

Selenium3+python3自动化(三十二)--4类32种定位方法(find_element_by_xx, find_elements_by_xx, find_element)
前言
slenium自动化,最重要的四步:定位元素、操作元素、获取返回值、断言,可见定位方法的重要性。
一、三十二种定位方法
下面八种是大家熟悉的,经常会用到的
1.id定位:find_element_by_id(id)
2.name定位:find_element_by_name(name)
3.class定位:find_element_by_class_name(name)
4.tag定位:find_element_by_tag_name(name)
5.link定位:find_element_by_link_text(link_text)
6.partial_link定位:find_element_by_partial_link_text(link_text)
7.xpath定位:find_element_by_xpath(xpath)
8.css定位:find_element_by_css_selector(css_selector)
下面八种是复数形式
1.id复数定位:find_elements_by_id(id)
2.name复数定位:find_elements_by_name(name)
3.class复数定位:find_elements_by_class_name(name)
4.tag定位:find_elements_by_tag_name(name)
5.link定位:find_elements_by_link_text(link_text)
6.partial_link定位:find_elements_by_partial_link_text(link_text)
7.xpath定位:find_elements_by_xpath(xpath)
8.css定位:find_elements_by_css_selector(css_selector)
下面2类不太常用,同样每类也有八种
find_element(by='id',value=None)
find_elements(by='id',value=None)
二、element和elements的区别
1.element方法定位到的是单数,是直接定位到元素,可直接操作
2.elements方法是复数,定位到的是一组元素,返回的是list队列
3.可以用type()函数查看数据类型
4.打印这个返回的内容,看看有什么不一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # coding:utf-8from selenium import webdriver# from selenium.webdriver.common.by import Byimport timedriver=webdriver.Chrome()driver.get("https://www.baidu.com")a=driver.find_element_by_id("kw")a.send_keys("a")time.sleep(2)bb=driver.find_elements_by_id("kw")bb[0].send_keys("_bb")time.sleep(2)c=driver.find_element("id","kw")c.send_keys("_c")time.sleep(2)dd=driver.find_elements("id","kw")dd[0].send_keys("_dd")print("a的类型:{},值:{}".format(type(a),a))print("bb的类型:{},值:{}".format(type(bb),bb))print("c的类型:{},值:{}".format(type(c),c))print("dd的类型:{},值:{}".format(type(dd),dd)) |
运行结果:
1 2 3 4 | a的类型:<class 'selenium.webdriver.remote.webelement.WebElement'>,值:<selenium.webdriver.remote.webelement.WebElement (session="864b09ef2caa45ac7fdf25ac01bfc3cb", element="d2671363-8edd-4ed8-9072-ffd38bee4ae6")>bb的类型:<class 'list'>,值:[<selenium.webdriver.remote.webelement.WebElement (session="864b09ef2caa45ac7fdf25ac01bfc3cb", element="d2671363-8edd-4ed8-9072-ffd38bee4ae6")>]c的类型:<class 'selenium.webdriver.remote.webelement.WebElement'>,值:<selenium.webdriver.remote.webelement.WebElement (session="864b09ef2caa45ac7fdf25ac01bfc3cb", element="d2671363-8edd-4ed8-9072-ffd38bee4ae6")>dd的类型:<class 'list'>,值:[<selenium.webdriver.remote.webelement.WebElement (session="864b09ef2caa45ac7fdf25ac01bfc3cb", element="d2671363-8edd-4ed8-9072-ffd38bee4ae6")>] |
三、elements定位方法
1.这里重点介绍下用elements方法如何定位元素,当一个页面上有很多个属性相同的元素,然后父元素的属性也比较模糊,不太好定位。
这个时候不用怕,换个思维,别老想着一次定位到,可以先把相同属性的元素找出来,取对应的第几个就可以了。
2.如下图,百度页面上有六个class一样的元素,我要定位“地图”这个元素
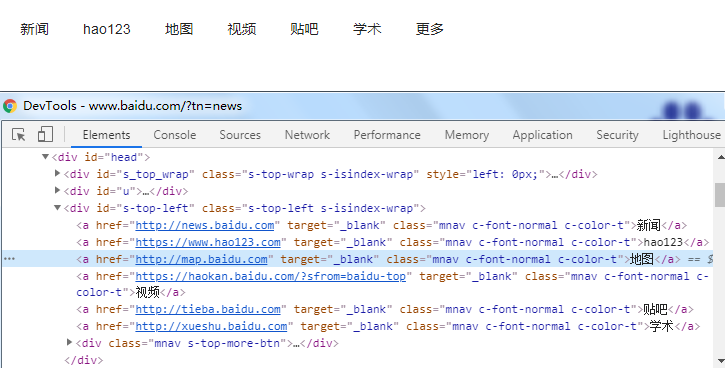
3.取对应下标即可定位了
1 2 3 4 5 6 7 8 | # coding:utf-8from selenium import webdriverdriver=webdriver.Chrome()driver.get("https://www.baidu.com")l=driver.find_elements_by_xpath("//div[@id='head']/div[3]/a")#地图在第3个位置print(l[2].text)l[2].click() |
运行结果:
1 |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异