

python 定时任务APScheduler 使用介绍
介绍:
APScheduler的全称是Advanced Python Scheduler。它是一个轻量级的 Python 定时任务调度框架。APScheduler 支持三种调度任务:固定时间间隔,固定时间点(日期),Linux 下的 Crontab 命令。同时,它还支持异步执行、后台执行调度任务。
安装:
pip3 install apscheduler
基本概念
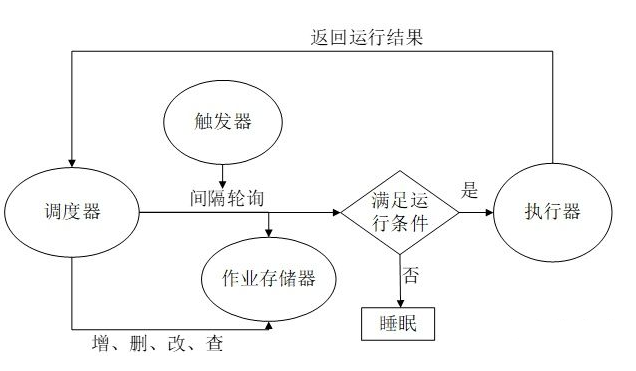
1. APScheduler四大组件:
-
触发器 triggers :用于设定触发任务的条件
-
任务储存器 job stores:用于存放任务,把任务存放在内存或数据库中
-
执行器 executors: 用于执行任务,可以设定执行模式为单线程或线程池
-
调度器 schedulers: 把上方三个组件作为参数,通过创建调度器实例来运行
1.1 触发器 triggers
触发器包含调度逻辑。每个任务都有自己的触发器,用于确定何时应该运行作业。除了初始配置之外,触发器完全是无状态的。
1.2 任务储存器 job stores
默认情况下,任务存放在内存中。也可以配置存放在不同类型的数据库中。如果任务存放在数据库中,那么任务的存取有一个序列化和反序列化的过程,同时修改和搜索任务的功能也是由任务储存器实现。
注意一个任务储存器不要共享给多个调度器,否则会导致状态混乱
1.3 执行器 executors
任务会被执行器放入线程池或进程池去执行,执行完毕后,执行器会通知调度器。
1.4 调度器 schedulers
一个调度器由上方三个组件构成,一般来说,一个程序只要有一个调度器就可以了。开发者也不必直接操作任务储存器、执行器以及触发器,因为调度器提供了统一的接口,通过调度器就可以操作组件,比如任务的增删改查。
调度器工作流程:
2. 调度器组件详解
根据开发需求选择相应的组件,下面是不同的调度器组件:
-
BlockingScheduler 阻塞式调度器:适用于只跑调度器的程序。
-
BackgroundScheduler 后台调度器:适用于非阻塞的情况,调度器会在后台独立运行。
-
AsyncIOScheduler AsyncIO调度器,适用于应用使用AsnycIO的情况。
-
GeventScheduler Gevent调度器,适用于应用通过Gevent的情况。
-
TornadoScheduler Tornado调度器,适用于构建Tornado应用。
-
TwistedScheduler Twisted调度器,适用于构建Twisted应用。
-
QtScheduler Qt调度器,适用于构建Qt应用。
2.1 任务储存器的选择
要看任务是否需要持久化。如果你运行的任务是无状态的,选择默认任务储存器MemoryJobStore就可以应付。但是,如果你需要在程序关闭或重启时,保存任务的状态,那么就要选择持久化的任务储存器。如果,作者推荐使用SQLAlchemyJobStore并搭配PostgreSQL作为后台数据库。这个方案可以提供强大的数据整合与保护功能。
2.2 执行器的选择
同样要看你的实际需求。默认的ThreadPoolExecutor线程池执行器方案可以满足大部分需求。如果,你的程序是计算密集型的,那么最好用ProcessPoolExecutor进程池执行器方案来充分利用多核算力。也可以将ProcessPoolExecutor作为第二执行器,混合使用两种不同的执行器。
配置一个任务,就要设置一个任务触发器。触发器可以设定任务运行的周期、次数和时间。
3. APScheduler有三种内置的触发器:
-
date 日期:触发任务运行的具体日期
-
interval 间隔:触发任务运行的时间间隔
-
cron 周期:触发任务运行的周期
-
calendarinterval:当您想要在一天中的特定时间以日历为基础的间隔运行任务时使用
一个任务也可以设定多种触发器,比如,可以设定同时满足所有触发器条件而触发,或者满足一项即触发。
3.0 触发器代码示例
3.1 date 是最基本的一种调度,作业任务只会执行一次。它表示特定的时间点触发。它的参数如下:
| 参数 | 说明 |
| run_date(datetime or str) | 任务运行的日期或者时间 |
| timezone(datetime.tzinfo or str) | 指定时区 |
from datetime import date from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() def my_job(text): print(text) # 在2019年4月15日执行 scheduler.add_job(my_job, 'date', run_date=date(2019, 4, 15), args=['测试任务']) scheduler.start() ########################################################################################### import datetime from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() def my_job(text): print(text) # datetime类型(用于精确时间) scheduler.add_job(my_job, 'date', run_date=datetime(2019, 4, 15, 17, 30, 5), args=['测试任务']) scheduler.start()
注意:run_date参数可以是date类型、datetime类型或文本类型。
scheduler.add_job(my_job, 'date', run_date='2009-11-06 16:30:05', args=['测试任务'])
3.2 interval 周期触发任务
固定时间间隔触发。interval 间隔调度,参数如下:
| 参数 | 说明 |
| weeks(int) | 间隔几周 |
| days(int) | 间隔几天 |
| hours(int) | 间隔几小时 |
| minutes(int) | 间隔几分钟 |
| seconds(int) | 间隔多少秒 |
| start_date(datetime or str) | 开始日期 |
| end_date(datetime or str) | 结束日期 |
| timezone(datetime.tzinfo or str) | 时区 |
from datetime import datetime from apscheduler.schedulers.blocking import BlockingScheduler def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f") scheduler = BlockingScheduler() # 每2小时触发 scheduler.add_job(job_func, 'interval', hours=2) # 在 2019-04-15 17:00:00 ~ 2019-12-31 24:00:00 之间, 每隔两分钟执行一次 job_func 方法 scheduler .add_job(job_func, 'interval', minutes=2, start_date='2019-04-15 17:00:00' , end_date='2019-12-31 24:00:00') scheduler.start()
jitter振动参数,给每次触发添加一个随机浮动秒数,一般适用于多服务器,避免同时运行造成服务拥堵。
# 每小时(上下浮动120秒区间内)运行`job_function` scheduler.add_job(job_func, 'interval', hours=1, jitter=120)
3.3 cron 触发器
在特定时间周期性地触发,和Linux crontab格式兼容。它是功能最强大的触发器。
cron 参数:
| 参数 | 说明 |
| year(int or str) | 年,4位数字 |
| month(int or str) | 月(范围1-12) |
| day(int or str) | 日(范围1-31) |
| week(int or str) | 周(范围1-53) |
| day_of_week(int or str) | 周内第几天或者星期几(范围0-6或者mon,tue,wed,thu,fri,stat,sun) |
| hour(int or str) | 时(0-23) |
| minute(int or str) | 分(0-59) |
| second(int or str) | 秒(0-59) |
| start_date(datetime or str) | 最早开始日期(含) |
| end_date(datetime or str) | 最晚结束日期(含) |
| timezone(datetime.tzinfo or str) | 指定时区 |
表达式类型
| 表达式 | 参数类型 | 描述 |
|---|---|---|
* |
所有 | 通配符。例:minutes=*即每分钟触发 |
*/a |
所有 | 可被a整除的通配符。 |
a-b |
所有 | 范围a-b触发 |
a-b/c |
所有 | 范围a-b,且可被c整除时触发 |
xth y |
日 | 第几个星期几触发。x为第几个,y为星期几 |
last x |
日 | 一个月中,最后个星期几触发 |
last |
日 | 一个月最后一天触发 |
x,y,z |
所有 | 组合表达式,可以组合确定值或上方的表达式 |
注意:month和day_of_week参数分别接受的是英语缩写jan– dec 和 mon – sun
import datetime from apscheduler.schedulers.background import BackgroundScheduler def job_func(text): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) scheduler = BackgroundScheduler() # 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 job_func 任务 scheduler .add_job(job_func, 'cron', month='1-3,7-9',day='0, tue', hour='0-3') scheduler.start()
使用 scheduled_job() 装饰器添加任务:
@scheduler.scheduled_job('cron', id='my_job_id', day='last sun') def some_decorated_task(): print("I am printed at 00:00:00 on the last Sunday of every month!")
注意:夏令时问题
有些timezone时区可能会有夏令时的问题。这个可能导致令时切换时,任务不执行或任务执行两次。避免这个问题,可以使用UTC时间,或提前预知并规划好执行的问题。
pri# 在Europe/Helsinki时区, 在三月最后一个周一就不会触发;在十月最后一个周一会触发两次 sched.add_job(job_function, 'cron', hour=3, minute=30)
4. 配置调度程序
APScheduler提供了许多不同的方法来配置调度程序。您可以使用配置字典,也可以将选项作为关键字参数传递。您还可以先实例化调度程序,然后添加任务并配置调度程序。这样您就可以在任何环境中获得最大的灵活性
可以在BaseScheduler类的API引用中找到调度程序级别配置选项的完整列表 。调度程序子类还可以具有其各自API引用中记录的其他选项。各个任务存储和执行程序的配置选项同样可以在其API参考页面上找到。
假设您希望在应用程序中使用默认作业存储和默认执行程序运行BackgroundScheduler:
from apscheduler.schedulers.background import BackgroundScheduler scheduler = BackgroundScheduler() # 初始化程序
这将为您提供一个BackgroundScheduler,其MemoryJobStore(内存任务储存器)名为“default”,ThreadPoolExecutor(线程池执行器)名为“default”,默认最大线程数为10。
假如你现在有这样的需求,两个任务储存器分别搭配两个执行器;同时,还要修改任务的默认参数;最后还要改时区。可以参考下面例子,它们是完全等价的。
-
名称为“mongo”的MongoDBJobStore
-
名称为“default”的SQLAlchemyJobStore
-
名称为“ThreadPoolExecutor ”的ThreadPoolExecutor,最大线程20个
-
名称“processpool”的ProcessPoolExecutor,最大进程5个
-
UTC时间作为调度器的时区
-
默认为新任务关闭合并模式()
-
设置新任务的默认最大实例数为3
方法一:
from pytz import utc from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.jobstores.mongodb import MongoDBJobStore from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor jobstores = { 'mongo': MongoDBJobStore(), 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite') } executors = { 'default': ThreadPoolExecutor(20), 'processpool': ProcessPoolExecutor(5) } job_defaults = { 'coalesce': False, 'max_instances': 3 } scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方法二:
from apscheduler.schedulers.background import BackgroundScheduler # The "apscheduler." prefix is hard coded scheduler = BackgroundScheduler({ 'apscheduler.jobstores.mongo': { 'type': 'mongodb' }, 'apscheduler.jobstores.default': { 'type': 'sqlalchemy', 'url': 'sqlite:///jobs.sqlite' }, 'apscheduler.executors.default': { 'class': 'apscheduler.executors.pool:ThreadPoolExecutor', 'max_workers': '20' }, 'apscheduler.executors.processpool': { 'type': 'processpool', 'max_workers': '5' }, 'apscheduler.job_defaults.coalesce': 'false', 'apscheduler.job_defaults.max_instances': '3', 'apscheduler.timezone': 'UTC', })
方法三:
from pytz import utc from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore from apscheduler.executors.pool import ProcessPoolExecutor jobstores = { 'mongo': {'type': 'mongodb'}, 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite') } executors = { 'default': {'type': 'threadpool', 'max_workers': 20}, 'processpool': ProcessPoolExecutor(max_workers=5) } job_defaults = { 'coalesce': False, 'max_instances': 3 } scheduler = BackgroundScheduler() # ..这里可以添加任务 scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
更多请参考:https://apscheduler.readthedocs.io/en/latest/userguide.html#starting-the-scheduler
启动调度器
启动调度器是只需调用start()即可。除了BlockingScheduler,非阻塞调度器都会立即返回,可以继续运行之后的代码,比如添加任务等。
对于BlockingScheduler,程序则会阻塞在start()位置,所以,要运行的代码必须写在start()之前。
注意:调度器启动后,就不可以修改配置。
5. 添加任务
添加任务方法有两种:
-
通过调用add_job()
-
通过装饰器scheduled_job()
5.1 利弊:
-
第一种方法是最常用的;第二种方法是最方便的,但缺点就是运行时,不能修改任务。
-
第一种add_job()方法会返回一个apscheduler.job.Job实例,这样就可以在运行时,修改或删除任务。
在任何时候你都能配置任务。但是如果调度器还没有启动,此时添加任务,那么任务就处于一个暂存的状态。只有当调度器启动时,才会开始计算下次运行时间。
还有一点要注意,如果你的执行器或任务储存器是会序列化任务的,那么这些任务就必须符合:
-
回调函数必须全局可用
-
回调函数参数必须也是可以被序列化的
重要提醒!
如果在程序初始化时,是从数据库读取任务的,那么必须为每个任务定义一个明确的ID,并且使用replace_existing=True,否则每次重启程序,你都会得到一份新的任务拷贝,也就意味着任务的状态不会保存。
内置任务储存器中,只有MemoryJobStore不会序列化任务;内置执行器中,只有ProcessPoolExecutor会序列化任务。
建议:如果想要立刻运行任务,可以在添加任务时省略trigger参数
6. 移除任务
如果想从调度器移除一个任务,那么你就要从相应的任务储存器中移除它,这样才算移除了。有两种方式:
-
调用remove_job(),参数为:任务ID,任务储存器名称
-
在通过add_job()创建的任务实例上调用remove()方法
第二种方式更方便,但前提必须在创建任务实例时,实例被保存在变量中。对于通过scheduled_job()创建的任务,只能选择第一种方式。
当任务调度结束时(比如,某个任务的触发器不再产生下次运行的时间),任务就会自动移除。
job = scheduler.add_job(myfunc, 'interval', minutes=2) job.remove()
同样,通过任务的具体ID:
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id') scheduler.remove_job('my_job_id')
7. 暂停和恢复任务
通过任务实例或调度器,就能暂停和恢复任务。如果一个任务被暂停了,那么该任务的下一次运行时间就会被移除。在恢复任务前,运行次数计数也不会被统计。
暂停任务,有以下两个方法:
-
apscheduler.job.Job.pause()
-
apscheduler.schedulers.base.BaseScheduler.pause_job()
恢复任务
-
apscheduler.job.Job.resume()
-
apscheduler.schedulers.base.BaseScheduler.resume_job()
8. 获取任务列表
通过get_jobs()就可以获得一个可修改的任务列表。get_jobs()第二个参数可以指定任务储存器名称,那么就会获得对应任务储存器的任务列表。
print_jobs()可以快速打印格式化的任务列表,包含触发器,下次运行时间等信息。
修改任务
通过apscheduler.job.Job.modify()或modify_job(),你可以修改任务当中除了id的任何属性。
比如:
job.modify(max_instances=6, name='Alternate name')
如果想要重新调度任务(就是改变触发器),你能通过apscheduler.job.Job.reschedule()或reschedule_job()来实现。这些方法会重新创建触发器,并重新计算下次运行时间。
比如:
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
9. 关闭调度器
关闭方法如下:
scheduler.shutdown()
默认情况下,调度器会先把正在执行的任务处理完,再关闭任务储存器和执行器。但是,如果你就直接关闭,你可以添加参数:
scheduler.shutdown(wait=False)
上述方法不管有没有任务在执行,会强制关闭调度器。
10. 暂停、恢复任务进程
调度器可以暂停正在执行的任务:
scheduler.pause()
恢复任务:
scheduler.resume()
同时,也可以在调度器启动时,默认所有任务设为暂停状态。
scheduler.start(paused=True)
喜欢这篇文章?欢迎打赏~~


