爬虫大作业
1.选一个自己感兴趣的主题(所有人不能雷同)。
我比较感兴趣的是戏剧网里的京剧 网址:http://www.xijucn.com/html/jingju/list_1_1.html
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
网页的页面是:
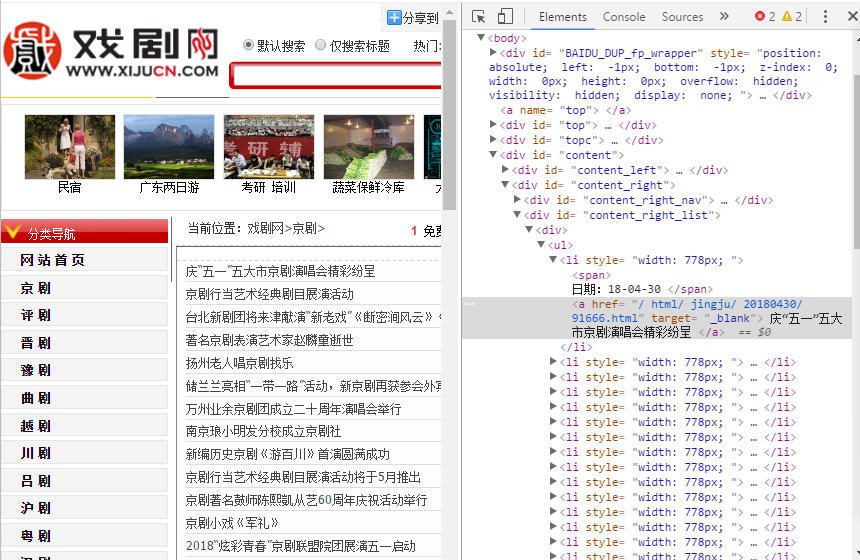
打开网页的详情页面:
def getNewDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') news = {} news['title'] = soupd.select('.show-title')[0].text info = soupd.select('.show-info')[0].text c = soupd.select('#content')[0].text # 正文 ws = info.lstrip('发布时间:')[:19] # 发布时间 news['dati'] = datetime.strptime(ws, '%Y-%m-%d %H:%M:%S') news['description'] = soupd.select('.news_description')[0].text.strip() # 描述 if info.find('来源:') > 0: news['source'] = info[info.find('来源:'):].split()[0].lstrip('来源:') else: news['source'] = 'none' writeNewsDetail(news['content']) news['newsUrl'] = newsUrl # 链接 return (news)
爬取标题:页面的标题都装在Li标签里的style="width:778px"里
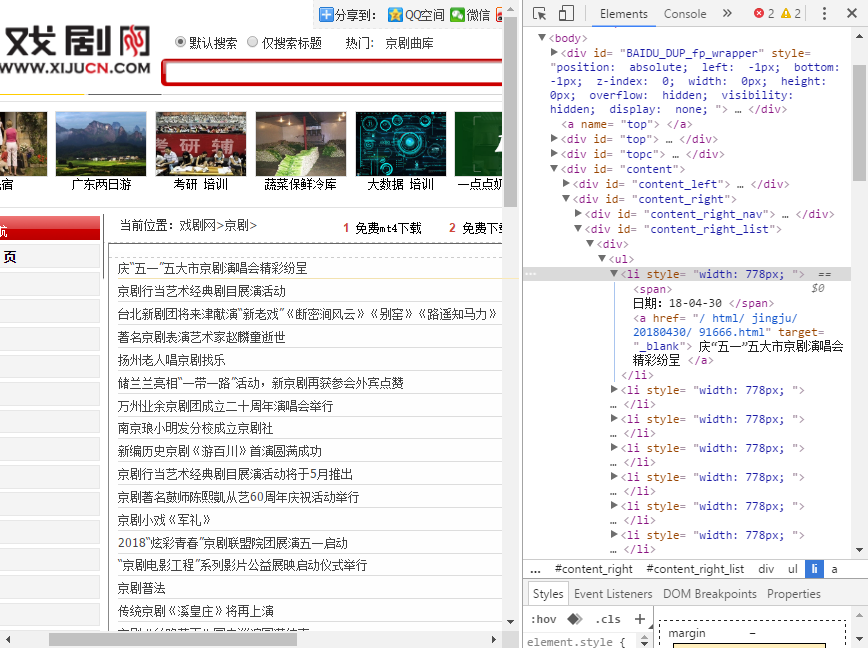
爬取网页中前页的标题并保存:
for i in range(0, 10): pages = i; nexturl = 'http://www.xijucn.com/html/jingju/list_1_1.html' reslist = requests.get(nexturl) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') for news in soup_list.find_all('li',style='width:778px;'): print(news.text) f = open('opera.txt', 'a', encoding='utf-8') f.write(news.text) f.close()

但是爬取的数据有些出现了乱码 导致后面找词语或数字和词云的生成不明显
爬取标题中出现词语或者数字和字母次数最多的前30
title_dict = changeTitleToDict()
dictList = list(title_dict.items())
dictList.sort(key=lambda x: x[1], reverse=True)
# f = open('wordcount.txt', 'a', encoding='utf-8')
# for i in range(30):
# print(dictList[i])
# f.write(dictList[i][0] + ' ' + str(dictList[i][1]) + '\n')
# f.close()
wc={}
f = open('number.txt', 'a',encoding="utf-8")
for i in range(150):
print(dictList[i])
f.write(dictList[i][0] + ':' + str(dictList[i][1]) + '\n')
wc[dictList[i][0]]=dictList[i][1]
f.close()

3.对爬了的数据进行文本分析,生成词云。
from PIL import Image, ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator font = r'C:\Windows\Fonts\simhei.TTF' # 引入字体 title_dict = changeTitleToDict() # 读取背景图片 image = Image.open('./路飞.jpg') graph = np.array(image) wc = WordCloud(font_path=font, background_color='White', mask=graph, max_words=200) wc.generate_from_frequencies(title_dict) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.axis("off") plt.show()
选择的图片:

生成的图片:

4.描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
1).在导入wordcloud无法安装
我先从phton中导入会提示失败,之后我在cmd中下载导入还是失败了。忘记截图了,没有图片
解决:
在https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud中找到相对应的安装包下载

后从cmd中下载带入,开始时因为没有注意地址和文件名字的全称在下载中出现了许多因为我粗心而出现的问题,后来慢慢的改过来了。
下载要在phton中修改才可以使用,打开项目选择file-->settings...-->project-projiect interpreter右边选择上方长条框,选择Show All...,接着选择System Interpreter就可以了
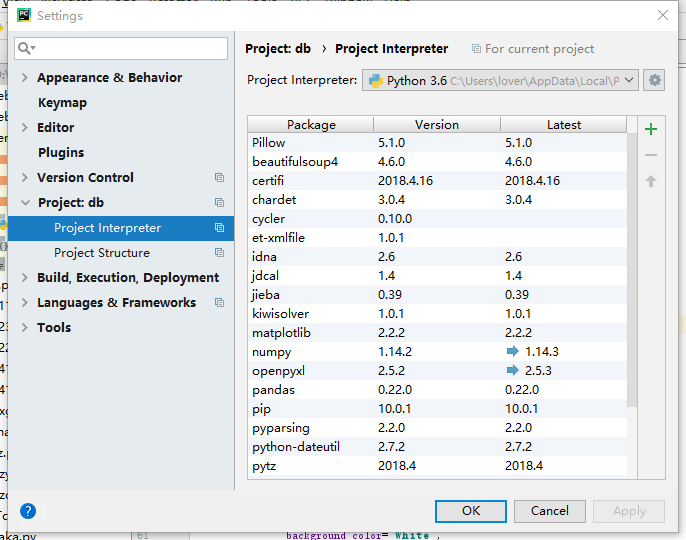
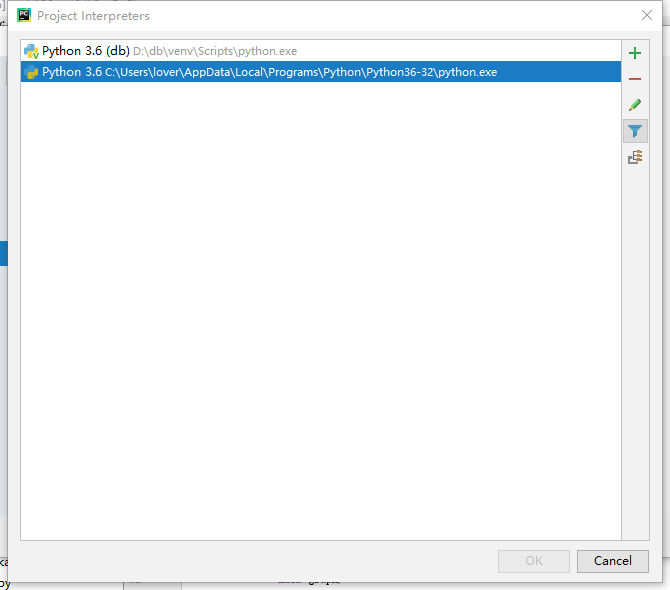
2).在爬取数据时保存会出现一些乱码,暂时没解决。
5.最后提交爬取的全部数据、爬虫及数据分析源代码。
import requests from bs4 import BeautifulSoup import jieba pageUrl = 'http://www.xijucn.com/html/jingju/list_1_1.htmll' def getListPage(pageUrl): # 一个列表页的全部信息 res = requests.get(pageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') newslist = [] for news in soup.body.li.a.attrs['href']: if len(news.select('.news-list-title')) > 0: newsUrl = news.select('a')[0].attrs['href'] # 连接 newslist.append(getNewDetail(newsUrl)) # t = news.select('h1')[0].text.strip() # 标题 return (newslist) def getNewDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') news = {} news['title'] = soupd.select('.show-title')[0].text info = soupd.select('.show-info')[0].text c = soupd.select('#content')[0].text # 正文 ws = info.lstrip('发布时间:')[:19] # 发布时间 news['dati'] = datetime.strptime(ws, '%Y-%m-%d %H:%M:%S') news['description'] = soupd.select('.news_description')[0].text.strip() # 描述 if info.find('来源:') > 0: news['source'] = info[info.find('来源:'):].split()[0].lstrip('来源:') else: news['source'] = 'none' writeNewsDetail(news['content']) news['newsUrl'] = newsUrl # 链接 return (news) for i in range(0, 10): pages = i; nexturl = 'http://www.xijucn.com/html/jingju/list_1_1.html' reslist = requests.get(nexturl) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') for news in soup_list.find_all('li',style='width:778px;'): print(news.text) f = open('opera.txt', 'a', encoding='utf-8') f.write(news.text) f.close() # 把所有题目里的多余符号去掉 def changeTitleToDict(): f = open("opera.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) delWord = {"。", "“", "”", "《", "》", "(", ")", "?", "(", ")", ", ", " ;", ":", "!", "、" } stringSet = set(stringList) - delWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) # print(title_dict) return title_dict # 统计前30出现的词语排序,保存在wordcound.txt title_dict = changeTitleToDict() dictList = list(title_dict.items()) dictList.sort(key=lambda x: x[1], reverse=True) # f = open('wordcount.txt', 'a', encoding='utf-8') # for i in range(30): # print(dictList[i]) # f.write(dictList[i][0] + ' ' + str(dictList[i][1]) + '\n') # f.close() wc={} f = open('number.txt', 'a',encoding="utf-8") for i in range(150): print(dictList[i]) f.write(dictList[i][0] + ':' + str(dictList[i][1]) + '\n') wc[dictList[i][0]]=dictList[i][1] f.close() # 生成词云 from PIL import Image, ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator font = r'C:\Windows\Fonts\simhei.TTF' # 引入字体 title_dict = changeTitleToDict() # 读取背景图片 image = Image.open('./路飞.jpg') graph = np.array(image) wc = WordCloud(font_path=font, background_color='White', mask=graph, max_words=200) wc.generate_from_frequencies(title_dict) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.axis("off") plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号