

mapreduce中的reduce数量是由什么来进行控制的呢?
1、numReduceTasks
如下是用来进行测试的一段wordcount的代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PartTest {
public static void main(String[] args){
Path inFile = new Path(args[0]);
Path outFile = new Path(args[1]);
Job job;
try {
job = Job.getInstance();
job.setJarByClass(PartTest.class);
FileInputFormat.addInputPath(job , inFile);
FileOutputFormat.setOutputPath(job, outFile);
job.setReducerClass(PartTestreducer.class);
job.setMapperClass(PartTestmapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
try {
job.waitForCompletion(true);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
/**
* InputFormat描述map-reduce中对job的输入定义
* setInputPaths():为map-reduce job设置路径数组作为输入列表
* setInputPath():为map-reduce job设置路径数组作为输出列表
*/
}
}
class PartTestmapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final IntWritable one = new IntWritable(1);
//private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
/*
String line = value.toString();
for(String s : line.split("\\s+")){
//if(s.length() > 0){
context.write(new Text(s), one);
//}
}
*/
String[] line = value.toString().split("\\W+");
for(int i = 0 ; i<= line.length-1 ;i++){
String s = line[i];
context.write(new Text(s), new IntWritable(1));
}
/*
String line = value.toString();
Text word = new Text();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
*/
}
}
class PartTestreducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum = 0;
for(IntWritable i : arg1){
sum += i.get();
}
context.write(arg0, new IntWritable(sum));
}
}
将上述代码打包成 parttest.jar,并上传到服务器的opt目录
创建文件/opt/test.txt,并上传到hdfs的/tmp目录下
文本内容如下:
hello world hello test test hadoop hadoop hdfs hive sql sqoop
在服务器上执行:
hadoop jar parttest.jar "PartTest" "/tmp/test.txt" "/tmp/part/out1"
我们可以看到日志输出文件:

在这里可以看到只启动了一个reduce任务
然后使用
hadoop fs -ls /tmp/part/out1
可以看到只生成了一个分区文件part-r-00000:

如果我们把上述代码进行修改:
job = Job.getInstance();
job.setJarByClass(PartTest.class);
FileInputFormat.addInputPath(job , inFile);
FileOutputFormat.setOutputPath(job, outFile);
job.setNumReduceTasks(3);
job.setReducerClass(PartTestreducer.class);
job.setMapperClass(PartTestmapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
我们在代码里新加了一行 :job.setNumReduceTasks(3);
将代码重新打包上传,执行:
hadoop jar parttest.jar "PartTest" "/tmp/test.txt" "/tmp/part/out2"
将结果输出到/tmp/part/out2目录
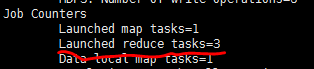
可以看到启动了3个reduce任务。
然后使用
hadoop fs -ls /tmp/part/out2
可以看到/tmp/part/out2文件夹中生成了3个part文件:

所以可以使用 setNumReduceTasks 来设置reduce的数量
2、mapreduce的分区
我们在原来的代码的最后一段加上如下代码:
class PartTestPartitioner extends Partitioner<Text,IntWritable>{
@Override
//参数含义:第一个参数为map任务的outputkey。class,第二个参数为map任务的outputvalue。class,第三个参数为分区的数量,默认为1
public int getPartition(Text key, IntWritable value, int numPartitions) {
// TODO Auto-generated method stub
if(key.toString().startsWith("h")){
return 0%numPartitions;
}
else if(key.toString().startsWith("s")){
return 1%numPartitions;
}
else{
return 2%numPartitions;
}
}
}
这段代码的含义是:
将以h开头的统计结果输出到part-r-00000
将以s开头的统计结果输出到part-r-00001
将以其他字母开头的统计结果输出到part-r-00002
对原有代码进行如下修改:
job = Job.getInstance();
job.setJarByClass(PartTest.class);
FileInputFormat.addInputPath(job , inFile);
FileOutputFormat.setOutputPath(job, outFile);
job.setNumReduceTasks(3);
job.setPartitionerClass(PartTestPartitioner.class);
job.setReducerClass(PartTestreducer.class);
job.setMapperClass(PartTestmapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
新加了一行代码:job.setPartitionerClass(PartTestPartitioner.class);
将代码重新打包上传,执行:
hadoop jar parttest.jar "PartTest" "/tmp/test.txt" "/tmp/part/out3"
将结果输出到/tmp/part/out3目录
可以看到启动了3个reduce任务。
然后使用
hadoop fs -ls /tmp/part/out3
可以看到/tmp/part/out3文件夹中生成了3个part文件:

分别查看三个文件:

可以看到输出结果已经分别输出到对应的分区文件。
注意:
job.setNumReduceTasks(3);
job.setPartitionerClass(PartTestPartitioner.class);
NumReduceTasks的数量不能小于partitioner的数量,否则结果会写到part-r-00000中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号