“增删改”时,添加一些操作
视图:一张虚拟表,根据SQL语句动态的获取数据集,并命名,下次使用时直接调用名称(只能查)
v = select * from tb where id <1000 select * from v 等同于: select * from (select * from tb where id <1000) as v
存储过程:将常用的sql语句命名保存到数据库中,使用时可以直接调用名称
参数有:in(入参类型) out(出参类型) inout(出入参类型)
函数:在sql语句中使用
- 聚合:max/sum/min/avg
- 时间格式化 date_format
- 字符串拼接 concat
存储过程与函数的区别:
区别:
函数 存储过程
必须有返回值 return 可以通过out、inout返回零各或多个值
不能单独使用,必须作为表达式的一部分 可以作为一个独立的sql语句执行
sql语句中可以直接调用函数 sql中不能调用过程
9、主键和外键的区别?
主键:确定表中一条记录的唯一标识
外键:用于关联另一张表的字段,(通过该字段确定表中记录)
10、char和varchar的区别?
char 固定长度(255)
varchar 变长 (理论65535)
11、MySQL常见的函数?
一、数学函数 ROUND(x,y) 返回参数x的四舍五入的有y位小数的值 RAND() 返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 二、聚合函数(常用于GROUP BY从句的SELECT查询中) AVG(col)返回指定列的平均值 COUNT(col)返回指定列中非NULL值的个数 MIN(col)返回指定列的最小值 MAX(col)返回指定列的最大值 SUM(col)返回指定列的所有值之和 GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果 三、字符串函数 CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5); -> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3); -> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki' 四、日期和时间函数 CURDATE()或CURRENT_DATE() 返回当前的日期 CURTIME()或CURRENT_TIME() 返回当前的时间 DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7) DAYOFMONTH(date) 返回date是一个月的第几天(1~31) DAYOFYEAR(date) 返回date是一年的第几天(1~366) DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE); FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts HOUR(time) 返回time的小时值(0~23) MINUTE(time) 返回time的分钟值(0~59) MONTH(date) 返回date的月份值(1~12) MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE); NOW() 返回当前的日期和时间 QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE); WEEK(date) 返回日期date为一年中第几周(0~53) YEAR(date) 返回日期date的年份(1000~9999) 重点: DATE_FORMAT(date,format) 根据format字符串格式化date值 mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y'); -> 'Sunday October 2009' mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s'); -> '22:23:00' mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00', -> '%D %y %a %d %m %b %j'); -> '4th 00 Thu 04 10 Oct 277' mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00', -> '%H %k %I %r %T %S %w'); -> '22 22 10 10:23:00 PM 22:23:00 00 6' mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V'); -> '1998 52' mysql> SELECT DATE_FORMAT('2006-06-00', '%d'); -> '00' 五、加密函数 MD5() 计算字符串str的MD5校验和 PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。 六、控制流函数 CASE WHEN[test1] THEN [result1]...ELSE [default] END 如果testN是真,则返回resultN,否则返回default CASE [test] WHEN[val1] THEN [result]...ELSE [default]END 如果test和valN相等,则返回resultN,否则返回default IF(test,t,f) 如果test是真,返回t;否则返回f IFNULL(arg1,arg2) 如果arg1不是空,返回arg1,否则返回arg2 NULLIF(arg1,arg2) 如果arg1=arg2返回NULL;否则返回arg1 七、控制流函数小练习 #7.1、准备表 /* Navicat MySQL Data Transfer Source Server : localhost_3306 Source Server Version : 50720 Source Host : localhost:3306 Source Database : student Target Server Type : MYSQL Target Server Version : 50720 File Encoding : 65001 Date: 2018-01-02 12:05:30 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for course -- ---------------------------- DROP TABLE IF EXISTS `course`; CREATE TABLE `course` ( `c_id` int(11) NOT NULL, `c_name` varchar(255) DEFAULT NULL, `t_id` int(11) DEFAULT NULL, PRIMARY KEY (`c_id`), KEY `t_id` (`t_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of course -- ---------------------------- INSERT INTO `course` VALUES ('1', 'python', '1'); INSERT INTO `course` VALUES ('2', 'java', '2'); INSERT INTO `course` VALUES ('3', 'linux', '3'); INSERT INTO `course` VALUES ('4', 'web', '2'); -- ---------------------------- -- Table structure for score -- ---------------------------- DROP TABLE IF EXISTS `score`; CREATE TABLE `score` ( `id` int(11) NOT NULL AUTO_INCREMENT, `s_id` int(10) DEFAULT NULL, `c_id` int(11) DEFAULT NULL, `num` double DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of score -- ---------------------------- INSERT INTO `score` VALUES ('1', '1', '1', '79'); INSERT INTO `score` VALUES ('2', '1', '2', '78'); INSERT INTO `score` VALUES ('3', '1', '3', '35'); INSERT INTO `score` VALUES ('4', '2', '2', '32'); INSERT INTO `score` VALUES ('5', '3', '1', '66'); INSERT INTO `score` VALUES ('6', '4', '2', '77'); INSERT INTO `score` VALUES ('7', '4', '1', '68'); INSERT INTO `score` VALUES ('8', '5', '1', '66'); INSERT INTO `score` VALUES ('9', '2', '1', '69'); INSERT INTO `score` VALUES ('10', '4', '4', '75'); INSERT INTO `score` VALUES ('11', '5', '4', '66.7'); -- ---------------------------- -- Table structure for student -- ---------------------------- DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `s_id` varchar(20) NOT NULL, `s_name` varchar(255) DEFAULT NULL, `s_age` int(10) DEFAULT NULL, `s_sex` char(1) DEFAULT NULL, PRIMARY KEY (`s_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of student -- ---------------------------- INSERT INTO `student` VALUES ('1', '鲁班', '12', '男'); INSERT INTO `student` VALUES ('2', '貂蝉', '20', '女'); INSERT INTO `student` VALUES ('3', '刘备', '35', '男'); INSERT INTO `student` VALUES ('4', '关羽', '34', '男'); INSERT INTO `student` VALUES ('5', '张飞', '33', '女'); -- ---------------------------- -- Table structure for teacher -- ---------------------------- DROP TABLE IF EXISTS `teacher`; CREATE TABLE `teacher` ( `t_id` int(10) NOT NULL, `t_name` varchar(50) DEFAULT NULL, PRIMARY KEY (`t_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of teacher -- ---------------------------- INSERT INTO `teacher` VALUES ('1', '大王'); INSERT INTO `teacher` VALUES ('2', 'alex'); INSERT INTO `teacher` VALUES ('3', 'egon'); INSERT INTO `teacher` VALUES ('4', 'peiqi'); #7.2、统计各科各分数段人数.显示格式:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60] select score.c_id, course.c_name, sum(CASE WHEN num BETWEEN 85 and 100 THEN 1 ELSE 0 END) as '[100-85]', sum(CASE WHEN num BETWEEN 70 and 85 THEN 1 ELSE 0 END) as '[85-70]', sum(CASE WHEN num BETWEEN 60 and 70 THEN 1 ELSE 0 END) as '[70-60]', sum(CASE WHEN num < 60 THEN 1 ELSE 0 END) as '[ <60]' from score,course where score.c_id=course.c_id GROUP BY score.c_id;
12、分页
select * form tb limit 0,5
limit 起始,数量
数据量过大,页数越大,查询速度越慢,因为页数越大,数据id就越大,查询时就会从头开始扫描数据,
解决办法:
方案一:
1、记录当期页,数据ID的最大值、最小值, 2、翻页查询时,先根据数据ID筛选数据,在limit查询
select * from (select * from tb where id > 22222222) as B limit 0,10
如果用户自己修改url上的页码,我们可以参考rest-frameword中的分页,对url中的页码进行加密处理
方案二:
可以根据实际业务需求,只展示部分数据(只显示200-300页的数据)
13、慢日志查询
slow_query_log = ON 是否开启慢日志记录 long_query_time = 2 时间限制,超过此时间,则记录 slow_query_log_file = /usr/slow.log 日志文件 log_queries_not_using_indexes = ON 为使用索引的搜索是否记录
14、数据库导入导出
导入:mysqldump -u root -p db > F:\db.txt
导出:mysqldump -u root -p db(存在的) < F:\db.txt;
15、执行计划
explain select * from tb; #查看sql语句执行速度
16、优化方案
- 不用 select *
- 固定长度字段列,往前放
- char(固定长度)和varchar
- 固定数据放入内存:choice
- 读写分离,利用数据库的主从进行分离:主,用于删除、修改更新;从,查。
- 分库,当数据库中表太多,将表分到不同的数据库;例如:1w张表
- 分表
- 水平分表,将某些列拆分到另外一张表;例如:博客+博客详细
- 垂直分表,将历史信息分到另外一张表中;例如:账单
- 缓存:利用redis、memcache,将常用的数据放入缓存中
-查询一条数据
select * from tb where name='alex' limit 1
-text类型
为前面几个字符串创建索引
17、问题
在对name做了唯一索引前提下,简述以下区别:
1、 select * from tb where name = ‘Oldboy-Wupeiqi’
2、select * from tb where name = ‘Oldboy-Wupeiqi’ limit 1 速度快
18、秒杀程序设计,如何不会出现超卖
1、添加事务,
加锁
修改数据并判断是否为0
释放锁
提交事务
2、将秒杀商品放入redis中利用watch实现,
3、使用队列
处理并发:
1、前端:扩容(加机器)、 限流(限制ip访问次数)、静态化(页面最大程度使用静态,cdn)
2、后端:【内存】+【排队】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号