学习爬虫——test1——模拟浏览器去访问网站
用爬取豆瓣网站上的信息作为实例
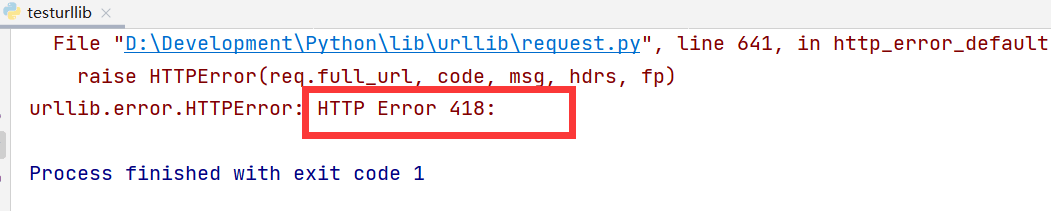
1. 不模拟浏览器访问,可能会出现 418 错误,这说明你要爬取的网站已经知道你是爬虫啦
很多网站有反爬虫机制,直接爬取会被拦截
如:直接访问时
url="http://www.douban.com"
response=urllib.request.urlopen(url)
print(response.read().decode("utf-8"))
会出现418错误:
2. 模拟浏览器访问,需要用到 Request 封装函数,将要访问的网址封装起来
在这里,我理解为:把模拟浏览器的信息放在一个对象里面即res,res中包含了浏览器的头部信息、访问方式等
headers是伪装的向豆瓣网站发送的头部信息,里面包含的用户代理信息标识了此次访问是浏览器在访问(即模拟浏览器)
url="http://douban.com"
data=bytes(urllib.parse.urlencode({"name":"lll"}),encoding="utf-8")
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.75"
}
res=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(res)
print(response.read().decode("utf-8"))
这样就可以成功爬取到网页的内容了: