

(1)abs(x):返回数字的绝对值
参数:x -- 数值表达式,可以是整数,浮点数,复数
返回值:数字的绝对值
print(abs(-25)) #结果25 print(abs(-25.01))#结果25.01
(2)all(iterable):判断给定的可迭代参数iterable中的所有元素是否都为True,如果是返回 True,否则返回 False
注意两点:第一,元素除了是 0、空、FALSE外都算TRUE,第二,空元组,空列表返回值为True
参数:iterable -- 元组或列表
返回值:True,False
all(['a', 'b', 'c', 'd']) # 列表list,元素都不为空或0 结果为True
all(['a', 'b', '', 'd']) # 列表list,存在一个为空的元素 结果为False
all([0, 1,2, 3]) # 列表list,存在一个为0的元素 结果为False
all(('a', 'b', 'c', 'd')) # 元组tuple,元素都不为空或0 结果为True
all(('a', 'b', '', 'd')) # 元组tuple,存在一个为空的元素 结果为False
all((0, 1, 2, 3)) # 元组tuple,存在一个为0的元素 结果为False
all([]) # 空列表 结果为True
all(()) # 空元组 结果为True
(3)any(iterable):判断给定的可迭代参数iterable是否全部为False,则返回False,如果有一个为True,则返回 True.
参数:iterable -- 元组或列表
返回值:True,False
any(['a', 'b', 'c', 'd']) # 列表list,元素都不为空或0 结果为True
any(['a', 'b', '', 'd']) # 列表list,存在一个为空的元素 结果为True
any([0, '', False]) # 列表list,元素全为0,'',false 结果为False
any(('a', 'b', 'c', 'd')) # 元组tuple,元素都不为空或0 结果为True
any(('a', 'b', '', 'd')) # 元组tuple,存在一个为空的元素 结果为True
any((0, '', False)) # 元组tuple,元素全为0,'',false 结果为False
any([]) # 空列表 结果为False
any(()) # 空元组 结果为False
(4)ascii(object):类似repr() 函数, 返回一个表示对象的字符串,但是对于字符串中的非 ASCII 字符则返回通过 repr() 函数使用 \x, \u 或 \U 编码的字符
参数:object -- 对象
返回值:字符串
ascii(python3) #结果为'python3'
(5)bin(x):返回一个整数int或者长整数long int的二进制表示
参数:x -- int 或者 long int 数字
返回值:字符串
print(bin(1)) #结果为0b1 print(bin(2)) #结果为0b10 print(bin(3)) #结果为0b11 print(bin(4)) #结果为0b100
(6)bool():将给定参数转换为布尔类型,如果没有参数,返回 False
说明:bool 是 int 的子类
语法:class bool([x])
参数:需要进行转换的参数
返回值:True,False
bool() 结果为False bool(0) 结果为False bool(1) 结果为True bool(2) 结果为True issubclass(bool, int) # bool 是 int 子类 结果为True
(7)bytearray():返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256
语法:class bytearray([source[, encoding[, errors]]])
参数:
1.如果 source 为整数,则返回一个长度为 source 的初始化数组;
2.如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
3.如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
4.如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
5.如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值:新字节数组
print(bytearray()) #结果为bytearray(b'')
print(bytearray(1)) #结果为bytearray(b'\x00')
print(bytearray([1,2,3])) #结果为bytearray(b'\x01\x02\x03')
print(bytearray("python","utf-8")) #结果为bytearray(b'python')
print(type(bytearray())) #结果为<class 'bytearray'>
(8)bytes():返回一个新的bytes对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
注:它是 bytearray 的不可变版本。
语法:class bytes([source[, encoding[, errors]]])
参数:
1.如果 source 为整数,则返回一个长度为 source 的初始化数组;
2.如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
3.如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
4.如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
5.如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值:新的bytes对象
a = bytes([1,2,3,4]) 结果为b'\x01\x02\x03\x04' type(a)结果为<class 'bytes'>
a = bytes('hello','ascii') 结果为b'hello' type(a)结果为<class 'bytes'>
(9)callable(object):用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
注意:对于函数, 方法, lambda 函式, 类, 以及实现了 __call__ 方法的类实例, 它都返回 True
参数:object -- 对象
返回值:可调用返回True,否则返回 False.
callable(0) #数字返回False
callable("runoob") #字符串返回False
callable(add) #可用函数返回 True
callable(A) # 可用类返回 True
# 没有实现 __call__, 返回 False
# 实现 __call__, 返回 True
(10)chr(i):用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符
参数:i -- 可以是10进制也可以是16进制的形式的数字
返回值:返回值是当前整数对应的ascii字符
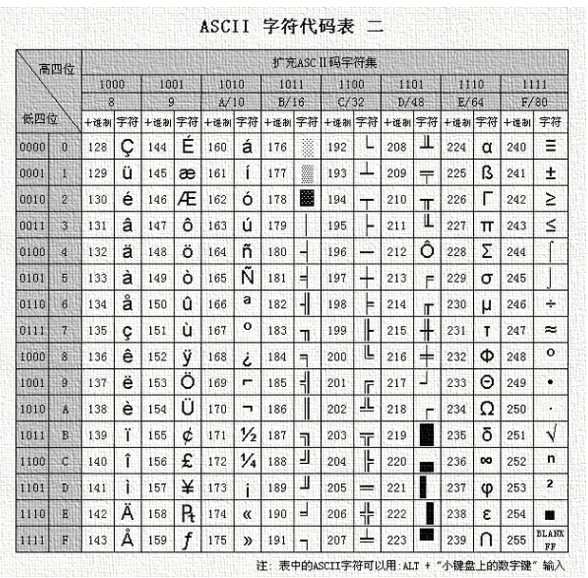


1 Bin Dec Hex 缩写/字符 解释 2 00000000 0 00 NUL(null) 空字符 3 00000001 1 01 SOH(start of headling) 标题开始 4 00000010 2 02 STX (start of text) 正文开始 5 00000011 3 03 ETX (end of text) 正文结束 6 00000100 4 04 EOT (end of transmission) 传输结束 7 00000101 5 05 ENQ (enquiry) 请求 8 00000110 6 06 ACK (acknowledge) 收到通知 9 00000111 7 07 BEL (bell) 响铃 10 00001000 8 08 BS (backspace) 退格 11 00001001 9 09 HT (horizontal tab) 水平制表符 12 00001010 10 0A LF (NL line feed, new line) 换行键 13 00001011 11 0B VT (vertical tab) 垂直制表符 14 00001100 12 0C FF (NP form feed, new page) 换页键 15 00001101 13 0D CR (carriage return) 回车键 16 00001110 14 0E SO (shift out) 不用切换 17 00001111 15 0F SI (shift in) 启用切换 18 00010000 16 10 DLE (data link escape) 数据链路转义 19 00010001 17 11 DC1 (device control 1) 设备控制1 20 00010010 18 12 DC2 (device control 2) 设备控制2 21 00010011 19 13 DC3 (device control 3) 设备控制3 22 00010100 20 14 DC4 (device control 4) 设备控制4 23 00010101 21 15 NAK (negative acknowledge) 拒绝接收 24 00010110 22 16 SYN (synchronous idle) 同步空闲 25 00010111 23 17 ETB (end of trans. block) 传输块结束 26 00011000 24 18 CAN (cancel) 取消 27 00011001 25 19 EM (end of medium) 介质中断 28 00011010 26 1A SUB (substitute) 替补 29 00011011 27 1B ESC (escape) 溢出 30 00011100 28 1C FS (file separator) 文件分割符 31 00011101 29 1D GS (group separator) 分组符 32 00011110 30 1E RS (record separator) 记录分离符 33 00011111 31 1F US (unit separator) 单元分隔符 34 00100000 32 20 (space) 空格 35 00100001 33 21 ! 36 00100010 34 22 " 37 00100011 35 23 # 38 00100100 36 24 $ 39 00100101 37 25 % 40 00100110 38 26 & 41 00100111 39 27 ' 42 00101000 40 28 ( 43 00101001 41 29 ) 44 00101010 42 2A * 45 00101011 43 2B + 46 00101100 44 2C , 47 00101101 45 2D - 48 00101110 46 2E . 49 00101111 47 2F / 50 00110000 48 30 0 51 00110001 49 31 1 52 00110010 50 32 2 53 00110011 51 33 3 54 00110100 52 34 4 55 00110101 53 35 5 56 00110110 54 36 6 57 00110111 55 37 7 58 00111000 56 38 8 59 00111001 57 39 9 60 00111010 58 3A : 61 00111011 59 3B ; 62 00111100 60 3C < 63 00111101 61 3D = 64 00111110 62 3E > 65 00111111 63 3F ? 66 01000000 64 40 @ 67 01000001 65 41 A 68 01000010 66 42 B 69 01000011 67 43 C 70 01000100 68 44 D 71 01000101 69 45 E 72 01000110 70 46 F 73 01000111 71 47 G 74 01001000 72 48 H 75 01001001 73 49 I 76 01001010 74 4A J 77 01001011 75 4B K 78 01001100 76 4C L 79 01001101 77 4D M 80 01001110 78 4E N 81 01001111 79 4F O 82 01010000 80 50 P 83 01010001 81 51 Q 84 01010010 82 52 R 85 01010011 83 53 S 86 01010100 84 54 T 87 01010101 85 55 U 88 01010110 86 56 V 89 01010111 87 57 W 90 01011000 88 58 X 91 01011001 89 59 Y 92 01011010 90 5A Z 93 01011011 91 5B [ 94 01011100 92 5C \ 95 01011101 93 5D ] 96 01011110 94 5E ^ 97 01011111 95 5F _ 98 01100000 96 60 ` 99 01100001 97 61 a 100 01100010 98 62 b 101 01100011 99 63 c 102 01100100 100 64 d 103 01100101 101 65 e 104 01100110 102 66 f 105 01100111 103 67 g 106 01101000 104 68 h 107 01101001 105 69 i 108 01101010 106 6A j 109 01101011 107 6B k 110 01101100 108 6C l 111 01101101 109 6D m 112 01101110 110 6E n 113 01101111 111 6F o 114 01110000 112 70 p 115 01110001 113 71 q 116 01110010 114 72 r 117 01110011 115 73 s 118 01110100 116 74 t 119 01110101 117 75 u 120 01110110 118 76 v 121 01110111 119 77 w 122 01111000 120 78 x 123 01111001 121 79 y 124 01111010 122 7A z 125 01111011 123 7B { 126 01111100 124 7C | 127 01111101 125 7D } 128 01111110 126 7E ~ 129 01111111 127 7F DEL (delete) 删除
print chr(0x30), chr(0x31), chr(0x61) # 十六进制 0 1 a print chr(48), chr(49), chr(97) # 十进制 0 1 a
(11)classmethod:装饰器对应的函数不需要实例化,不需要self参数,但第一个参数需要是表示自身类的cls参数,可以来调用类的属性,类的方法,实例化对象等
语法:classmethod
参数:无
返回值:函数的类方法
class A(object):
bar = 1
def func1(self):
print ('foo')
@classmethod
def func2(cls):
print ('func2')
print (cls.bar)
cls().func1() # 调用 foo 方法
A.func2() # 不需要实例化
(12)compile():将一个字符串编译为字节代码
语法:compile(source, filename, mode[, flags[, dont_inherit]])
参数:
1.source -- 字符串或者AST(Abstract Syntax Trees)对象。
2.filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
3.mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
4.flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
5.flags和dont_inherit是用来控制编译源码时的标志
返回值:表达式执行结果
>>>str = "for i in range(0,10): print(i)" >>> c = compile(str,'','exec') # 编译为字节代码对象 >>> c <code object <module> at 0x10141e0b0, file "", line 1> >>> exec(c) 0 1 2 3 4 5 6 7 8 9 >>> str = "3 * 4 + 5" >>> a = compile(str,'','eval') >>> eval(a) 17
(13)complex():用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
语法:class complex([real[, imag]])
参数:
1.real -- int, long, float或字符串;
2.imag -- int, long, float;
返回值:一个复数
complex(1, 2) 结果为(1 + 2j)
complex(1) # 数字 结果为(1 + 0j)
complex("1") # 当做字符串处理 结果为(1 + 0j)
# 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错
complex("1+2j") 结果为(1 + 2j)
(14)delattr():删除属性
delattr(x, 'foobar') 相等于 del x.foobar
语法:delattr(object, name)
参数:
1.object -- 对象。
2.name -- 必须是对象的属性。
返回值:无
class Coordinate:
x = 10
y = -5
z = 0
point1 = Coordinate()
print('x = ',point1.x)
print('y = ',point1.y)
print('z = ',point1.z)
delattr(Coordinate, 'z')
print('--删除 z 属性后--')
print('x = ',point1.x)
print('y = ',point1.y)
# 触发错误
print('z = ',point1.z)
结果为:
('x = ', 10)
('y = ', -5)
('z = ', 0)
--删除 z 属性后--
('x = ', 10)
('y = ', -5)
Traceback (most recent call last):
File "test.py", line 22, in <module>
print('z = ',point1.z)
AttributeError: Coordinate instance has no attribute 'z'
(15)dict():创建一个字典
语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数:
**kwargs -- 关键字
mapping -- 元素的容器。
iterable -- 可迭代对象。
返回值:返回一个字典
dict() # 创建空字典 结果为{}
dict(a='a', b='b', t='t') # 传入关键字 结果为{'a': 'a', 'b': 'b', 't': 't'}
dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
结果为{'three': 3, 'two': 2, 'one': 1}
dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典
结果为{'three': 3, 'two': 2, 'one': 1}
(16)dir():函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;
带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息.
语法:dir([object])
参数:object -- 对象、变量、类型
返回值:模块的属性列表
>>>dir() # 获得当前模块的属性列表 ['__builtins__', '__doc__', '__name__', '__package__', 'arr', 'myslice'] >>> dir([ ]) # 查看列表的方法 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] >>>
(17)divmod():把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
在 python 2.3 版本之前不允许处理复数。
语法:divmod(a, b)
参数:a: 数字;b: 数字
divmod(7, 2) #结果为(3, 1) divmod(8, 2) #结果为(4, 0) divmod(1+2j,1+0.5j) #结果为((1+0j), 1.5j)
(18)enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,
说明:一般用在 for 循环当中
语法:enumerate(sequence, [start=0])
参数:
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置。
返回值:enumerate(枚举) 对象
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter'] >>>list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] >>>list(enumerate(seasons, start=1)) # 小标从 1 开始 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')] 普通的for循环 >>>i = 0 >>>seq = ['one', 'two', 'three'] >>>for element in seq: ... print(i, seq[i]) ... i += 1 ... 0 one 1 two 2 three for循环中使用enumerate >>>seq = ['one', 'two', 'three'] >>>for i, element in enumerate(seq): ... print(i, seq[i]) ... 0 one 1 two 2 three >>>
(19)eval():用来执行一个字符串表达式,并返回表达式的值
语法:eval(expression[, globals[, locals]])
参数:
expression -- 表达式。
globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值:表达式计算结果
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
(20)exec():执行储存在字符串或文件中的 Python 语句.
相比于 eval,exec可以执行更复杂的 Python 代码.
语法:exec(object[, globals[, locals]])
参数:
object:必选参数,表示需要被指定的Python代码。它必须是字符串或code对象。如果object是一个字符串,该字符串会先被解析为一组Python语句,然后在执行(除非发生语法错误)。如果object是一个code对象,那么它只是被简单的执行。
globals:可选参数,表示全局命名空间(存放全局变量),如果被提供,则必须是一个字典对象。
locals:可选参数,表示当前局部命名空间(存放局部变量),如果被提供,可以是任何映射对象。如果该参数被忽略,那么它将会取与globals相同的值。
返回值:exec 返回值永远为 None
>>>exec('print("Hello World")')
Hello World
# 单行语句字符串
>>> exec("print ('runoob.com')")
runoob.com
# 多行语句字符串
>>> exec ("""for i in range(5):
... print ("iter time: %d" % i)
... """)
iter time: 0
iter time: 1
iter time: 2
iter time: 3
iter time: 4
x = 10
expr = """
z = 30
sum = x + y + z
print(sum)
"""
def func():
y = 20
exec(expr)
exec(expr, {'x': 1, 'y': 2})
exec(expr, {'x': 1, 'y': 2}, {'y': 3, 'z': 4})
func()
(21)filter():过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
filter(function, iterable)
参数:
function -- 判断函数。
iterable -- 可迭代对象。
返回值:返回新列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#1.过滤出列表中的所有奇数
def is_odd(n):
return n % 2 == 1
newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(newlist)
#结果为[1, 3, 5, 7, 9]
#2.过滤出1~100中平方根是整数的数
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
newlist = filter(is_sqr, range(1, 101))
print(newlist)
#结果为[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
3.py2是过滤后的列表,py3是filter类.
(22)float():将整数和字符串转换成浮点数
语法:class float([x])
参数:x -- 整数或字符串
返回值:浮点数
float(1) #结果为1.0
float(112) #结果为112.0
float(-123.6) #结果为-123.6
float('123') #字符串 #结果为123.0
(23)format():Python2.6 开始,新增了一种格式化字符串的函数 str.format()
语法:是通过 {} 和 : 来代替以前的 %
参数:可以接受不限个参数,位置可以不按顺序
一丶字符串格式化
1.# 不设置指定位置,按默认顺序
"{} {}".format("hello", "world")
'hello world'
2. # 设置指定位置
"{0} {1}".format("hello", "world")
'hello world'
2.1# 设置指定位置
"{1} {0} {1}".format("hello", "world")
'world hello world'
3.#通过关键字传参
print("网站名:{name}, 地址 {url}".format(name="baidu", url="www.baidu.com"))
4.# 通过字典设置参数
site = {"name": "baidu", "url": "www.baidu.com"}
print("网站名:{name}, 地址 {url}".format(**site))
5.# 通过列表索引设置参数
my_list = ['baidu', 'www.baidu.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
6.#也可以向 str.format() 传入对象
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
结果为value 为: 6
二丶数字格式化
语法:"{格式}".format(预格式化内容)
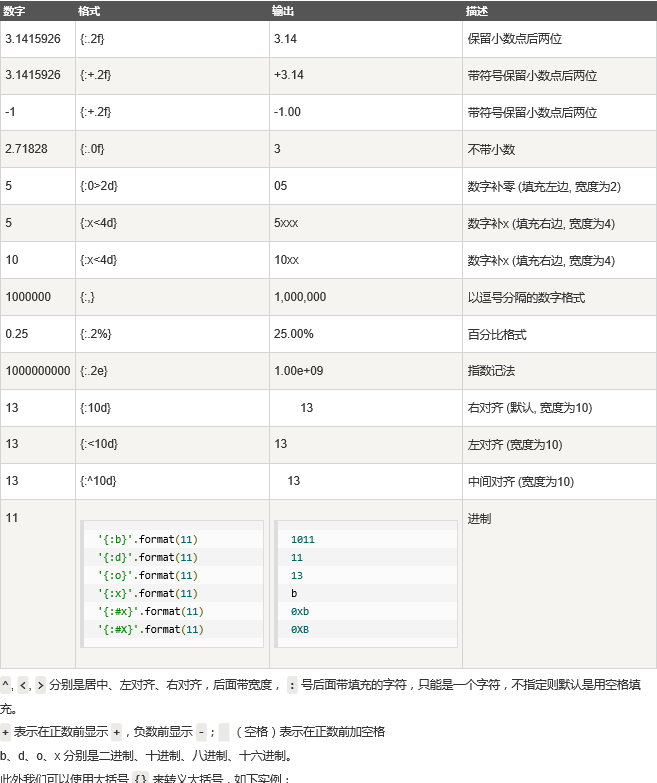
三丶此外我们可以使用大括号 {} 来转义大括号
print ("{} 对应的位置是 {{0}}".format("word"))
word 对应的位置是 {0}
(24)frozenset():返回一个冻结的集合,冻结后集合不能再添加或删除任何元素.
语法:class frozenset([iterable])
参数:iterable -- 可迭代的对象,比如列表、字典、元组等等
返回值:返回新的 frozenset 对象,如果不提供任何参数,默认会生成空集合
a = frozenset(range(10)) # 生成一个新的不可变集合
结果为frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
b = frozenset('runoob')# 结果为frozenset(['b', 'r', 'u', 'o', 'n']) # 创建不可变集合
(25)getattr():返回一个对象属性值
语法:getattr(object, name[, default])
参数:
object -- 对象。
name -- 字符串,对象属性。
default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
返回值:返回对象属性值
>>>class A(object): ... bar = 1 ... >>> a = A() >>> getattr(a, 'bar') # 获取属性 bar 值 1 >>> getattr(a, 'bar2') # 属性 bar2 不存在,触发异常 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'A' object has no attribute 'bar2' >>> getattr(a, 'bar2', 3) # 属性 bar2 不存在,但设置了默认值 3 >>>
(26)globals():以字典类型返回当前位置的全部全局变量
参数:无
返回值:返回全局变量的字典
>>>a='仓鼠'
>>> print(globals()) # globals 函数返回一个全局变量的字典,包括所有导入的变量。
{'__builtins__': <module '__builtin__' (built-in)>, '__name__': '__main__', '__doc__': None, 'a': '仓鼠', '__package__': None}
(27)hasattr():判断对象是否包含对应的属性
语法:hasattr(object, name)
参数:
object -- 对象。
name -- 字符串,属性名。
返回值:如果对象有该属性返回 True,否则返回 False
class Coordinate:
x = 10
y = -5
z = 0
point1 = Coordinate()
print(hasattr(point1, 'x')) True
print(hasattr(point1, 'y')) True
print(hasattr(point1, 'z')) True
print(hasattr(point1, 'no')) #没有该属性 False
(28)hash():获取取一个对象(字符串或者数值等)的哈希值
语法:hash(object)
参数:object -- 对象
返回值:对象的哈希值
hash('test') # 字符串 2314058222102390712
hash(1) # 数字 1
hash(str([1,2,3])) # 集合 1335416675971793195
hash(str(sorted({'1':1}))) # 字典 7666464346782421378
(29)help():查看函数或模块用途的详细说明
返回值:对象的帮助信息
>>>help('sys') # 查看 sys 模块的帮助
……显示帮助信息……
>>>help('str') # 查看 str 数据类型的帮助
……显示帮助信息……
>>>a = [1,2,3]
>>>help(a) # 查看列表 list 帮助信息
……显示帮助信息……
>>>help(a.append) # 显示list的append方法的帮助
……显示帮助信息……
(30)hex():将10进制整数转换成16进制,以字符串形式表示
参数:x -- 10进制整数
返回值:返回16进制数,以字符串形式表示
hex(255)'0xff' hex(-42)'-0x2a' hex(1L)'0x1L' hex(12)'0xc' type(hex(12)) <class 'str'> # 字符串
(31)id():用于获取对象的内存地址
语法:id([object])
参数:object -- 对象
返回值:返回对象的内存地址
a = '仓鼠' id(a) 666887632 b = 1 id(b) 15251254085608
(32)input():Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
Python2.x 中 input() 相等于 eval(raw_input(prompt)) ,用来获取控制台的输入。
raw_input() 将所有输入作为字符串看待,返回字符串类型。
input() 在对待纯数字输入时具有自己的特性,它返回所输入的数字的类型( int, float )。
注意:input() 和 raw_input() 这两个函数均能接收 字符串 ,
但 raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。
而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互。
注意:python3 里 input() 默认接收到的是 str 类型。
#1.input() 需要输入 python 表达式
a = input("input:")input:123 # 输入整数 type(a)<type 'int'> # 整型
a = input("input:")input:"runoob" # 正确,字符串表达式type(a)<type 'str'> # 字符串
a = input("input:") input:runoob # 报错,不是表达式
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'runoob' is not defined
<type 'str'>
#2.raw_input() 将所有输入作为字符串看待
a = raw_input("input:")input:123 type(a)<type 'str'> # 字符串
a = raw_input("input:") input:runoob type(a)<type 'str'> # 字符串
(33)int():将一个字符串或数字转换为整型
语法:class int(x, base=10)
参数:
x -- 字符串或数字
base -- 进制数,默认十进制
返回值:返回整型数据
int() # 不传入参数时,得到结果0
int(3) 3
int(3.6) 3
int('12',16) # 如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制18
int('0xa',16) 10
int('10',8) 8
(34)isinstance():函数来判断一个对象是否是一个已知的类型,类似 type()
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
语法:isinstance(object, classinfo)
参数:
object -- 实例对象
classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组
返回值:如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
type() 与 isinstance()区别:
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False
(35)issubclass():判断参数class是否是类型参数 classinfo 的子类
语法:issubclass(class, classinfo)
参数:
class -- 类。
classinfo -- 类。
返回值:如果 class 是 classinfo 的子类返回 True,否则返回 False
class A:
pass
class B(A):
pass
print(issubclass(B,A)) # 返回 True
(36)iter():生成迭代器
语法iter(object[, sentinel])
参数:
object -- 支持迭代的集合对象。
sentinel -- 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用 object。打开模式
返回值:迭代器对象
>>>lst = [1, 2, 3] >>> for i in iter(lst): ... print(i) ... 1 2 3
(37)len():返回对象(字符、列表、元组等)长度或项目个数
语法:len(s)
参数:s--对象
返回值:对象长度
>>>str = "baidu" >>> len(str) # 字符串长度 5 >>> l = [1,2,3,4,5] >>> len(l) # 列表元素个数 5
(38)list():将元组转换为列表。
注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。
语法:list( seq )
参数:list -- 要转换为列表的元组
返回值:列表
aTuple = (123, 'Google', 'Runoob', 'Taobao')
list1 = list(aTuple)
print ("列表元素 : ", list1)
列表元素 : [123, 'Google', 'Runoob', 'Taobao']
str="Hello World"
list2=list(str)
print ("列表元素 : ", list2)
列表元素 : ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
(39)locals():函数会以字典类型返回当前位置的全部局部变量。
对于函数, 方法, lambda 函式, 类, 以及实现了 __call__ 方法的类实例, 它都返回 True
参数:无
返回值:返回字典类型的局部变量
>>>def runoob(arg): # 两个局部变量:arg、z
... z = 1
... print (locals())
...
>>> runoob(4)
{'z': 1, 'arg': 4} # 返回一个名字/值对的字典
>>>
(40)map():会根据提供的函数对指定序列做映射
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表
语法:map(function, iterable, ...)
参数:
function -- 函数,有两个参数
iterable -- 一个或多个序列
返回值:
Python 2.x 返回列表。
Python 3.x 返回迭代器。
>>>def square(x) : # 计算平方数 ... return x ** 2 ... >>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 [1, 4, 9, 16, 25] >>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25] # 提供了两个列表,对相同位置的列表数据进行相加 >>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) [3, 7, 11, 15, 19]
(41)max():返回参数的最大值,参数可以为序列
语法:max( x, y, z, .... )
参数:
x -- 数值表达式。
y -- 数值表达式。
z -- 数值表达式。
返回值:返回给定参数的最大值
max(1,2,3) 结果3
(42)memoryview():函数返回给定参数的内存查看对象(Momory view)。
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
语法:memoryview(obj)
参数:obj -- 对象
返回值:返回元组列表
>>>v = memoryview(bytearray("abcefg", 'utf-8'))
>>> print(v[1])
98
>>> print(v[-1])
103
>>> print(v[1:4])
<memory at 0x10f543a08>
>>> print(v[1:4].tobytes())
b'bce'
(43)min():返回给定参数的最小值,参数可以为序列
类似于max()只不过返回最小值 min(1,2,3) 返回1
(44)next():返回迭代器的下一个项目
语法:next(iterator[, default])
参数:
iterator -- 可迭代对象
default -- 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常
返回值:迭代器的下一个项目
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
print(x)
except StopIteration:
# 遇到StopIteration就退出循环
break
结果为:
1
2
3
4
5
(45)oct():函数将一个整数转换成8进制字符串
参数:整数
返回值:8进制字符串
oct(10) '012' oct(20) '024' oct(15) '017'
(46)open():打开一个文件,创建一个file对象
语法:open(name[, mode[, buffering]])
参数:
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
更多请看python文件专题
(47)ord() :ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
参数:字符
返回值:对应的十进制整数
>>>ord('a')
97
>>> ord('b')
98
>>> ord('c')
99
(48)pow():方法返回 xy(x的y次方)的值
语法:import math math.pow( x, y )或pow(x, y[, z])
函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
注意:pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。
参数:
x -- 数值表达式。
y -- 数值表达式。
z -- 数值表达式。
返回值:返回 xy(x的y次方)的值
import math # 导入 math 模块
print ("math.pow(100, 2) : ", math.pow(100, 2))
# 使用内置,查看输出结果区别
print ("pow(100, 2) : ", pow(100, 2))
print ("math.pow(100, -2) : ", math.pow(100, -2))
print ("math.pow(2, 4) : ", math.pow(2, 4))
print ("math.pow(3, 0) : ", math.pow(3, 0))
结果为
math.pow(100, 2) : 10000.0
pow(100, 2) : 10000
math.pow(100, -2) : 0.0001
math.pow(2, 4) : 16.0
math.pow(3, 0) : 1.0
(49)print():打印输出,最常见的一个函数
print 在 Python3.x 是一个函数,但在 Python2.x 版本不是一个函数,只是一个关键字
语法:print(*objects, sep=' ', end='\n', file=sys.stdout)
参数:
objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
sep -- 用来间隔多个对象,默认值是一个空格。
end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
file -- 要写入的文件对象。
返回值:无
>>>print(1)
1
>>> print("Hello World")
Hello World
>>> a = 1
>>> b = 'runoob'
>>> print(a,b)
1 runoob
>>> print("aaa""bbb")
aaabbb
>>> print("aaa","bbb")
aaa bbb
>>>
>>> print("www","runoob","com",sep=".") # 设置间隔符
www.runoob.com
(50)property():函数的作用是在新式类中返回属性值
语法:class property([fget[, fset[, fdel[, doc]]]])
参数:
fget -- 获取属性值的函数
fset -- 设置属性值的函数
fdel -- 删除属性值函数
doc -- 属性描述信息
返回值:返回新式类属性
1.定义一个可控属性值 x
class C(object):
def __init__(self):
self._x = None
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")
如果 c 是 C 的实例化, c.x 将触发 getter,c.x = value 将触发 setter , del c.x 触发 deleter。
如果给定 doc 参数,其将成为这个属性值的 docstring,否则 property 函数就会复制 fget 函数的 docstring(如果有的话)。
将 property 函数用作装饰器可以很方便的创建只读属性
class Parrot(object):
def __init__(self):
self._voltage = 100000
@property
def voltage(self):
"""Get the current voltage."""
return self._voltage
上面的代码将 voltage() 方法转化成同名只读属性的 getter 方法。
property 的 getter,setter 和 deleter 方法同样可以用作装饰器:
class C(object):
def __init__(self):
self._x = None
@property
def x(self):
"""I'm the 'x' property."""
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x
这个代码和第一个例子完全相同,但要注意这些额外函数的名字和 property 下的一样,例如这里的 x
(51)range():
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
Python3 list() 函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
Python2 返回的是列表。
语法:
range(stop)
range(start, stop[, step])
参数:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
>>>range(5) range(0, 5) >>> for i in range(5): ... print(i) ... 0 1 2 3 4 >>> list(range(5)) [0, 1, 2, 3, 4] >>> list(range(0)) [] >>> 有两个参数或三个参数的情况(第二种构造方法) >>>list(range(0, 30, 5)) [0, 5, 10, 15, 20, 25] >>> list(range(0, 10, 2)) [0, 2, 4, 6, 8] >>> list(range(0, -10, -1)) [0, -1, -2, -3, -4, -5, -6, -7, -8, -9] >>> list(range(1, 0)) []
(52)repr():将对象转化为供解释器读取的形式
返回值:一个对象的string格式
>>>s = '仓鼠
>>> repr(s)
"'仓鼠"
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> repr(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
(53)reversed():返回一个反转的迭代器
语法:reversed(seq)
参数:seq -- 要转换的序列,可以是 tuple, string, list 或 range
返回值:返回一个反转的迭代器
# 字符串
seqString = 'Runoob'
print(list(reversed(seqString))) ['b', 'o', 'o', 'n', 'u', 'R']
# 元组
seqTuple = ('R', 'u', 'n', 'o', 'o', 'b')
print(list(reversed(seqTuple))) ['b', 'o', 'o', 'n', 'u', 'R']
# range
seqRange = range(5, 9)
print(list(reversed(seqRange))) [8, 7, 6, 5]
# 列表
seqList = [1, 2, 4, 3, 5]
print(list(reversed(seqList))) [5, 3, 4, 2, 1]
(54)round():返回浮点数x的四舍五入值
语法:round( x [, n] )
参数:
x -- 数字表达式。
n -- 表示从小数点位数,其中 x 需要四舍五入,默认值为 0。
返回值:返回浮点数x的四舍五入值
print ("round(70.23456) : ", round(70.23456))
print ("round(56.659,1) : ", round(56.659,1))
print ("round(80.264, 2) : ", round(80.264, 2))
print ("round(100.000056, 3) : ", round(100.000056, 3))
print ("round(-100.000056, 3) : ", round(-100.000056, 3))
以上实例运行后输出结果为:
round(70.23456) : 70
round(56.659,1) : 56.7
round(80.264, 2) : 80.26
round(100.000056, 3) : 100.0
round(-100.000056, 3) : -100.0
(55)set():创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
语法:class set([iterable])
参数:iterable -- 可迭代对象
返回值:返回新的集合对象
>>>x = set('runoob')
>>> y = set('google')
>>> x, y
(set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重复的被删除
>>> x & y # 交集
set(['o'])
>>> x | y # 并集
set(['b', 'e', 'g', 'l', 'o', 'n', 'r', 'u'])
>>> x - y # 差集
set(['r', 'b', 'u', 'n'])
(56)setattr():对应函数getattr(),用于设置属性值,该属性必须存在
语法:setattr(object, name, value)
参数:
object -- 对象。
name -- 字符串,对象属性。
value -- 属性值。
返回值:无
>>>class A(object): ... bar = 1 ... >>> a = A() >>> getattr(a, 'bar') # 获取属性 bar 值 1 >>> setattr(a, 'bar', 5) # 设置属性 bar 值 >>> a.bar 5
(57)slice():实现切片对象
主要用在切片操作函数里的参数传递
语法:
class slice(stop)
class slice(start, stop[, step])
参数:
start -- 起始位置
stop -- 结束位置
step -- 间距
返回值:一个切片对象
>>>myslice = slice(5) # 设置截取5个元素的切片 >>> myslice slice(None, 5, None) >>> arr = range(10) >>> arr [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> arr[myslice] # 截取 5 个元素 [0, 1, 2, 3, 4]
(58)sorted():对所有可迭代的对象进行排序操作
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法:sorted(iterable, key=None, reverse=False)
参数:
iterable -- 可迭代对象。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)
返回值:返回重新排序的列表
以下实例展示了 sorted 的最简单的使用方法:
>>>sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5] # 默认为升序
你也可以使用 list 的 list.sort() 方法。这个方法会修改原始的 list(返回值为None)。通常这个方法不如sorted()方便-如果你不需要原始的 list,list.sort()方法效率会稍微高一些。
>>>a=[5,2,3,1,4]
>>> a.sort()
>>> a
[1,2,3,4,5]
另一个区别在于list.sort() 方法只为 list 定义。而 sorted() 函数可以接收任何的 iterable。
>>>sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'})
[1, 2, 3, 4, 5]
利用key进行倒序排序
>>>example_list = [5, 0, 6, 1, 2, 7, 3, 4]
>>> result_list = sorted(example_list, key=lambda x: x*-1)
>>> print(result_list)
[7, 6, 5, 4, 3, 2, 1, 0]
>>>
要进行反向排序,也通过传入第三个参数 reverse=True:
>>>example_list = [5, 0, 6, 1, 2, 7, 3, 4]
>>> sorted(example_list, reverse=True)
[7, 6, 5, 4, 3, 2, 1, 0]
(59)staticmethod():返回函数的静态方法
class C(object):
@staticmethod
def f():
print('runoob');
C.f(); # 静态方法无需实例化
cobj = C()
cobj.f() # 也可以实例化后调用
(60)str():将对象转化为适于人阅读的形式
参数:object -- 对象
返回值:返回一个对象的string格式
>>>s = 'RUNOOB'
>>> str(s)
'RUNOOB'
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> str(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
(61)sum():方法对系列进行求和计算
语法:sum(iterable[, start])
参数:
iterable -- 可迭代对象,如:列表、元组、集合。
start -- 指定相加的参数,如果没有设置这个值,默认为0。
返回值:计算结果
>>>sum([0,1,2]) 3 >>> sum((2, 3, 4), 1) # 元组计算总和后再加 1 10 >>> sum([0,1,2,3,4], 2) # 列表计算总和后再加 2 12
(62)super():用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表
语法:super(type[, object-or-type])
参数:
type -- 类。
object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
Python3.x 实例:
class A:
pass
class B(A):
def add(self, x):
super().add(x)
Python2.x 实例:
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)
Parent
Child
HelloWorld from Parent
Child bar fuction
I'm the parent.
class FooParent(object):
def __init__(self):
self.parent = 'I\'m the parent.'
print ('Parent')
def bar(self,message):
print ("%s from Parent" % message)
class FooChild(FooParent):
def __init__(self):
# super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类B的对象 FooChild 转换为类 FooParent 的对象
super(FooChild,self).__init__()
print ('Child')
def bar(self,message):
super(FooChild, self).bar(message)
print ('Child bar fuction')
print (self.parent)
if __name__ == '__main__':
fooChild = FooChild()
fooChild.bar('HelloWorld')
(63)tuple():函数将列表转换为元组
>>>list1= ['Google', 'Taobao', 'Runoob', 'Baidu']
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'Runoob', 'Baidu')
(64)type():函数如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象
语法:class type(name, bases, dict)
参数:
name -- 类的名称。
bases -- 基类的元组。
dict -- 字典,类内定义的命名空间变量。
返回值:一个参数返回对象类型, 三个参数,返回新的类型对象
# 一个参数实例
>>> type(1)
<type 'int'>
>>> type('runoob')
<type 'str'>
>>> type([2])
<type 'list'>
>>> type({0:'zero'})
<type 'dict'>
>>> x = 1
>>> type( x ) == int # 判断类型是否相等
True
# 三个参数
>>> class X(object):
... a = 1
...
>>> X = type('X', (object,), dict(a=1)) # 产生一个新的类型 X
>>> X
<class '__main__.X'>
(65)vars():返回对象object的属性和属性值的字典对象
参数:对象
返回值:返回对象object的属性和属性值的字典对象,如果没有参数,就打印当前调用位置的属性和属性值 类似 locals()
>>>print(vars())
{'__builtins__': <module '__builtin__' (built-in)>, '__name__': '__main__', '__doc__': None, '__package__': None}
>>> class Runoob:
... a = 1
...
>>> print(vars(Runoob))
{'a': 1, '__module__': '__main__', '__doc__': None}
>>> runoob = Runoob()
>>> print(vars(runoob))
{}
(66)zip():函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表
语法:zip([iterable, ...])
参数:iterabl -- 一个或多个迭代器
返回值:返回元组列表
>>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
列表元素依次相连:
l = ['a', 'b', 'c', 'd', 'e','f']
print l
#打印列表
print zip(l[:-1],l[1:])
输出结果:
['a', 'b', 'c', 'd', 'e', 'f']
[('a', 'b'), ('b', 'c'), ('c', 'd'), ('d', 'e'), ('e', 'f')]
(67)__import__():函数用于动态加载类和函数 。
如果一个模块经常变化就可以使用 __import__() 来动态载入
语法:__import__(name[, globals[, locals[, fromlist[, level]]]])
参数:模块名
返回值:
以下实例展示了 __import__ 的使用方法:
a.py 文件代码:
#!/usr/bin/env python
#encoding: utf-8
import os
print ('在 a.py 文件中 %s' % id(os))
test.py 文件代码:
#!/usr/bin/env python
#encoding: utf-8
import sys
__import__('a') # 导入 a.py 模块
执行 test.py 文件,输出结果为:
在 a.py 文件中 4394716136
