Mysql性能优化专栏
1. 最大数据量
Mysql没有对单表的数据量大小做限制,单表的大小取决于操作系统对文件大小的限制。
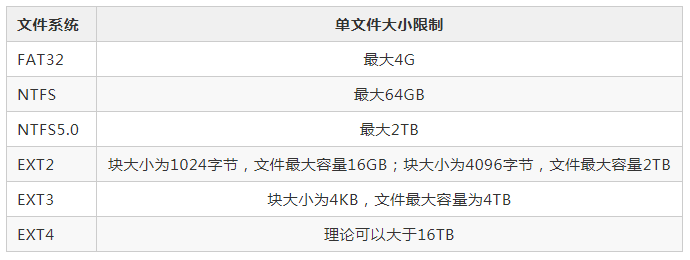
《阿里巴巴Java开发手册》中建议当单表的数据量大小超过500万行或者大于2GB时需要分库分表。
2. 最大连接数
Mysql的最大连接数由 max_connections 和 max_user_connections 两个参数决定。
max_connections 表示Mysql实例的最大连接数,上限为16384。max_user_connections表示每个用户的最大连接数,0则表示无限制。
查询最大连接数设置:
1 show variables like '%max_connections%'; 2 show variables like '%max_user_connections%';
Mysql为每个连接提供缓冲池,过多的连接意味着消耗更过的内存,因此一般设置两者的比值超过10%,计算公式为:max_user_connections / max_connections * 100%
设置最大连接数:
- 临时设置,重启后失效
1 set global max_connections = 1000; 2 set global max_user_connections = 100;
- 配置文件设置,永久有效
max_connections=200 max_user_connections=20
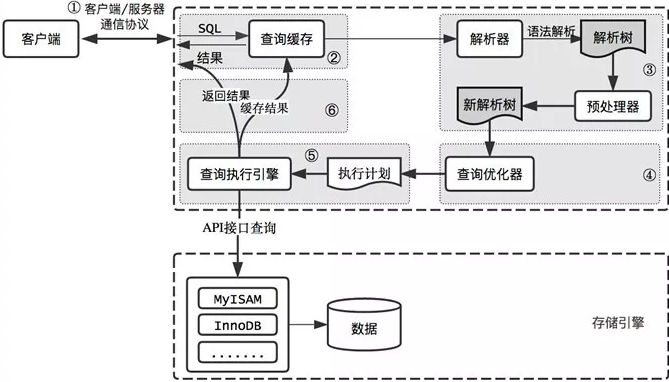
3. Mysql查询过程
4. 查询耗时
建议单次查询耗时控制在0.5秒之内,源于用户体验3秒原则。
响应时间 = 客户端UI渲染耗时 + 网络请求耗时 + 应用程序处理耗时 + 查询数据库耗时。
5. 实施原则
- 合理使用索引,滥用索引会消耗磁盘空间和CPU
- 不推荐使用函数格式化数据,而交给应用程序处理
- 不推荐使用外键约束,而在应用程序中保持数据的准确性
- 写多读少时,避免使用唯一索引,而使用应用程序保持数据唯一性
- 避免冗余字段,建立中间表,空间换时间
- 避免使用极度消耗事务,而应由应用程序分割出尽可能小的事务
- 对重点表提前预知,提前优化
6. 数据库表设计
- 如果长度允许,尽量使用tinyint(1字节)、smallint(2字节)、mediumint(3字节)而非int(4字节)、bigint(8字节)
- 如果长度固定,则使用char类型,而非varchar
- 如果varchar足够,则不使用text
- 精度较高则是由decimal,或者使用bigint类型,存实际数值*小数点后位数*10,例如小数点后两位5.67则存567
- 使用timestamp(4字节)而非datatime(8字节),以UTC的格式储存自动转换时区
- text类型字段存储大量数据,表容量也随之增大,建议使用子表存储,业务数据关联
7. 数据库引擎
InnoDB:两个文件,一个存结构,一个存索引和数据等信息
- 使用B+树存储表数据索引文件
- B+树的叶子结点存储表的所有数据
- 推荐使用数值自增主键
- 非主键索引的叶子结点存储的是主键(一致性和节约空间)
- MyISAM:三个文件,一个存结构,一个存索引及数据磁盘地址,一个存数据
8. 优化维度
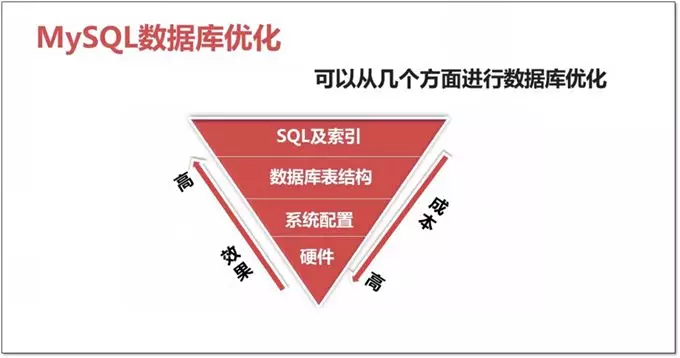
优化选择:
- 优化成本:硬件 > 系统配置 > 数据库表结构 > SQL及索引
- 优化效果:硬件 < 系统配置 < 数据库表结构 < SQL及索引
9. 索引
从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。
从应用层次来分:普通索引,唯一索引,复合索引。
根据中数据的物理顺序与键值的逻辑(索引)顺序关系:聚集索引,非聚集索引。
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引。
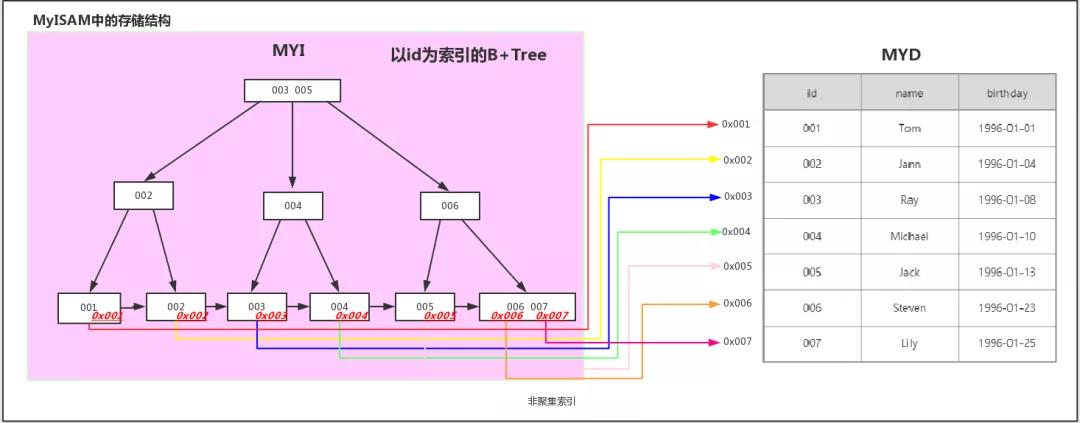
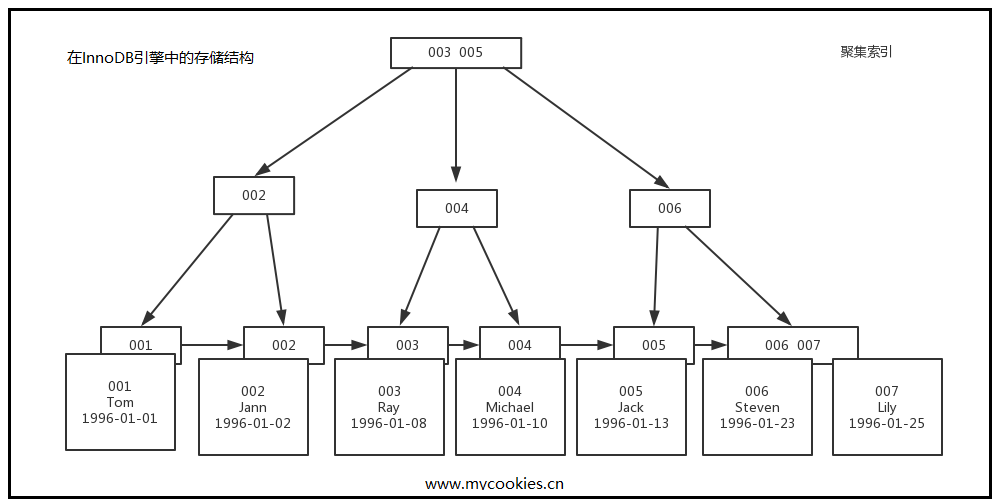
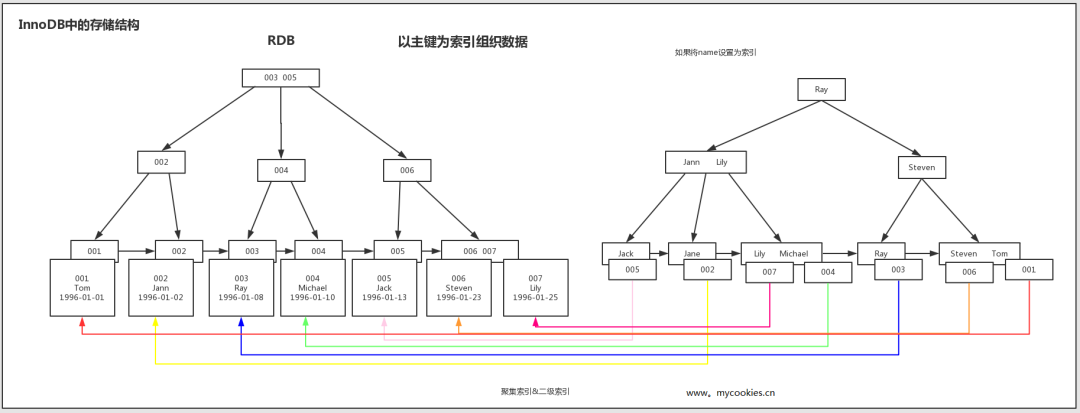
MyISAM引擎以主键作为索引时叶子节点存储的是数据的地址。InnoDB引擎以主键作为索引时叶子节点存储的是数据信息,非主键索引叶子节点存储的是主键,再通过主键查询数据。
建议使用自增主键作为索引。
10. Mysql索引失效
可以使用explain命令加在要分析的sql语句前面,在执行结果中查看key这一列的值,如果为NULL,说明没有使用索引。
- like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效
- or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引
- 失效,只有当or左右查询字段均为索引时,才会生效
- 组合索引,不是使用第一列索引,索引失效
- 数据类型出现隐式转换。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描
- 在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可
- 在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0对索引字段进行计算操作,字段上使用函数
- 当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效
11. Mysql索引总结
- 问:为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
- 问:为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
插入连续的数据:
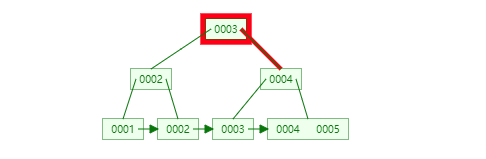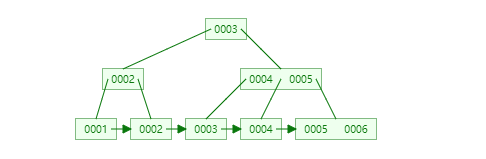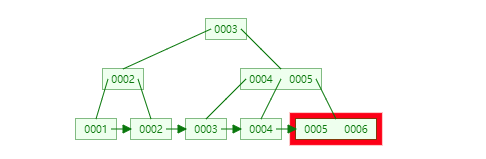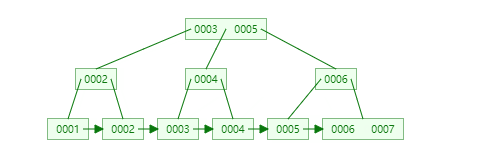
插入非连续的数据:

12. SQL优化
- 分批处理
若批量更新整个表的状态,会导致当前事务阻塞,建议分小批次更新。
- 不等于优化
不等于会使索引失效,建议使用union all。例如:查询商品表不等于100元的商品,则查询商品 [0, 100) 并 (100, +∞]的价格。
- or优化
or会是组合索引优化,因此使用union。例如:查询人员表org_code为123456且login_code为zhangsan的信息,则查询org_code为123456 并 login_code为zhangsan的信息,前提是org_code和login_code都建立了索引。
- in优化
in适合主表大子表小,exist适合主表小子表大。由于查询优化器的不断升级,很多场景这两者性能差已经不明显了。
将in改为join语句。
- join优化
join的实现是采用Nested Loop Join算法,就是通过驱动表的结果集作为基础数据,通过该结数据作为过滤条件到下一个表中循环查询数据,然后合并结果。如果有多个join,则将前面的结果集作为循环数据,再次到后一个表中查询数据。
a. 驱动表和被驱动表尽可能的增加查询条件,能使用on则不使用where,小结果集驱动大结果集
b. 尽量给驱动表的join字段加上索引
c. 如果需要join三个以上的表,建议冗余字段
- limit优化
尽量使用分页查询,限制返回数据量大小。
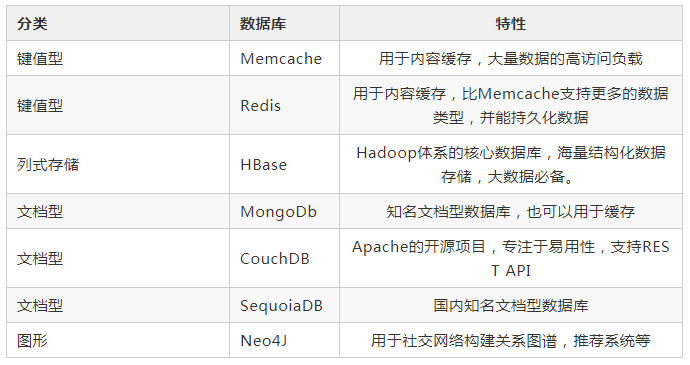
13. 其他数据库