爬虫初识
爬虫的定义:
向网站发起请求,获取免费资源后分析并提取有用数据的程序
爬虫是一种应用程序,用于从互联网中获取有价值的数据,从本质上来看,属于client客户端程序
互联网是由不同的计算机通过某种介质相互连接组成
互联网是为了使得不同计算机之间可以交换数据
上网指的是,连接到互联网中,获取需要的数据
爬虫的原理:
模拟浏览器发送请求->获取服务器返回的数据->解析数据,只提取有用的数据->存放于数据库或文件中
HTTP协议
HTTP协议是基于请求响应模型,我们在编写爬虫的时候,要关注的点就是请求 1.url 2.请求方法: get post 3.状态码 200 请求成功 3xx 重定向 4xx 客户端发送的请求有问题 5xx 服务器端发生了错误 4.请求参数: get参数放在URL后 post参数放在请求体中body中 5.请求头 cookie:用于识别用户的身份,通常在访问一些私有的页面时需要使用cookie User-Agent:用户代理,用于标识是由什么客户端发起的请求 referer:用于判断用户是从哪个链接跳过来的 6.请求体: 仅当请求方法为post时才有请求体 7.响应头 location:当状态码为3xx的时候,这个参数是有用的 8.响应体 1.html 使用re或者其他模块来解析 2.二进制 直接写入文件 3.json 反序列化即可
爬取简单的百度首页
import requests
url = 'https://www.baidu.com'
res = requests.get(url, ) # bytes格式
print(res.text) # str
# print(res.content)
HTTP请求分析
首先要明确的是:爬虫的核心原理就是模拟浏览器发送HTTP协议来获取服务器上的数据,那么要想服务器接受你的请求,则必须将自己的请求伪装的足够像,这就需要我们去分析浏览器是如何发送的HTTP请求
其次:HTTP协议是基于请求响应模型的,客户端发送请求到服务器,服务器接受请求,处理后返回响应数据,需要关注的重点在于请求数据,只有服务器认为合格合法的请求才会得到服务器的响应。
利用chrome开发者工具来分析请求
chrome浏览器提供强大的开发者工具我们可以利用它来查看浏览器与服务器的整个通讯过程

上图划出了常用的几个操作,如清空请求,保留日志等等,另一个常用操作就是清空cookie信息
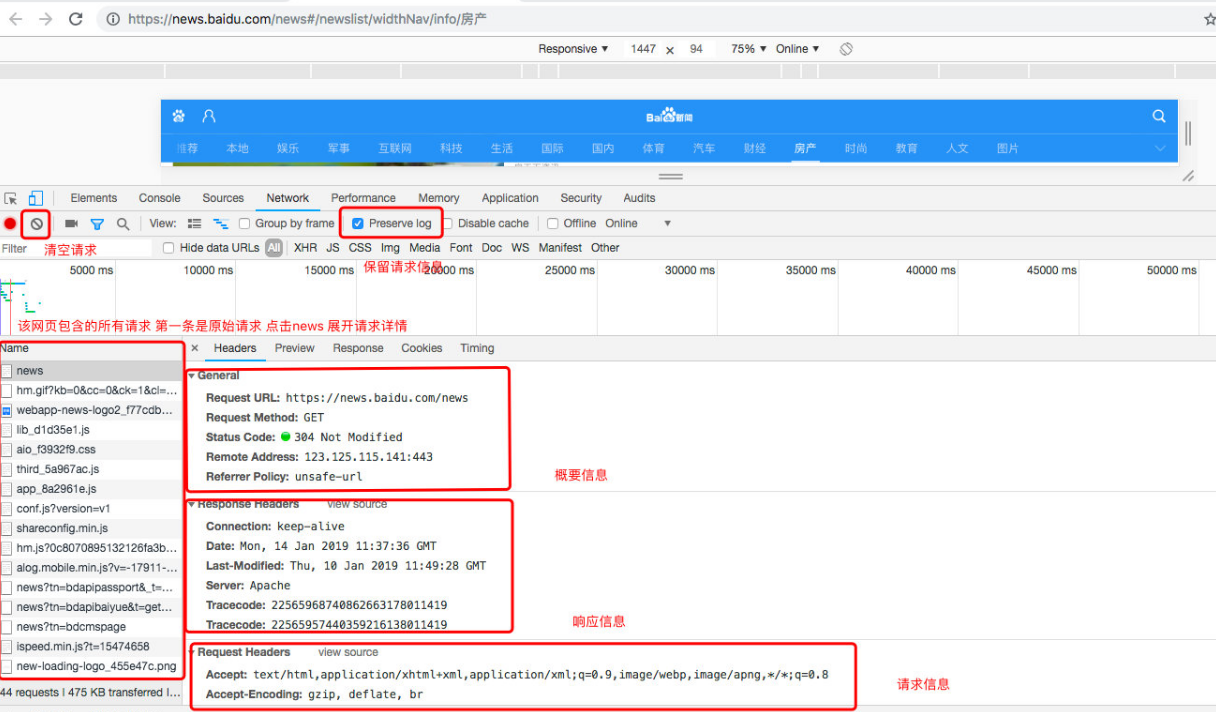
请求流程分析
请求地址
浏览器发送的请求URL地址
请求方法
get 中文需要URL编码,参数跟在地址后面
post 参数放在body中
请求头

cookie,需要登录成功才能访问的页面就需要传递cookie,否则则不需要cookie
user-agent,用户代理,验证客户端的类型
referer,引用页面,判断是从哪个页面点击过来的
请求体

只在post请求时需要关注,通常post请求参数都放在请求体中,例如登录时的用户名和密码
响应头

**location**:重定向的目标地址,仅 在状态码为3XX时出现,需要考虑重定向时的方法,参数等。。,浏览器会自动重定向,request模块也会。
**set-cookie**:服务器返回的cookie信息,在访问一些隐私页面是需要带上cookie
响应体
服务器返回的数据,可能以下几种类型
**HTML格式的静态页面** 需要解析获取需要的数据
**json个格式的结构化数据** 直接就是纯粹的数据
**二进制数据** 通过文件操作直接写入文件
get请求:爬取梨视频
# 1.爬取首页数据,解析获取视频的详情链接
# 2.遍历每一个详情链接,并访问
# 3.从详情页面解析得到需要的数据 (视频链接,标题,详情,时间,收藏次数)
import requests
import re
import os
from threading import Thread
from concurrent.futures import ThreadPoolExecutor
base_url = "https://www.pearvideo.com/"
def get_index():
res = requests.get(base_url,headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"referer": "https: // www.baidu.com / link?url = fUq54ztdrrLaIUXa - p6B9tuWXC3byFJCyBKuvuJ_qsPw8QLrWIfekFKGgmhqITyF & wd = & eqid = c5366da10000199a000000025c45768a"
})
return res.text
def parser_index(text):
urls = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">',text)
urls = [base_url + i for i in urls]
# print(urls)
return urls
def get_details(url):
res = requests.get(url)
print(res.status_code)
return res.text
def parser_details(text):
# 视频的地址
video_url = re.search(r'srcUrl="(.*?\.mp4)"',text).group(1)
# 标题
title = re.search('<h1 class="video-tt">(.*?)</h1>',text).group(1)
# 详情
content = re.search('<div class="summary">(.*?)</div>',text).group(1)
# 时间
date = re.search('<div class="date">(.*?)</div>', text).group(1)
# 点赞数量
count = re.search('<div class="fav" data-id=".*?">(.*?)</div>', text).group(1)
return {"video_url":video_url,"title":title,"content":content,"date":date,"count":count}
def download_video(url,title):
data = requests.get(url)
if not os.path.exists("videos"):
os.makedirs("videos")
filename = os.path.join("videos",title)+".mp4"
filename = filename.replace(":","_")
with open(filename,"wb") as f:
f.write(data.content)
print("%s download finished!" % title)
if __name__ == '__main__':
pool = ThreadPoolExecutor(5)
data = get_index()
urls = parser_index(data)
for i in urls:
t = get_details(i)
dic = parser_details(t)
# Thread(target=download_video,args=(dic["video_url"],dic["title"])).start()
pool.submit(download_video,dic["video_url"],dic["title"])
print("submit task",dic["title"])
print("submit finished")
# reqType=5 固定
# categoryId 分类id
# start 从第几个开始
# 1.爬取首页数据,解析获取视频的详情链接
# 2.遍历每一个详情链接,并访问
# 3.从详情页面解析得到需要的数据(视频链接,标题,详情,时间,收藏次数)
import requests
import re
import os
from concurrent.futures import ThreadPoolExecutor
from threading import Thread
base_url = 'https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId={id}&start={start}'
# 指定请求的页数
page = 2
# 请求的分类
categoryId = 1
def get_data(start):
url = base_url.format(id=categoryId, start=start)
res = requests.get(url)
return res.text
def parser_index(text):
base_url='https://www.pearvideo.com/'
urls = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', text)
urls = [base_url + i for i in urls]
# print(urls)
return urls
def get_details(url):
res = requests.get(url)
print(res.status_code)
# print(res.text)
return res.text
def parser_details(text):
# 视频的地址
video_url = re.search(r'srcUrl="(.*?\.mp4)"', text).group(1)
# 标题
title = re.search('<h1 class="video-tt">(.*?)</h1>', text).group(1)
# 详情
content = re.search('<div class="summary">(.*?)</div>', text).group(1)
# 时间
date = re.search('<div class="date">(.*?)</div>', text).group(1)
# 点赞数量
count = re.search('<div class="fav" data-id=".*?">(.*?)</div>', text).group(1)
return {"video_url": video_url, "title": title, "content": content, "date": date, "count": count}
def download_video(url, title):
data = requests.get(url)
if not os.path.exists("videos"):
os.makedirs("videos")
filename = os.path.join("videos", title) + ".mp4"
# filename = filename.replace(":", ")
with open(filename, "wb") as f:
f.write(data.content)
print("%s download finished!" % title)
if __name__ == '__main__':
pool=ThreadPoolExecutor(5)
for i in range(page):
data=get_data(i*12)
urls=parser_index(data)
for url in urls:
res=get_details(url)
dic=parser_details(res)
print(dic)
pool.submit(download_video,dic['video_url'],dic['title'])
request模块的使用
get请求,请求参数
1.参数拼接时中文需要URLEncode,可以使用urllib中的编码函数来完成
```python
from urllib.parse import urlencode
import requests
params = {"wd":"美女"}
# 必须以字典类型传入需要编码的数据 得到拼接收的参数字符串
res = urlencode(params,encoding="utf-8")
url = "https://www.baidu.com/s"
url = url+"?"+res # 拼接参数
response = requests.get(url)
with open("test.html","wb") as f:
f.write(response.content)
```
2.也可以直接将请求参数传给get的函数的params参数,get方法会自动完成编码
import requests
# 参数字典
params = {"wd":"美女"}
url = "https://www.baidu.com/s"
# 直接传给params参数
response = requests.get(url,params=params)
with open("test.html","wb") as f:
f.write(response.content)
上述的代码无法请求完成的数据 因为百度服务器有限制,必须制定用户代理,user-agent为浏览器才行
添加请求头
import requests
params = {"wd":"美女"}
url = "https://www.baidu.com/s"
headers = {
"user-agent" : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36'
}
response = requests.get(url,params=params,headers=headers)
with open("test.html","wb") as f:
cookies
可以在headers中直接添加键值对也可以单独使用get方法的cookies参数
python
url = "https://github.com/yangyuanhu"
headers = {
"User-Agent" : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36',
"Cookie":"_octo=GH1.1.1155792533.1532919557; _ga=GA1.2.1847433334.1534242542; has_recent_activity=1; user_session=Z5AQmC_Wv4wvM-_Nc3Bj0PQn6nITSonDcPkw4GZ1g0jFIqbe; __Host-user_session_same_site=Z5AQmC_Wv4wvM-_Nc3Bj0PQn6nITSonDcPkw4GZ1g0jFIqbe; logged_in=yes; dotcom_user=yangyuanhu; tz=Asia%2FShanghai; _gat=1; _gh_sess=eERwWHk1NVBjOEhIRmxzckcrcWlpVCtUM2hWL0prNlIyNXdTdC9ab0FSZWR5MEZlYW5OVGNoTEdJQUN0K0xkNXVmTEVpK2RRU1VZTUF6NkJHM1JMejNtaVhReXg2M3Vsb0JvcG8vNDNENjNBcXVvcFE4Tmp4SFhpQ3Z3S2ZZZEIwTGNkVW5BR01qVHlCNEFqTnZFcllhN3NwT1VJblZYWElLOGowN3ZaZVpZTFVHQlFtZkh3K1hnclBWalB1Mk1XLS1wNjFjMlBxUHljU2paK2RXU3M5eDB3PT0%3D--8cdf657174d2acac7cc0459da667accc8a2d0f5e",
"Referer": "https://github.com/"
}
response = requests.get(url,headers=headers)
with open("test.html","wb") as f:
f.write(response.content)
# 使用cookies参数 注意需要拆分为单独的键值对
#response = requests.get(url,headers=headers,cookies={"_octo":"GH1.1.1155792533.1532919557"})
POST请求
模拟登录流程并爬取github私有页面
1.请求登陆页面, 获取token,cookie
2.发出登陆的post请求,将用户名密码和token放在请求体中,cookie放在请求头中
import requests
import re
login_url = 'https://github.com/login'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
res1 = requests.get(login_url, headers=headers)
print(res1.status_code)
# 从响应体中获取token
token = re.search('name="authenticity_token" value="(.*?)"', res1.text).group(1)
print(token)
# 保存cookie
login_cookie = res1.cookies.get_dict()
print(login_cookie)
# 发送登录请求
res2 = requests.post("https://github.com/session",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"},
cookies = login_cookie,
data={
"commit": "Sign in",
"utf8": "✓",
"authenticity_token": token,
"login": "2120176410@qq.com",
"password": "cao75315 9"},
# 是否允许自动重定向,获取登录后的页面需要重定向
allow_redirects = False)
print(res2.status_code)
# 用户登录成功后的cookie
user_cookie=res2.cookies.get_dict()
res3=requests.get('https://github.com/settings/profile',cookies=user_cookie,headers=headers)
print(res3.status_code)
print(res3.text)
# "https://github.com/settings/profile"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号