
一、Hive基本原理
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类似sql查询(HQL)功能,可以将sql语句转换为MapReduce任务,避免开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive将元数据存储在数据库(RDBMS)中,比如MySQL、Derby中。Hive有三种模式连接到数据,其方式是:单用户模式,多用户模式和远程服务模式。(也就是内嵌模式
、本地模式、远程模式)。
二、Hive的体系结构:
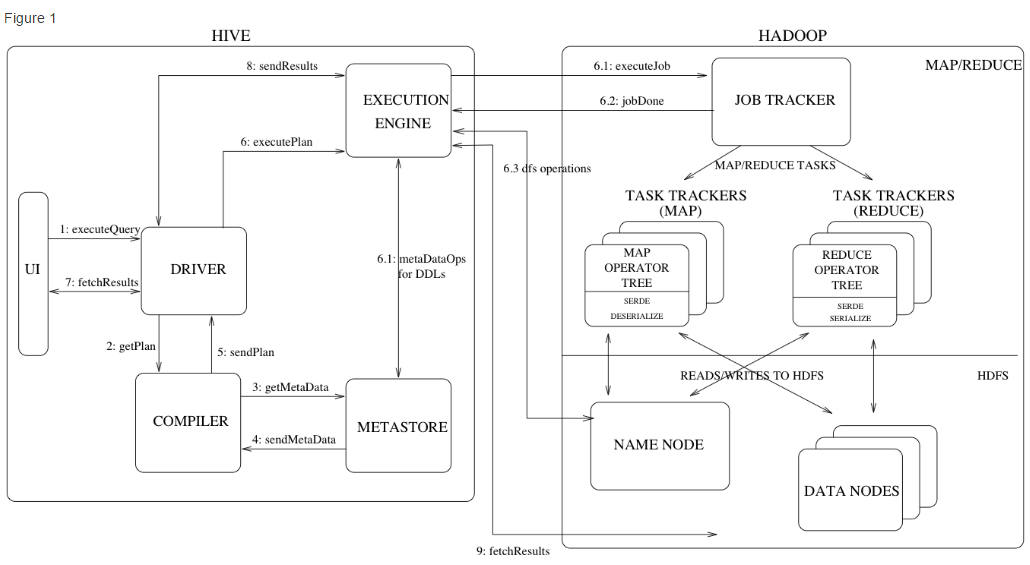
注:图片来源于网络,如有侵权,请联系删除
Metastore:元数据,存储系统目录以及关于表、列、分区等的元数据。
Driver :驱动,控制 HiveQL 生命周期的组件,当 HiveQL 查询穿过 Hive时,该驱动管理着会话句柄以及任何会话的统计。
Query Compiler:查询编译器, 将HQL编译成有向无环图(directed acyclic graph, DAG)形式的map/reduce任务。
Execution Engine :执行引擎 ,依相依性顺序(dependency order)执行由编译器产生的任务。
HiveServer : 提供健壮的接口(thrift interface )、JDBC/ODBC 服务以及整合 Hive 和其它应用。
Client :类似命令行接口CLI(Command Line Interface), web UI 以及JDBC/ODBC驱动。
执行过程:
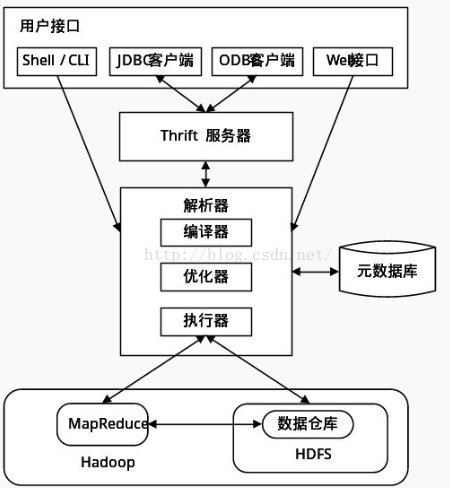
Hive的工作原理简单的说就是一个查询引擎,执行顺序是:
接收SQL
词法分析/语法分析:使用antlr将SQL语句解析成抽象语法树(AST)
语义分析:从Metastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
逻辑计划生成:生成逻辑计划--算子树
逻辑计划优化:对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
物理计划生成:将逻辑计划生成包含由MapReduce任务组成的DAG的物理计划
物理计划执行:将DAG发送到Hadoop集群进行执行
最后返回查询结果
三、HIVE中的表介绍

Hive的存储是建立在Hadoop文件系统之上的,其主要包括四种表类型:
Internal Table : 内部表
External Table :外部表
Partition Table : 分区表
Bucket Table :桶表
四、Hive数据库命令
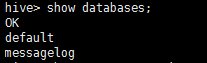
1、显示所有数据库:show databases;
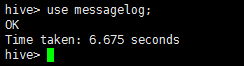
2、使用某一个数据库,例如messagelog:use messagelog;
五、Hive建表操作
1、Internal Table
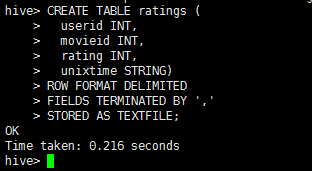
CREATE TABLE ratings ( userid INT, movieid INT, rating INT, unixtime STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
执行截图:
插入数据:
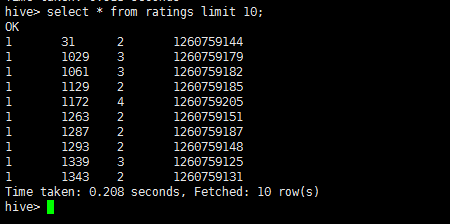
LOAD DATA LOCAL INPATH '/opt/ratings.txt' OVERWRITE INTO TABLE ratings;
执行截图:

查询表:
2、External Table
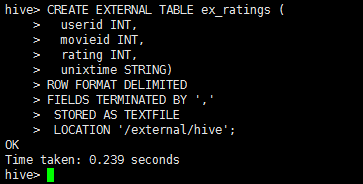
CREATE EXTERNAL TABLE ex_ratings ( userid INT, movieid INT, rating INT, unixtime STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/external/hive';
执行结果:
插入数据:
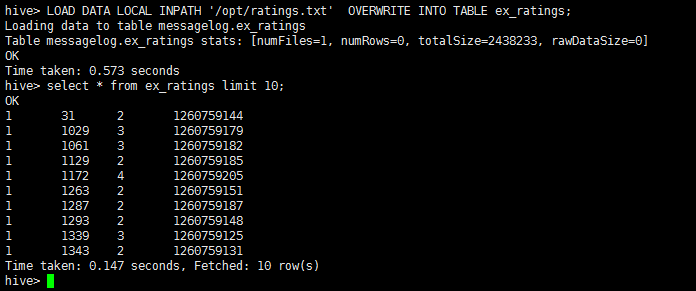
LOAD DATA LOCAL INPATH '/opt/ratings.txt' OVERWRITE INTO TABLE ex_ratings;
执行结果:
数据文件hdfs存储路径:

我们可以看到数据文件已经上传到对应的hdfs目录下。
3、Partition Table
建表语句:
CREATE TABLE part_ip_test(id int,
name string,
ip STRING)
PARTITIONED BY(country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
执行结果:

插入数据:
load data local inpath '/opt/ip_china.txt' overwrite into table part_ip_test partition(country='china'); load data local inpath '/opt/ip_japan.txt' overwrite into table part_ip_test partition(country='japan');
执行结果:

4、Bucket Table
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
要使用桶表,要先进行如下环境变量设置:
set hive.enforce.bucketing = true;
建表语句:
CREATE TABLE buck_ip_test(id int,
name string,
ip STRING,
country STRING)
clustered by (country) sorted by(name) into 4 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
插入数据:
insert overwrite table buck_ip_test select * from part_ip_test;
查询结果:
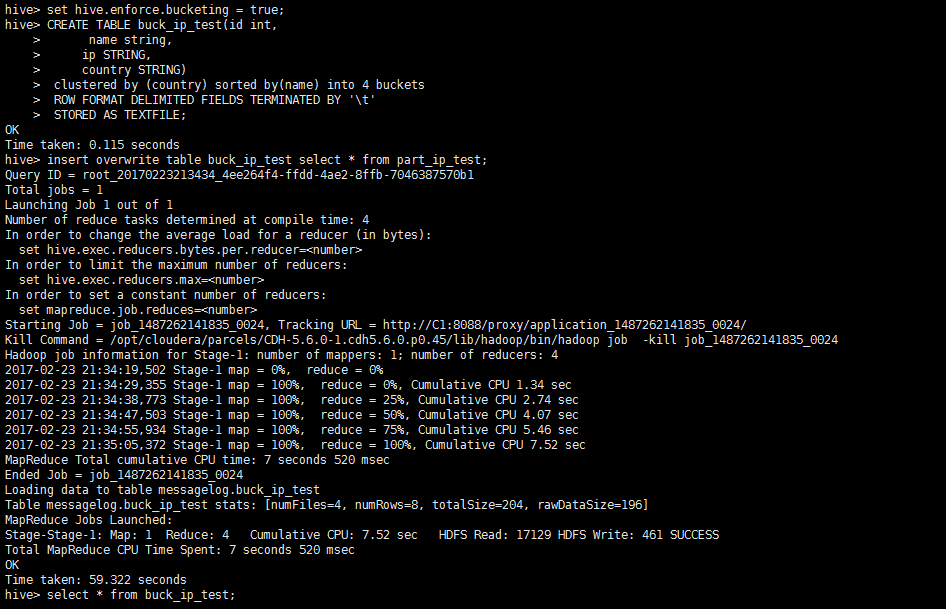
查看hdfs文件:
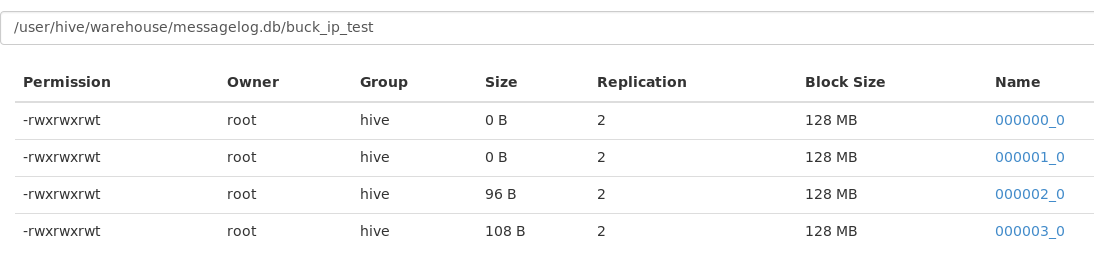
可以看到生成了4个分区文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号