Java中string的编码的详细说明
本文主要说明java的系统里字符串(string)的编码的情况
首先一个问题,如何知道某个string(变量的值)的编码是什么?情况复杂,下面分开说明
首先要知道系统默认编码(“系统”不是指操作系统,而是本java应用)。影响编码有以下情况:
默认时,就是操作系统的编码,我们用的中文windows编码一般是GBK,而linux一般是utf-8
当java启动命令可以指定具体编码。我们生产环境一般都会设为utf-8。编码设置方法在开发和生产环境有不同方法,对于开发环境,编码的设置跟开发用的IDE有关,这里不展开,对于生产环境,编码设置在java运行命令的参数

-Dfile.encoding=utf-8
上面说的是编码设置,那怎么确定java应用真实使用的编码(确认设置是否生效)?可以用如下代码输出
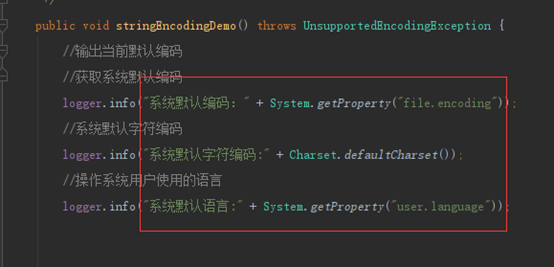
//获取系统默认编码 logger.info("系统默认编码:" + System.getProperty("file.encoding")); //系统默认字符编码 logger.info("系统默认字符编码:" + Charset.defaultCharset()); //操作系统用户使用的语言 logger.info("系统默认语言:" + System.getProperty("user.language"));
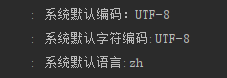
在我自己的IDEA开发环境运行输出如下。因为在IDEA的配置设了编码是utf-8
PS:【系统默认编码】和【系统默认字符编码】到底哪个才影响“string的编码”还不清楚,弄的两个都一样的就最好了
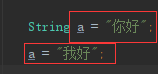
到此,我们解决了java应用默认编码的问题,“在代码中显式赋值的string“的编码都是默认编码,例如下图这些就是
但是,string的值来源很多,例如有从配置文件读取,从http调用(作为服务端)传入,从excel或文本文件读取等等。此时string的编码跟文件本身的编码甚至读取的相关工具类的编码设置都有关,这里不展开怎么修改编码。但怎么确认他们是什么编码?可以用以下方法
PS:此方法在实际使用中发现不太准确,因此还有待验证
public static final String[] ENCODES = new String[]{"UTF-8", "GBK", "GB2312", "ISO-8859-1", "ISO-8859-2"}; /** * 获取字符串是什么编码,例如返回的值有:UTF-8,GBK,ISO-8859-1等 * * @param str * @return */ public static String getEncode(String str) { byte[] data = str.getBytes(); byte[] b = null; a: for (int i = 0; i < ENCODES.length; i++) { try { b = str.getBytes(ENCODES[i]); if (b.length != data.length) { continue; } for (int j = 0; j < b.length; j++) { if (b[j] != data[j]) { continue a; } } return ENCODES[i]; } catch (UnsupportedEncodingException e) { continue; } } return null; }
输出如下,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号