

python接口自动化 小结
requests
发送http请求类型:get、post、put、delete、head
get 参数:params
值:字典格式
嵌套列表
array数组
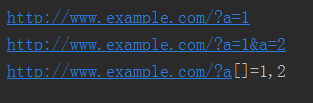
import requests
from urllib.parse import unquote
url="http://www.example.com"
p1={"a":"1"}
r1=requests.get(url,params=p1) #字典格式
print(r1.url)
p2=[["a","1"],["a","2"]] #嵌套列表
r2=requests.get(url,params=p2)
print(r2.url)
p3={"a[]":"1,2"} #字典,传array数组
r3=requests.get(url,params=p3)
print(unquote(r3.url))
运行结果
post
1.参数:data,
值:字典格式 ;
元组列表(("a","b"),("a","b"),("c","e"));
字符串json.dumps(字典格式);"xml格式"(注意:字符串中内容跨行,使用\)
2.参数:json ,值:字典格式,自动转码(字符串)
3.参数:files,值:{“键名”:(“文件名”,open(“文件名”,“rb”),“image/jpeg”)}
某一位置上传多图,
f={
(“键名”,(“文件名1”,open(“文件名1”,“rb”),“image/jpeg”)),
(“键名”,(“文件名2”,open(“文件名2”,“rb”),“image/jpeg”)),
}
s.post(url,files=f)
如何判断post请求中使用什么参数?可以通过fiddler抓包请求,查看Inspectors——JSON中显示数据,则使用json参数;查看Inspectors——WebForms中显示数据,则使用data参数。
响应结果
r.status_code; r.text; r.text.encode("utf-8"); r.text.encode("utf-8").decode('unicode_escape') #unicode解码; r.content; r.encoding; r.headers; r.url; r.json();
r.raw;
SSL证书验证
requests可以为HTTPS请求验证SSL证书,verify=True默认是开启的。
不启用fiddler不报SSL问题;启用fiddler抓包报SSLError;
解决办法:1.verify=False,但出现InsecureRequestWarning。
忽略Warning三种方法:
import requests
import warnings
#warnings.filterwarnings("ignore") #方式1
#requests.packages.urllib3.disable_warnings()#方式2
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)#方式3
r=requests.get("https://www.baidu.com",verify=False)
print(r.status_code)
cookie绕过验证码登录
1.fiddler抓登录后cookie
2.主要请求如下:
s=requests.session()
#添加cookie
c=requests.cookies.RequestsCookieJar()
c.set("名1","值1")
c.set("名1","值1")
s.cookies.update(c)
print(s.cookies)
会话对象(保持会话)
s=requests.session()
s.get(...)
s.post(...)
requests-html爬虫框架
hs=HTMLSession()
hr=hs.get(网址)
hlinkes=hr.html.links #获取页面上的所有链接
alinkes=hlinkes.absolute_links #获取绝对路径链接
提取参数(文本内容):css定位支持,hr.html.find("css语法",first=True).text
xpath ,hr.html.xpath("xpath语法",first=True).text
当然这里也可以通过lxml.etree 的 xpath,python正则来提取,直接使用requests或requests.session()请求
requests-html支持JavaScript渲染;加上,hr.html.render(),类似于手工在浏览器上输入url。
不加,只有一条请求,加上可以有n条请求。
参数关联,提取参数
cookies参数关联,使用requests.session()请求就自动关联了
提取参数:针对字符串取值,python正则表达式re.findall("开头(.+?)结尾",字符串格式);
lxml.etree 通过返回的html,解析出想要的text;a=etree.HTML(r.content); b=a.xpath("//*[@id="block"]")[0].get("value")
针对dict类型取值,jsonpath.jsonpath(字典格式,jsonpath表达式)
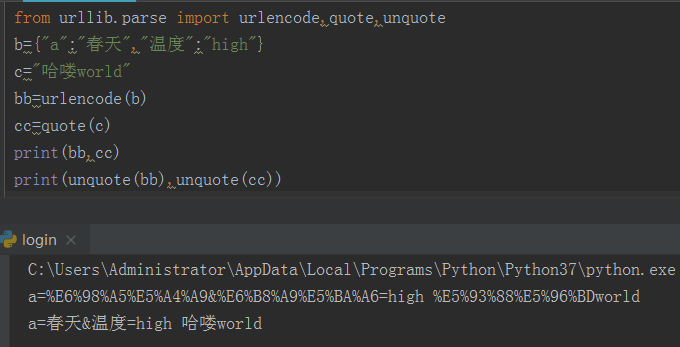
urlencode编码 如,%E7%94%
requests库发送请求时,会自动对url进行urlencode编码并发送,可通过r.url查看发送的url
如何自己对url进行urlencode编码?urlencode方法传字典参数,quote方法传字符串参数
如何对返回数据有urlencode编码的字符串解码?使用unquote
md5加密
import hashlib
#方式1
a=hashlib.md5()
a.update("123456".encode('utf-8'))
print(a.hexdigest())
#方式2
b=hashlib.md5('123456'.encode('utf-8'))
print(b.hexdigest())
重定向(Location)
301 永久性重定向,302 暂时性转移
默认情况下,allow_redirects=True是启用重定向的。
禁用重定向,allow_redirects=False
requests-toolsbelt
表单提交 fields={"键1":"值1","键2":"值2"}
多个文件参数名重复,使用list类型
注意:fields= 可不用写
from requests_boolbelt import MultipartEncoder
import requests
s=requests.session()
m=MultipartEncoder(
fields=[
("名1",("文件名",open("文件名","rb"),"image/jpeg")), #附件
("名1",("文件名1",open("文件名1","rb"),"image/jpeg")), #附件1
(“名2”,"值3"),
])
s.post(url,data=m,headers={'Content-Type':m.content_type})
elapsed
从发送请求的第一个字节到完成对头的解析所用的时间。
获取响应时间 r.elapsed.total_seconds()
timeout超时
requests发请求的时候有个默认的超时时间,这个时间在20秒左右
timeout=1。超过1s,就会抛出异常。
失败重试 max_retries
Requests自带一个传输适配器,也就是HTTPAdapter
每当Session被初始化,就会有适配器附着在Session上,其中一个供HTTP使用,另一个供HTTPS使用。
from requests.adapters import HTTPAdapter
s=requests.session()
s.mount('http://',HTTPAdapter(max_retries=3))#重试3次
s.mount('https://',HTTPAdapter(max_retries=3))
上传文件时自动判断文件类型(filetype)

如下,由文件路径,得到上传附件的部分参数
import filetype
import os
rp="D:\\ch.jpg"
t=filetype.guess(rp).mime
print(t)
pname=os.path.split(rp)[1]
#post请求files参数值的部分内容
print('("{}",open("{}","rb"),"{}")'.format(pname,rp,t))
运行结果


