

MySQL为Null导致的5大坑
正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信息,如下图所示:
“兵马未动粮草先行”,看完了相关的配置之后,我们先来创建一张测试表和一些测试数据。
-- 如果存在 person 表先删除
DROP TABLE IF EXISTS person;
-- 创建 person 表,其中 username 字段可为空,并为其设置普通索引
CREATE TABLE person (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
mobile VARCHAR(13),
index(name)
) ENGINE='innodb';
-- person 表添加测试数据
insert into person(name,mobile) values('Java','13333333330'),
('MySQL','13333333331'),
('Redis','13333333332'),
('Kafka','13333333333'),
('Spring','13333333334'),
('MyBatis','13333333335'),
('RabbitMQ','13333333336'),
('Golang','13333333337'),
(NULL,'13333333338'),
(NULL,'13333333339');
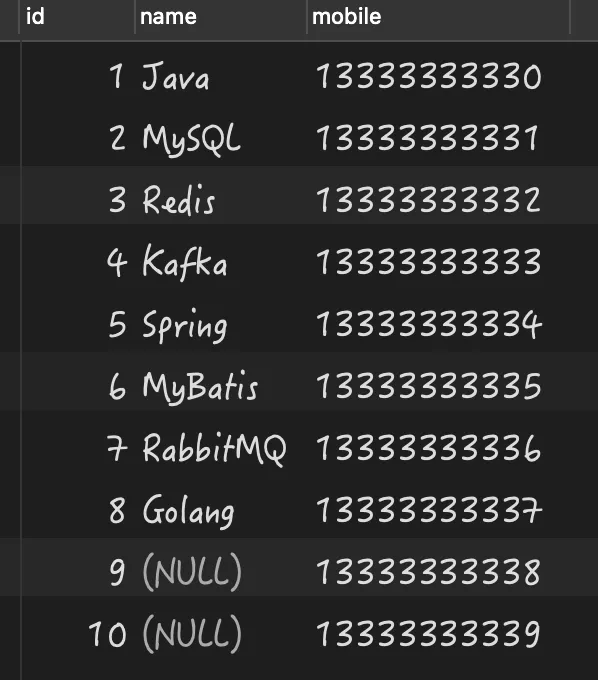
select * from person;
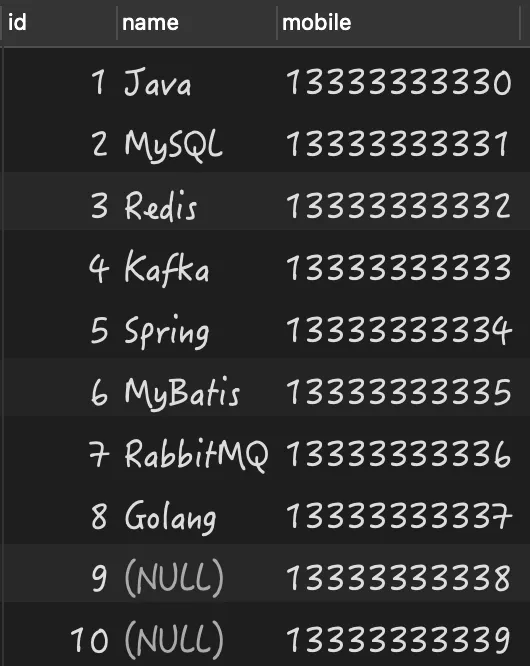
构建的测试数据,如下图所示:
 有了数据之后,我们就来看当列中存在
有了数据之后,我们就来看当列中存在 NULL 值时,究竟会导致哪些问题?
1.count 数据丢失
当某列存在 NULL 值时,再使用 count 查询该列,就会出现数据“丢失”问题,如下 SQL 所示:
select count(*),count(name) from person;
查询执行结果如下:
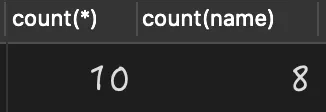
从上述结果可以看出,当使用的是 count(name) 查询时,就丢失了两条值为 NULL 的数据丢失。
解决方案
如果某列存在 NULL 值时,就是用 count(*) 进行数据统计。
扩展知识:不要使用 count(常量)
阿里巴巴《Java开发手册》强制规定:不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
2.distinct 数据丢失
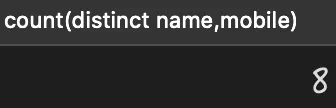
当使用 count(distinct col1, col2) 查询时,如果其中一列为 NULL,那么即使另一列有不同的值,那么查询的结果也会将数据丢失,如下 SQL 所示:
select count(distinct name,mobile) from person;
查询执行结果如下:
数据库的原始数据如下:
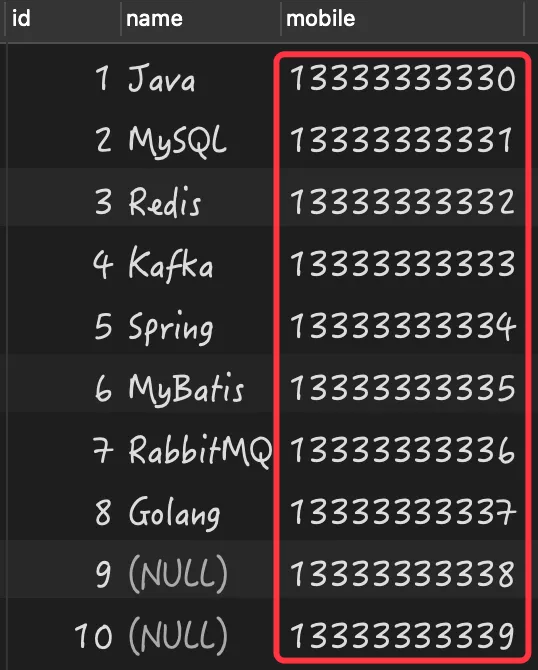
从上述结果可以看出手机号一列的 10 条数据都是不同的,但查询的结果却为 8。
3.select 数据丢失
如果某列存在 NULL 值时,如果执行非等于查询(<>/!=)会导致为 NULL 值的结果丢失。比如以下这个数据:
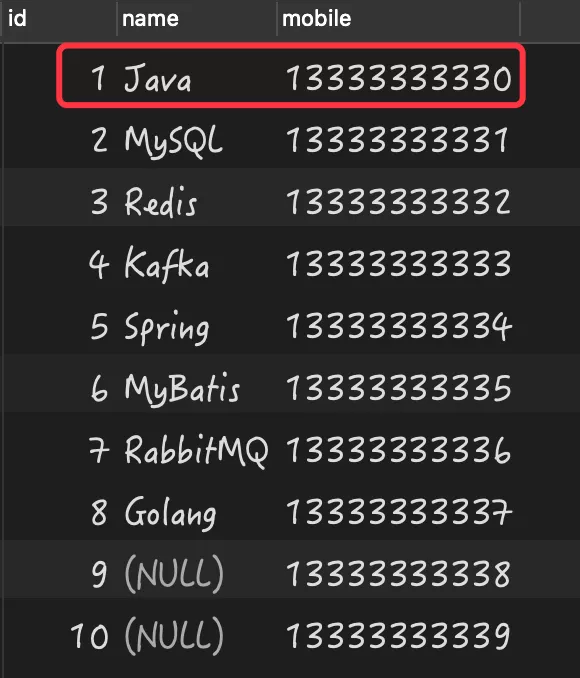
我需要查询除 name 等于“Java”以外的所有数据,预期返回的结果是 id 从 2 到 10 的数据,但当执行以下查询时:
select * from person where name<>'Java' order by id;
-- 或
select * from person where name!='Java' order by id;
查询结果均为以下内容:
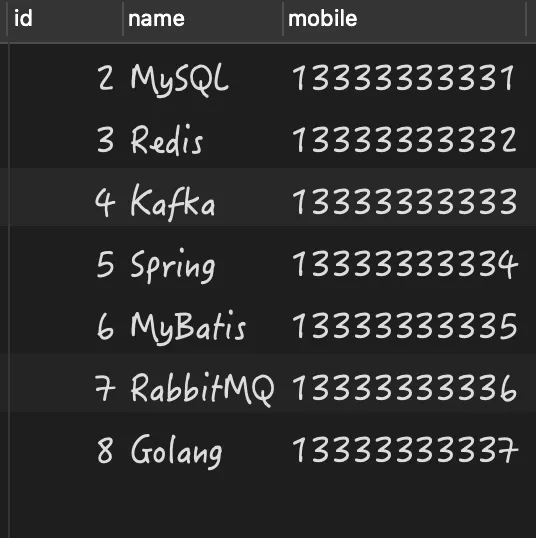
可以看出为 NULL 的两条数据凭空消失了,这个结果并不符合我们的正常预期。
解决方案
要解决以上的问题,只需要在查询结果中拼加上为 NULL 值的结果即可,执行 SQL 如下:
select * from person where name<>'Java' or isnull(name) order by id;
最终的执行结果如下:
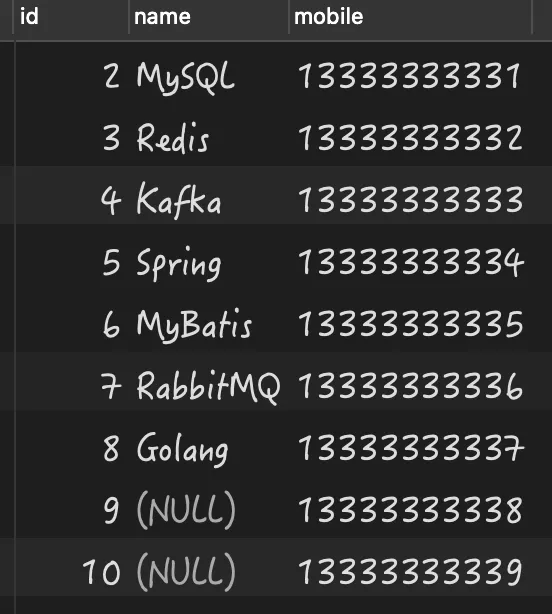
4.导致空指针异常
如果某列存在 NULL 值时,可能会导致 sum(column) 的返回结果为 NULL 而非 0,如果 sum 查询的结果为 NULL 就可以能会导致程序执行时空指针异常(NPE),我们来演示一下这个问题。
首先,我们先构建一张表和一些测试数据:
-- 如果存在 goods 表先删除
DROP TABLE IF EXISTS goods;
-- 创建 goods 表
CREATE TABLE goods (
id INT PRIMARY KEY auto_increment,
num int
) ENGINE='innodb';
-- goods 表添加测试数据
insert into goods(num) values(3),(6),(6),(NULL);
select * from goods;
表中原始数据如下:

接下来我们使用 sum 查询,执行以下 SQL:
select sum(num) from goods where id>4;
查询执行结果如下:
当查询的结果为 NULL 而非 0 时,就可以能导致空指针异常。
解决空指针异常
可以使用以下方式来避免空指针异常:
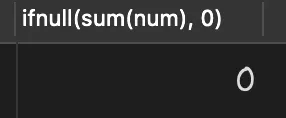
select ifnull(sum(num), 0) from goods where id>4;
查询执行结果如下:
5.增加了查询难度
当某列值中有 NULL 值时,在进行 NULL 值或者非 NULL 值的查询难度就增加了。
所谓的查询难度增加指的是当进行 NULL 值查询时,必须使用 NULL 值匹配的查询方法,比如 IS NULL 或者 IS NOT NULL 又或者是 IFNULL(cloumn) 这样的表达式进行查询,而传统的 =、!=、<>... 等这些表达式就不能使用了,这就增加了查询的难度,尤其是对小白程序员来说,接下来我们来演示一下这些问题。
还是以 person 表为例,它的原始数据如下:
错误用法 1:
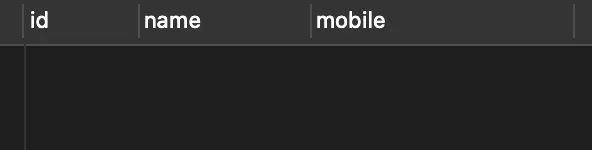
select * from person where name<>null;
执行结果为空,并没有查询到任何数据,如下图所示:
错误用法 2:
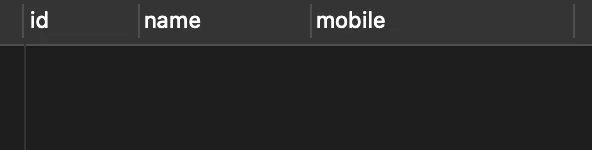
select * from person where name!=null;
执行结果也为空,没有查询到任何数据,如下图所示:
正确用法 1:
select * from person where name is not null;
执行结果如下:
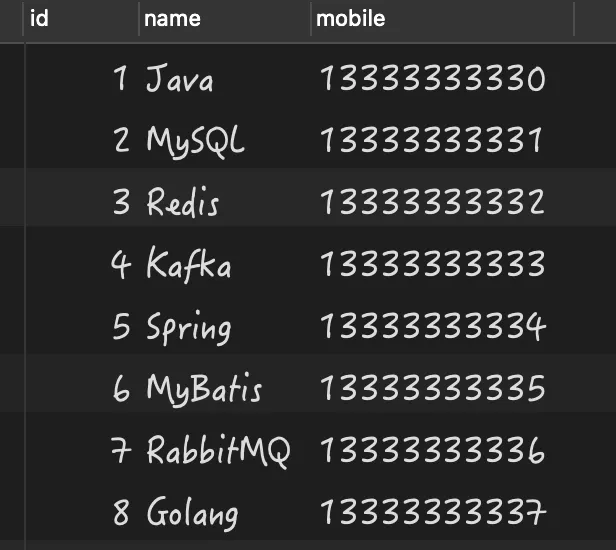
正确用法 2:
select * from person where !isnull(name);
执行结果如下:
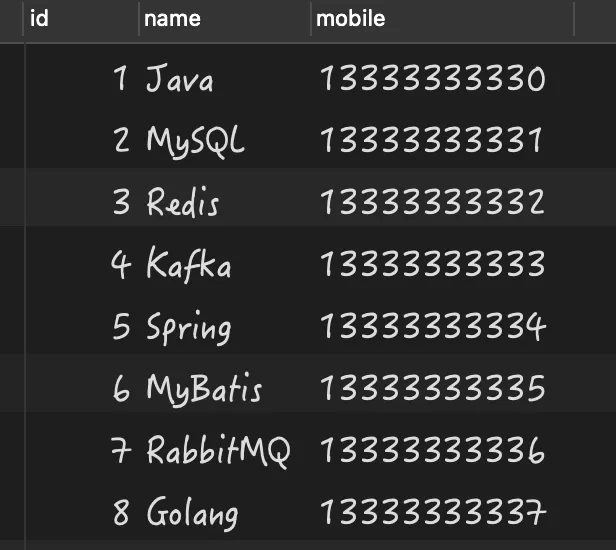
推荐用法
阿里巴巴《Java开发手册》推荐我们使用 ISNULL(cloumn) 来判断 NULL 值,原因是在 SQL 语句中,如果在 null 前换行,影响可读性;而 ISNULL(column) 是一个整体,简洁易懂。从性能数据上分析 ISNULL(column) 执行效率也更快一些。
扩展知识:NULL 不会影响索引
细心的朋友可能发现了,我在创建 person 表的 name 字段时,为其创建了一个普通索引,如下图所示:
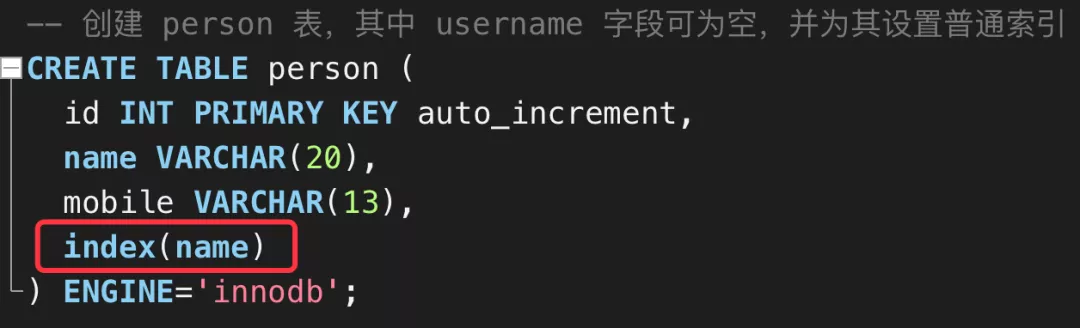
然后我们用 explain 来分析查询计划,看当 name 中有 NULL 值时是否会影响索引的选择。
explain 的执行结果如下图所示:

从上述结果可以看出,即使 name 中有 NULL 值也不会影响 MySQL 使用索引进行查询。
总结
本文我们讲了当某列为 NULL 时可能会导致的 5 种问题:丢失查询结果、导致空指针异常和增加了查询的难度。因此在最后提倡大家在创建表的时候尽量设置 is not null 的约束,如果某列确实没有值,可以设置空值('')或 0 作为其默认值。
最后:大家还有因为 NULL 而造成的各种坑吗?欢迎评论区补充留言。
参考 & 鸣谢
阿里巴巴《Java开发手册》
转自https://mp.weixin.qq.com/s/bBs-RtFo2Zw6NyWoSNy7UQ

