

ZooKeeper学习总结 第一篇:ZooKeeper快速入门
1. 概述
Zookeeper是Hadoop的一个子项目,它是分布式系统中的协调系统,可提供的服务主要有:配置服务、名字服务、分布式同步、组服务等。
它有如下的一些特点:
- 简单
Zookeeper的核心是一个精简的文件系统,它支持一些简单的操作和一些抽象操作,例如,排序和通知。
- 丰富
Zookeeper的原语操作是很丰富的,可实现一些协调数据结构和协议。例如,分布式队列、分布式锁和一组同级别节点中的“领导者选举”。
- 高可靠
Zookeeper支持集群模式,可以很容易的解决单点故障问题。
- 松耦合交互
不同进程间的交互不需要了解彼此,甚至可以不必同时存在,某进程在zookeeper中留下消息后,该进程结束后其它进程还可以读这条消息。
- 资源库
Zookeeper实现了一个关于通用协调模式的开源共享存储库,能使开发者免于编写这类通用协议。
2. ZooKeeper的安装
- 独立模式安装
Zookeeper的运行环境是需要java的,建议安装oracle的java6.
可去官网下载一个稳定的版本,然后进行安装:http://zookeeper.apache.org/
解压后在zookeeper的conf目录下创建配置文件zoo.cfg,里面的配置信息可参考统计目录下的zoo_sample.cfg文件,我们这里配置为:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper-data/ clientPort=2181
tickTime:指定了ZooKeeper的基本时间单位(以毫秒为单位);
initLimit:指定了启动zookeeper时,zookeeper实例中的随从实例同步到领导实例的初始化连接时间限制,超出时间限制则连接失败(以tickTime为时间单位);
syncLimit:指定了zookeeper正常运行时,主从节点之间同步数据的时间限制,若超过这个时间限制,那么随从实例将会被丢弃;
dataDir:zookeeper存放数据的目录;
clientPort:用于连接客户端的端口。
- 启动一个本地的ZooKeeper实例
% zkServer.sh start
检查ZooKeeper是否正在运行
echo ruok | nc localhost 2181
若是正常运行的话会打印“imok”。
3. ZooKeeper监控
- 远程JMX配置
默认情况下,zookeeper是支持本地的jmx监控的。若需要远程监控zookeeper,则需要进行进行如下配置。
默认的配置有这么一行:
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quorum.QuorumPeerMain"
咱们在$JMXLOCALONLY后边添加jmx的相关参数配置:

ZOOMAIN="-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY
-Djava.rmi.server.hostname=192.168.1.8
-Dcom.sun.management.jmxremote.port=1911
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
org.apache.zookeeper.server.quorum.QuorumPeerMain"
这样就可以远程监控了,可以用jconsole.exe或jvisualvm.exe等工具对其进行监控。
- 身份验证
这里没有配置验证信息,如果需要请参见我的博文jvisualvm远程监控tomcat:http://www.cnblogs.com/leocook/p/jvisualvmandtomcat.html
4. Zookeeper的存储模型
Zookeeper的数据存储采用的是结构化存储,结构化存储是没有文件和目录的概念,里边的目录和文件被抽象成了节点(node),zookeeper里可以称为znode。Znode的层次结构如下图:

最上边的是根目录,下边分别是不同级别的子目录。
5. Zookeeper客户端的使用
- zkCli.sh
可使用./zkCli.sh -server localhost来连接到Zookeeper服务上。
使用ls /可查看根节点下有哪些子节点,可以双击Tab键查看更多命令。
- Java客户端
可创建org.apache.zookeeper.ZooKeeper对象来作为zk的客户端,注意,java api里创建zk客户端是异步的,为防止在客户端还未完成创建就被使用的情况,这里可以使用同步计时器,确保zk对象创建完成再被使用。
- C客户端
可以使用zhandle_t指针来表示zk客户端,可用zookeeper_init方法来创建。可在ZK_HOME\src\c\src\ cli.c查看部分示例代码。
6. Zookeeper创建Znode
Znode有两种类型:短暂的和持久的。短暂的znode在创建的客户端与服务器端断开(无论是明确的断开还是故障断开)连接时,该znode都会被删除;相反,持久的znode则不会。
 View Code
View Code这里我们使用了同步计数器CountDownLatch,在connect方法中创建执行了zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);之后,下边接着调用了CountDownLatch对象的await方法阻塞,因为这是zk客户端不一定已经完成了与服务端的连接,在客户端连接到服务端时会触发观察者调用process()方法,我们在方法里边判断一下触发事件的类型,完成连接后计数器减一,connect方法中解除阻塞。
还有两个地方需要注意:这里创建的znode的访问权限是open的,且该znode是持久化存储的。
测试类如下:
public class CreateGroupTest {
private static String hosts = "192.168.1.8";
private static String groupName = "zoo";
private CreateGroup createGroup = null;
/**
* init
* @throws InterruptedException
* @throws KeeperException
* @throws IOException
*/
@Before
public void init() throws KeeperException, InterruptedException, IOException {
createGroup = new CreateGroup();
createGroup.connect(hosts);
}
@Test
public void testCreateGroup() throws KeeperException, InterruptedException {
createGroup.create(groupName);
}
/**
* 销毁资源
*/
@After
public void destroy() {
try {
createGroup.close();
createGroup = null;
System.gc();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
由于zk对象的创建和销毁代码是可以复用的,所以这里我们把它分装成了接口:
View Code7. Zookeeper删除Znode
/**
* 删除分组
* @author leo
*
*/
public class DeleteGroup extends ConnectionWatcher {
public void delete(String groupName) {
String path = "/" + groupName;
try {
List<String> children = zk.getChildren(path, false);
for(String child : children){
zk.delete(path + "/" + child, -1);
}
zk.delete(path, -1);//版本号为-1,
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
zk.delete(path,version)方法的第二个参数是znode版本号,如果提供的版本号和znode版本号一致才会删除这个znode,这样可以检测出对znode的修改冲突。通过将版本号设置为-1,可以绕过这个版本检测机制,无论znode的版本号是什么,都会直接将其删除。
测试类:
View Code8. Zookeeper的相关操作
ZooKeeper中共有9中操作:
create:创建一个znode
delete:删除一个znode
exists:测试一个znode
getACL,setACL:获取/设置一个znode的ACL(权限控制)
getChildren:获取一个znode的子节点
getData,setData:获取/设置一个znode所保存的数据
sync:将客户端的znode视图与ZooKeeper同步
这里更新数据是必须要提供znode的版本号(也可以使用-1强制更新,这里可以执行前通过exists方法拿到znode的元数据Stat对象,然后从Stat对象中拿到对应的版本号信息),如果版本号不匹配,则更新会失败。因此一个更新失败的客户端可以尝试是否重试或执行其它操作。
9. ZooKeeper的API
ZooKeeper的api支持多种语言,在操作时可以选择使用同步api还是异步api。同步api一般是直接返回结果,异步api一般是通过回调来传送执行结果的,一般方法中有某参数是类AsyncCallback的内部接口,那么该方法应该就是异步调用,回调方法名为processResult。
10. 观察触发器
可以对客户端和服务器端之间的连接设置观察触发器(后边称之为zookeeper的状态观察触发器),也可以对znode设置观察触发器。
- 状态观察器
zk的整个生命周期如下:
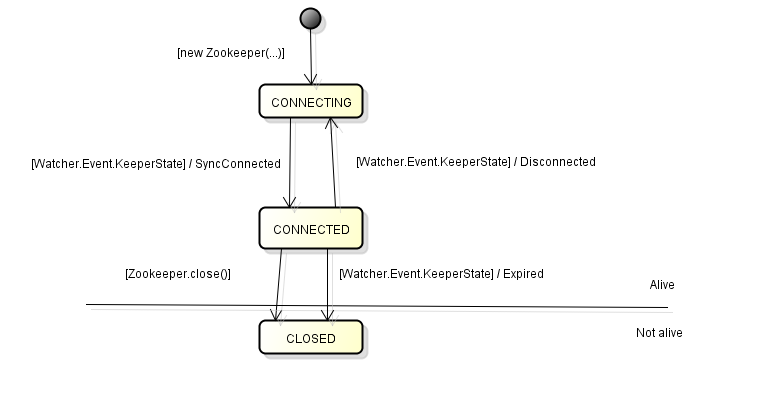
可在创建zk对象时传入一个观察器,在完成CONNECTING状态到CONNECTED状态时,观察器会触发一个事件,该触发的事件类型为NONE,通过event.getState()方法拿到事件状态为SyncConnected。有一点需要注意的就是,在zk调用close方法时不会触发任何事件,因为这类的显示调用是开发者主动执行的,属于可控的,不用使用事件通知来告知程序。这一块在下篇博文还会详细解说。
- 设置znode的观察器
可以在读操作exists、getChildren和getData上设置观察,在执行写操作create、delete和setData将会触发观察事件,当然,在执行写的操作时,也可以选择是否触发znode上设置的观察器,具体可查看相关的api。
当观察的znode被创建、删除或其数据被更新时,设置在exists上的观察将会被触发;
当观察的znode被删除或数据被更新时,设置在getData上的观察将会被触发;
当观察的znode的子节点被创建、删除或znode自身被删除时,设置在getChildren上的观察将会被触发,可通过观察事件的类型来判断被删除的是znode还是它的子节点。

对于NodeCreated和NodeDeleted根据路径就能发现是哪个znode被写;对于NodeChildrenChanged可根据getChildren来获取新的子节点列表。
注意:在收到收到触发事件到执行读操作之间,znode的状态可能会发生状态,这点需要牢记。
至此,编写简单的zookeeper应该是可以的了,下篇博文咱们来深入探讨zookeeper的相关知识。
参考地址:http://zookeeper.apache.org/doc/r3.4.6/
参考书籍:《hadoop权威指南》
喜欢这篇文章?欢迎打赏~~


