Mycat配置分库分表(垂直分库、水平分表)、全局序列
1. Mycat相关文章
Linux安装Mycat1.6.7.4并实现Mysql数据库读写分离简单配置
Linux安装Mysql8.0.20并配置主从复制(一主一从,双主双从)
Docker部署Mysql8.0.20并配置主从复制
2. 其他分库分表方案
3. 垂直拆分--分库
一个庞大的业务系统对应一个数据库,数据库中存在大量的表,必然影响系统体验度。因此,需要按照业务将表进行拆分成多个业务库,每个业务库只存储相关的业务表,即可减轻单个数据库的压力。
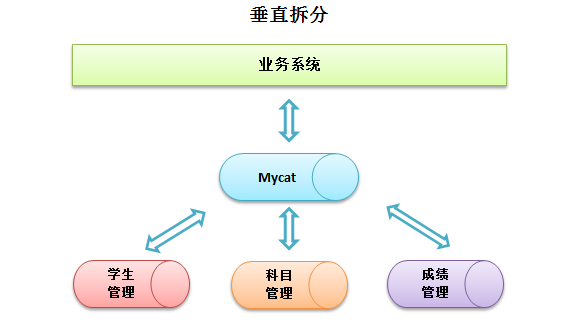
根据图中,将教务管理数据库拆分成:学生管理库、课程管理库和成绩管理库,每个库仅存与之关联的业务表。业务系统访问Mycat逻辑库,实则还是访问一个数据库。
- 拆分原则
拆分后的数据库可能存在多个主机的数据库服务中,因此在关联查询时,不可能将不同的数据库服务进行关联,因此需要将业务表进行归类,将关联紧密的表划分到一个数据库。
对于一个教务管理系统来说,学生表将被划分到学生管理库,课程表、课程详情表和课程字典表将划分到课程管理库中。 - 主机划分
| 服务器IP | 备注 |
|---|---|
| 192.168.133.130 | 数据库-1 |
| 192.168.133.131 | 数据库-2 |
| 192.168.133.132/192.168.133.130 | Mycat |
- 安装Mysql和Mycat
安装Mysql请参考:Linux安装Mysql8.0.11 或 Docker部署Mysql8.0.20并配置主从复制 或 Docker 安装并部署Tomcat、Mysql8、Redis
安装Mycat请参考:Linux安装Mycat1.6.7.4并实现Mysql数据库读写分离简单配置 - 配置分库
修改Mycat的schema.xml文件:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema
xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.130:3306" user="root" password="123456"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.131:3306" user="root" password="123456"></writeHost>
</dataHost>
</mycat:schema>
对于数据库education,仅把表t_student划分到第二个节点,即主机2上,其余的表t_schedule、t_schedule_detail、t_subject_dict默认划分到第一个节点。
- 创建数据库
分别在两个主机上的Mysql上创建数据库education。
create database education;
- 启动Mycat
# 进入Mycat的bin目录
./mycat console
- 创建表
在服务器连接Mycat或者使用Navicat等工具连接。
# 服务器连接
mysql -umycat -p -h192.168.133.132 -P8066
# 或者使用其他工具连接
# 在Mycat上创建表
DROP TABLE IF EXISTS `t_student`;
CREATE TABLE `t_student` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NULL DEFAULT NULL COMMENT '学生姓名',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '学生信息表';
DROP TABLE IF EXISTS `t_schedule`;
CREATE TABLE `t_schedule` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`subject_code` varchar(20) NULL DEFAULT NULL COMMENT '课程编码',
`student_id` int(0) NULL DEFAULT NULL COMMENT '学生ID',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB COMMENT = '课程信息表';
DROP TABLE IF EXISTS `t_schedule_detail`;
CREATE TABLE `t_schedule_detail` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`class_time` datetime(0) NULL DEFAULT NULL COMMENT '上课时间',
`schedule_id` int(0) NULL DEFAULT NULL COMMENT '课程ID',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB COMMENT = '课程明细表';
DROP TABLE IF EXISTS `t_subject_dict`;
CREATE TABLE `t_subject_dict` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`subject_code` varchar(20) NULL DEFAULT NULL COMMENT '课程编码',
`subject_name` varchar(50) NULL DEFAULT NULL COMMENT '课程名称',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '课程字典表';
- 查询表
# 分别在两台主机上查询表
mysql -uroot -p -h192.168.133.130 -P3306
use education;
show tables;
# 在Mycat上查询表
mysql -uroot -p -h192.168.133.132 -P8066
use TESTDB;
show tables;
# 查询表记录
select * from t_student;
select * from t_schedule;
select * from t_schedule_detail;
select * from t_subject_dict;
4. 水平拆分--分表
水平拆分指的是对一张表根据某个字段按照某种规则进行拆分,要求每个数据库都存在该表,但一个数据库只存储符合规则的那些数据,在单表数据量大的情况下,极大效率的减少数据库压力,提高访问速度。
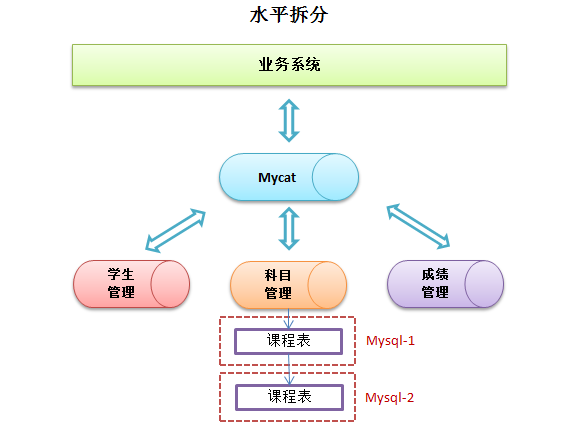
根据图中,将课程管理中的课程表等相关表进行拆分,拆分到不同的数据库服务中。
- 拆分原则
Mysql中,当单表的数据量超过500万行或者大于2GB时,就需要考虑分库分表。
对于课程表来说,根据学生ID规则进行拆分较为合适,可以将每个学生的课程信息划分到一个数据库服务中,便于和其他表关联查询。 - 服务器划分
和垂直拆分时服务器划分方式相同,即使用此服务器即可完成测试。
| 服务器IP | 备注 |
|---|---|
| 192.168.133.130 | 数据库-1 |
| 192.168.133.131 | 数据库-2 |
| 192.168.133.132/192.168.133.130 | Mycat |
- 配置分表
修改Mycat的schema.xml文件,设置课程表t_schedule分表规则student_id_mod_rule(名称自定义):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC">
</writeHost>
</dataHost>
</mycat:schema>
修改Mycat的srule.xml文件,配置课程表分表规则student_rule:
# 添加规则
<tableRule name="student_id_mod_rule">
<rule>
<columns>student_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
# 修改mod-long规则
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
新增tableRule节点,配置列和规则算法。
修改mod-long算法的count数值,两台主机即为2。
- 在另一台主机上创建课程信息表
CREATE TABLE `t_schedule` (
`id` int NOT NULL AUTO_INCREMENT,
`subject_code` varchar(20) DEFAULT NULL COMMENT '课程编码',
`student_id` int DEFAULT NULL COMMENT '学生ID',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='课程信息表';
- 启动Mycat
# 进入Mycat的bin目录
./mycat console
- 插入数据
在服务器连接Mycat或者使用Navicat等工具连接。
insert into t_schedule(id, subject_code, student_id) values(1, 'YW', 1);
insert into t_schedule(id, subject_code, student_id) values(2, 'SX', 1);
insert into t_schedule(id, subject_code, student_id) values(3, 'YY', 1);
insert into t_schedule(id, subject_code, student_id) values(4, 'YW', 2);
insert into t_schedule(id, subject_code, student_id) values(5, 'SX', 2);
insert into t_schedule(id, subject_code, student_id) values(6, 'YY', 2);
- 测试
# 使用Mycat查询,6条数据
select * from t_schedule;
# 使用Mysql-1查询,3条数据,student_id均为2
select * from t_schedule;
# 使用Mysql-2查询,3条数据,student_id均为1
select * from t_schedule;
- 关联表分表
与课程表相关联的课程详情表在关联查询时可能因为外联的数据不在同一个Mysql服务中,因此课程详情表需要根据课程表进行拆分,将课程ID相同的数据划分到和课程信息相同的一个Mysql服务中。
Mycat借鉴了NewSQL领域的新秀Foundation DB的设计思路,Foundation DB创新性的提
出了Table Group的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了
JION的效率和性能问题,根据这一思路,提出了基于E-R关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。 - 配置分表
修改Mycat的schema.xml文件,增加课程表t_schedule的子表t_schedule_detail:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule">
<childTable name="t_schedule_detail" primaryKey="id" joinKey="schedule_id" parentKey="id" />
</table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
</mycat:schema>
- 在另一台主机上创建课程详情表
CREATE TABLE `t_schedule_detail` (
`id` int NOT NULL AUTO_INCREMENT,
`class_time` datetime DEFAULT NULL COMMENT '上课时间',
`schedule_id` int DEFAULT NULL COMMENT '课程ID',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='课程明细表';
- 启动Mycat
# 进入Mycat的bin目录
./mycat console
- 插入数据
在服务器连接Mycat或者使用Navicat等工具连接。
insert into t_schedule_detail(id, class_time, schedule_id) values (1, now(), 1);
insert into t_schedule_detail(id, class_time, schedule_id) values (2, now(), 2);
insert into t_schedule_detail(id, class_time, schedule_id) values (3, now(), 3);
insert into t_schedule_detail(id, class_time, schedule_id) values (4, now(), 4);
insert into t_schedule_detail(id, class_time, schedule_id) values (5, now(), 5);
insert into t_schedule_detail(id, class_time, schedule_id) values (6, now(), 6);
- 测试
# 使用Mycat查询,6条数据
select a.*, b.class_time, b.schedule_id from t_schedule a right join t_schedule_detail b on a.id = b.schedule_id order by id;
# 使用Mysql-1查询,3条数据,student_id均为2
select a.*, b.class_time, b.schedule_id from t_schedule a right join t_schedule_detail b on a.id = b.schedule_id order by id;
# 使用Mysql-2查询,3条数据,student_id均为1
select a.*, b.class_time, b.schedule_id from t_schedule a right join t_schedule_detail b on a.id = b.schedule_id order by id;
- 配置全局表
根据业务将业务表进行拆分后,数据被划分到不同的数据分片中,但是与业务相关联的数据字典表的关联问题也需要解决。
考虑到数据字典表等特征表具有以下特点:(1)数据量小;(2)数据变化不频繁等特点,因此可以采用数据冗余的方式,将此类型的表拆分到每一个数据片中。当插入数据时,对所有节点进行插入操作,确保数据的一致性;当单表查询时,仅从一个数据片中查询;当与其他表关联时,与业务表相同的数据片中的表进行关联。 - 配置分表
修改Mycat的schema.xml文件,增加课程字典表t_subject_dict为全局表:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule">
<childTable name="t_schedule_detail" primaryKey="id" joinKey="schedule_id" parentKey="id" />
</table>
<table name="t_subject_dict" dataNode="dn1,dn2" type="global" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
</mycat:schema>
- 在另一台主机上创建课程字典表
CREATE TABLE `t_subject_dict` (
`id` int NOT NULL AUTO_INCREMENT,
`subject_code` varchar(20) DEFAULT NULL COMMENT '课程编码',
`subject_name` varchar(50) DEFAULT NULL COMMENT '课程名称',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='课程字典表';
- 启动Mycat
# 进入Mycat的bin目录
./mycat console
- 插入数据
在服务器连接Mycat或者使用Navicat等工具连接。
insert into t_subject_dict(id, subject_code, subject_name) values(1, 'YW', '语文');
insert into t_subject_dict(id, subject_code, subject_name) values(2, 'SX', '数学');
insert into t_subject_dict(id, subject_code, subject_name) values(3, 'YY', '英语');
- 测试
# 使用Mycat查询,3条数据
select * from t_subject_dict;
# 使用Mysql-1查询,3条数据
select * from t_subject_dict;
# 使用Mysql-2查询,3条数据
select * from t_subject_dict;
5. 常用分片规则
- 取模
上述对课程表的分表规则即为取模。 - 分片枚举
枚举尽可能的规则ID,使得数据在插入时按照枚举的规则划分到对应的数据片中。这类表具有数据固定且数据量小等特点。例如:区域表,全国区域固定,按照区域编码进行枚举,将特定的区域已经相关联的区域业务数据划分到同一个数据片中。
修改Mycat的schema.xml文件,增加区域表t_area并配置规则sharding_by_area_code(名称自定义):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule">
<childTable name="t_schedule_detail" primaryKey="id" joinKey="schedule_id" parentKey="id" />
</table>
<table name="t_subject_dict" dataNode="dn1,dn2" type="global" ></table>
<table name="t_area" dataNode="dn1,dn2" rule="sharding_by_area_code" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
</mycat:schema>
修改Mycat的rule.xml,配置规则:
# 新增规则
<tableRule name="sharding_by_area_code">
<rule>
<columns>area_code</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
# 修改算法hash-int
# mapFile => 标识配置文件名称
# type => 0为int类型,非0为String类型
# defaultNode => 小于0则为不配置默认节点,大于等于0标识配置对应的数据节点。当匹配不到对应的数据节点时,则使用默认的数据节点,若不配置默认数据节点,则报错
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>
# 修改partition-hash-int.txt,配置枚举
029=0
0913=1
# 启动Mycat
# 进入Mycat的bin目录
./mycat console
# 使用Mycat创建区域表
CREATE TABLE `t_area` (
`id` int NOT NULL AUTO_INCREMENT,
`area_code` varchar(20) DEFAULT NULL COMMENT '区域编码',
`area_name` varchar(50) DEFAULT NULL COMMENT '区域名称',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='区域信息表';
# 插入数据
insert into t_area(id, area_code, area_name) values(1, '010', '北京');
insert into t_area(id, area_code, area_name) values(2, '029', '西安');
insert into t_area(id, area_code, area_name) values(3, '0913', '渭南');
# 测试,查询数据
# 使用Mycat查询,3条数据
select * from t_area;
# 使用Mysql-1查询,2条数据,area_code为010、029
select * from t_area;
# 使用Mysql-2查询,1条数据,area_code为0913
select * from t_area;
- 范围约定
限定某些范围的数据被划分到指定的数据片中。例如:学生成绩表,根据成绩区间可以划分到不同的数据片中。
修改Mycat的schema.xml文件,增加成绩表t_score并配置规则sharding_by_score(名称自定义):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule">
<childTable name="t_schedule_detail" primaryKey="id" joinKey="schedule_id" parentKey="id" />
</table>
<table name="t_subject_dict" dataNode="dn1,dn2" type="global" ></table>
<table name="t_area" dataNode="dn1,dn2" rule="sharding_by_area_code" ></table>
<table name="t_score" dataNode="dn1,dn2" rule="sharding_by_score" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
</mycat:schema>
修改Mycat的rule.xml,配置规则:
# 新增规则
<tableRule name="sharding_by_score">
<rule>
<columns>score</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
# 修改算法rang-long
# mapFile => 标识配置文件名称
# defaultNode => 小于0则为不配置默认节点,大于等于0标识配置对应的数据节点。当匹配不到对应的数据节点时,则使用默认的数据节点,若不配置默认数据节点,则报错
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
# 修改autopartition-long.txt,约定范围
0-60=0
61-100=1
# 启动Mycat
# 进入Mycat的bin目录
./mycat console
# 使用Mycat创建成绩表
CREATE TABLE `t_score` (
`id` int NOT NULL AUTO_INCREMENT,
`score` int DEFAULT 0 COMMENT '总成绩',
`student_id` int DEFAULT NULL COMMENT '区域名称',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='成绩信息表';
# 插入数据
insert into t_score(id, score, student_id) values(1, 54, 1);
insert into t_score(id, score, student_id) values(2, 98, 2);
# 测试,查询数据
# 使用Mycat查询,2条数据
select * from t_score;
# 使用Mysql-1查询,1条数据,成绩<60
select * from t_score;
# 使用Mysql-2查询,1条数据,成绩>=60
select * from t_score;
- 按照日期分片
按照日期(例如:天)将数据划分到不同的数据片中。例如:日志表,可以按照天将日志划分到不同的数据分区,便于查询和删除历史过期日志。
修改Mycat的schema.xml文件,增加成绩表t_log并配置规则sharding_by_date(名称自定义):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_student" dataNode="dn2"></table>
<table name="t_schedule" dataNode="dn1,dn2" rule="student_id_mod_rule">
<childTable name="t_schedule_detail" primaryKey="id" joinKey="schedule_id" parentKey="id" />
</table>
<table name="t_subject_dict" dataNode="dn1,dn2" type="global" ></table>
<table name="t_area" dataNode="dn1,dn2" rule="sharding_by_area_code" ></table>
<table name="t_score" dataNode="dn1,dn2" rule="sharding_by_score" ></table>
<table name="t_log" dataNode="dn1,dn2" rule="sharding_by_date" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="education" />
<dataNode name="dn2" dataHost="host2" database="education" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.133.131:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.133.130:3306" user="root" password="3edc#EDC"></writeHost>
</dataHost>
</mycat:schema>
修改Mycat的rule.xml,配置规则:
# 新增规则
<tableRule name="sharding_by_date">
<rule>
<columns>log_date</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
# 新增算法sharding-by-data
#dateFormat => 日期格式
#sBeginDate => 开始日期
#sEndDate => 结束日期,当日期到达结束时间后,从开始分片插入
#sPartionDay :分区天数,即默认从开始日期算起,分隔2天一个分区
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-10-10</property>
<property name="sEndDate">2020-10-13</property>
<property name="sPartionDay">2</property>
</function>
# 启动Mycat
# 进入Mycat的bin目录
./mycat console
# 使用Mycat创建日志表
CREATE TABLE `t_log` (
`id` int NOT NULL AUTO_INCREMENT,
`log_title` varchar(50) NULL DEFAULT NULL COMMENT '日志标题',
`log_date` date NULL DEFAULT NULL COMMENT '日志时间',
PRIMARY KEY (`id`) USING BTREE
) COMMENT='日志信息表';
# 插入数据
insert into t_log(id, log_title, log_date) values(1, '测试1', '2020-10-10');
insert into t_log(id, log_title, log_date) values(2, '测试2', '2020-10-11');
insert into t_log(id, log_title, log_date) values(3, '测试3', '2020-10-12');
insert into t_log(id, log_title, log_date) values(4, '测试4', '2020-10-13');
insert into t_log(id, log_title, log_date) values(5, '测试5', '2020-10-14');
insert into t_log(id, log_title, log_date) values(6, '测试6', '2020-10-15');
# 测试,查询数据
# 使用Mycat查询,6条数据
select * from t_log order by id;
# 使用Mysql-1查询,4条数据,日志日期为10、11、14、15
select * from t_log order by id;
# 使用Mysql-2查询,2条数据,日志日期为12、13
select * from t_log order by id;
6. 全局序列
在实现数据库分库分表后,数据库自增主键如何保证唯一性是需要解决的必要问题。Mycat提供了sequence,使用本地配置或数据库配置等多种方式保证自增主键的唯一性。
- 本地文件方式(不建议使用)
Mycat将sequence值配置到sequence_conf.properties配置文件中,当使用sequence后,更新配置文件中sequence的值。
此方式优点是加载速度快,缺点是抗风险能力差,Mycat宕机后,无法从本地配置文件读取sequence值。 - 数据库方式(推荐)
在数据库上创建一张表来作为主键计数,如果采用每次使用时再查询效率不高,因此采用匹配查询的方式,即每次Mycat会预加载一部分数据(例如100个),当使用完后,再次取下一部分数据(再取100个)。
此方式效率高,但是当Mycat宕机后,加载到Mycat内存中的数据就会丢失,因此每次当时重启后,Mycat舍弃之前取的数据,而是直接从数据库获取下一部分数据。
创建序列脚本:
# 在Mysql-1上创建全局序列表
CREATE TABLE mycat_sequence (
name VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY (name)
) COMMENT 'Mycat全局序列表';
# 设置全局序列需要的函数
DELIMITER $
CREATE FUNCTION mycat_seq_currval (
seq_name VARCHAR(50)
) RETURNS VARCHAR(64) DETERMINISTIC BEGIN
DECLARE
retval VARCHAR (64);
SET retval = "-999999999,null";
SELECT
CONCAT(
CAST( current_value AS CHAR ),
",",
CAST( increment AS CHAR )
) INTO retval
FROM
MYCAT_SEQUENCE
WHERE
NAME = seq_name;
RETURN retval;
END $
DELIMITER;
DELIMITER $
CREATE FUNCTION mycat_seq_setval (
seq_name VARCHAR(50),
VALUE INTEGER
) RETURNS VARCHAR(64) DETERMINISTIC BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE
NAME = seq_name;
RETURN mycat_seq_currval (seq_name);
END $
DELIMITER;
DELIMITER $
CREATE FUNCTION mycat_seq_nextval (
seq_name VARCHAR(50)
) RETURNS VARCHAR(64) DETERMINISTIC BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE
NAME = seq_name;
RETURN mycat_seq_currval (seq_name);
END $
DELIMITER;
# 初始化全局序列表
insert into mycat_sequence(name, current_value, increment) values ('SCHEDULE', 10000, 100);
修改Mycat配置,在配置文件 sequence_db_conf.properties添加课程序列(SCHEDULE)在Mysql-1上:
# 进入Mycat的bin目录
vi sequence_db_conf.properties
# 添加配置
SCHEDULE=dn1
修改server.xml,知道全局序列类型:
# 进入Mycat的bin目录
vi server.xml
# 修改sequnceHandlerType=1
# sequnceHandlerType => 0为本地文件方式,1位数据库方式,2位时间戳方式
<property name="sequnceHandlerType">1</property>
启动Mycat
# 进入Mycat的bin目录
./mycat console
测试:
# 连接Mycat,插入数据(可执行多次)
insert into t_schedule(id, subject_code, student_id) values(next value for MYCATSEQ_SCHEDULE, 'WL', 1);
# 查询课程表(id从10100开始)
select * from t_schedule order by id desc;
# 重启Mycat,再次插入(可执行多次)
insert into t_schedule(id, subject_code, student_id) values(next value for MYCATSEQ_SCHEDULE, 'HX', 2);
# 查询课程表(id从10200开始)
select * from t_schedule order by id desc;
- 时间戳方式
全局序列ID=64位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)换算成十进制为 18位数的long类型,每毫秒可以并发12位二进制的累加。
此方式优点是配置简单,缺点是ID为18,位数太长。 - 自定义方式(推荐)
通过Redis生成序列,或者通过第三方插件生成自增ID,具体根据业务自由选择。

