结对项目
一,Github项目地址:https://github.com/candy07213/MyAPP
https://github.com/Moyjing/Myapp
结对成员:3217004686 莫怡静 3217004687 唐小艳
二,PSP表格:
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
50 |
65 |
|
· Estimate |
· 估计这个任务需要多少时间 |
50 |
65 |
|
Development |
开发 |
1770 |
2045 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
150 |
130 |
|
· Design Spec |
· 生成设计文档 |
60 |
55 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
40 |
60 |
|
· Coding Standard |
· 代码规范(为目前的开发制定合适的规范) |
40 |
50 |
|
· Design |
· 具体设计 |
120 |
100 |
|
· Coding |
· 具体编码 |
1200 |
1450 |
|
· Code Review |
· 代码复审 |
70 |
90 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
90 |
110 |
|
Reporting |
报告 |
160 |
140 |
|
· Test Report |
· 测试报告 |
90 |
80 |
|
· Size Measurement |
· 计算工作量 |
30 |
30 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
40 |
30 |
|
合计 |
|
1980 |
2250 |
三,效能分析:
效能分析用JProfiler测试了CPU占用时间
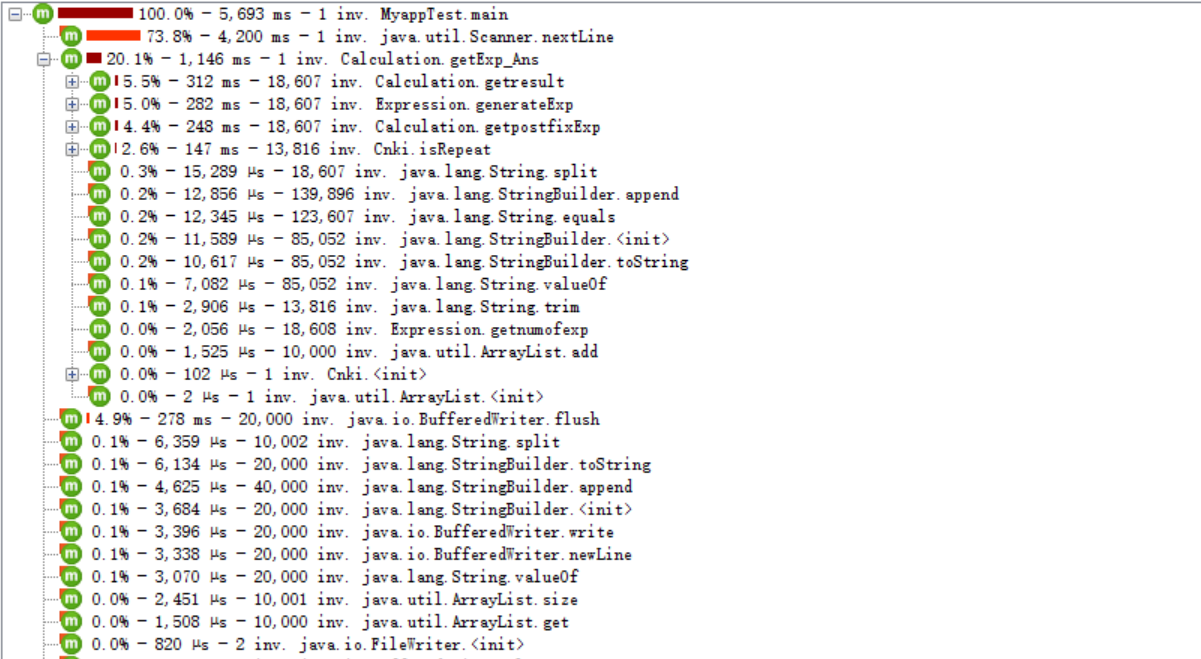
从上图可以看出我们的CPU时间消耗主要在重新生成表达式上,因为在对计算过程出现负数和除数为零以及表达式重复的情况,就重新生成新的表达式,getresult执行了18607次,比10000多了8607重新生成消耗,其中有一些是因为表达式重复(isRepeat执行了13816次)而重新生成,从分析中发现如果采用其他的方法去处理以上的出现负数,除数为零以及表达式重复的情况也许能给程序的性能得到很好的提升,由于时间关系,没有来得及对算法的性能进行优化。
四,设计实现过程:
1,思考过程
一开始是设计一个关于分数的Fraction类,实现分子分母的存储,四则运算的实现,以及分数化简,再设置一个表达式Experssion类,其中首先考虑的是处理括号的问题(一开始没有想出来好的方法),然后生成表达式,利用逆波兰算法对表达式进行计算,在有关计算的Calculation类中本来是想要处理在计算过程中是否出现负数,以及除数为0的情况,就换成先用中缀表达式转换成后缀表达式,利用后缀表达式建立二叉树,再判断,交换原来的二叉树,然后生成一个新的二叉树,中序遍历加上括号,输出正确的表达式,然后后序遍历,输出后缀表达式,再利用逆波兰算法计算结果,查重功能是利用二叉树实现,交换结点为加号或者乘号的左右子树,判断是否同构,来达到检验表达式是否重复的目的。接下来 就是将表达式和答案写进文件,最后是对给定的题目和文件判断答案的对错然后进行数量统计。但是在实践的过程中,又将之前的结构进行了修改,主要是在对括号的处理上,由于最多只有三个操作符,所以直接在表达式类中把括号所有可能的位置都列了出来,其次做的较大的修改是在处理当出现负数和除数为0的情况时的解决措施以及实现查重的方法,出现负数和除数为0时的处理是在计算表达式的过程中边计算边判断,当出现这样的情况时就直接重新生成新的表达式,查重是完全采取了新的思路,舍弃了二叉树同构的思路,创建了新的式子,定义它为查重表达式,该查重表达式能够判断表达式的计算过程是否一致,也是如果出现重复就重新生成表达式,具体实现过程在下面的方法实现中继续说明。
2,代码组织
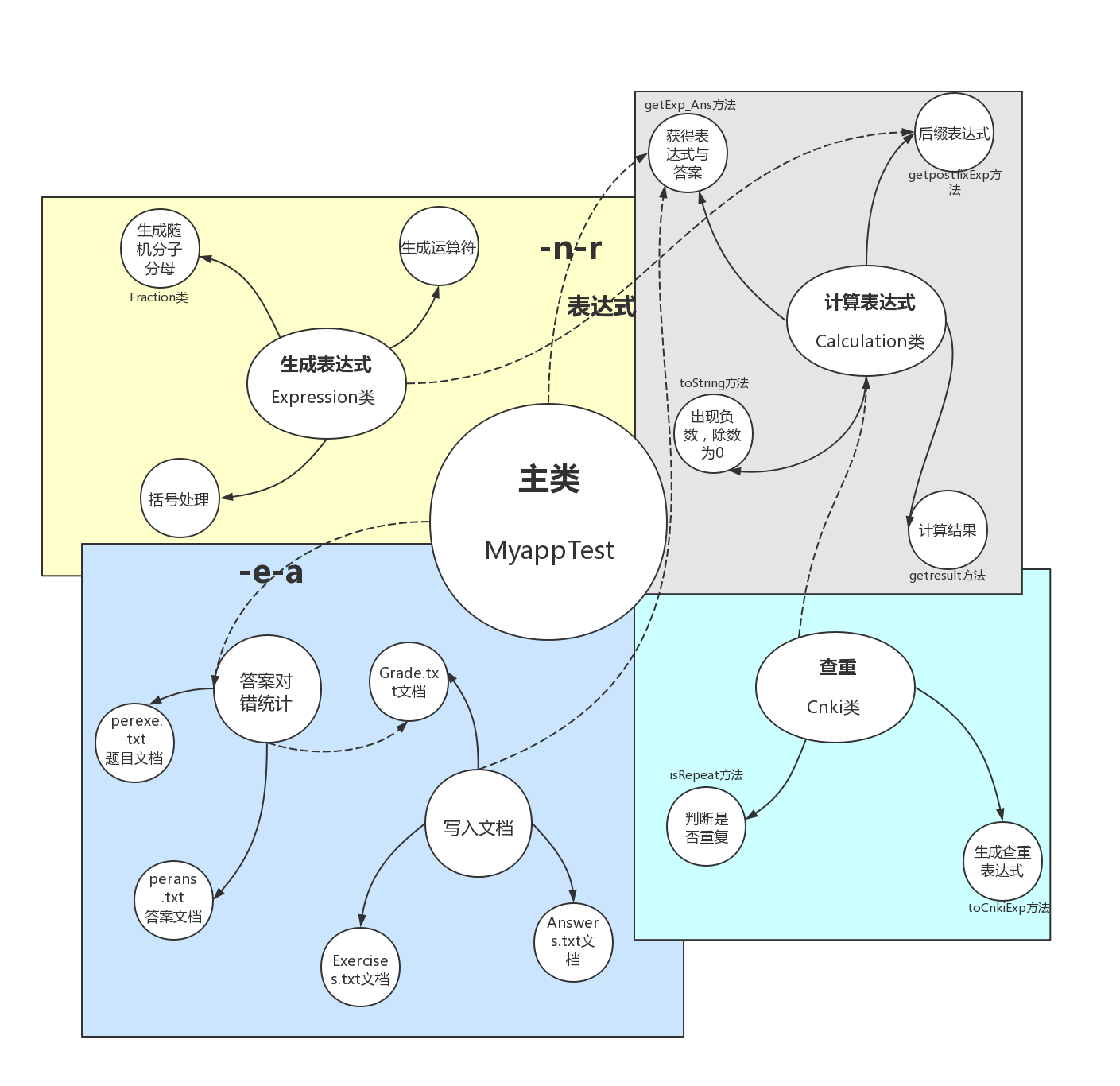
程序分有5个类,分别是实现分数的相关构造和四则运算的Fraction类,在处理括号的同时生成表达式的Expression类,实现具体计算细则(逆波兰表达式实现表达式计算,负数和除数为0的处理,通过查重Cnki类的方法判断是否表达式重复)的Caculation类,以及具体实现查重表达式的构建和表达式是否重复的判断的Cnki类,最后是实现命令行界面以及调用相关类实现整个程序功能的MyappTest类,调用关系如下图所示
3,方法实现
需求1:在Expression类中定义了默认的表达式数目(defaultnumofexp),默认值为10,如果用户重新指定了-n参数的值,则重新设置生成的表达式的数目。
需求2:在Fraction类中定义了默认的题目中数值的范围(defaultRange),默认值为10,如果用户指定了-r参数的值,则重新设置数值的范围。
需求3:我们对负数的处理是:边计算边判断,当计算过程中的中间值或者到最后一步得出的结果中出现了负值,则不再进行此次未完成的计算,就进入下一次循环,得到新的表达式替代刚刚出现负数停止运算的表达式之后再开始新一轮的表达式计算。
需求4:我们专门设计了toString方法和toFigure方法,toString方法是将表达式中的数值作为一个字符串整体对待,即在生成表达式之前,让随机得到的分子和分母先求出它们的最大公约数,化简之后根据分子分母的大小(此时的分母不能为零且分子分母不能出现负数)再转换成整数或者真分数或者带分数的形式,在对表达式中的两个数进行运算之前,用toFigure方法分别对两个数转换成单独的分子分母再进行四则运算,运算是先得到结果的分子和分母,接着用toString方法转换成真分数的字符串表示。
需求5:运算符采取随机生成的方法,即一个String数组存储加减乘除四个符号,Random的一个随机数对应着数组的一个位置,相当于生成此位置代表的运算符,由于考虑到题目中运算符的数目比较少,因此在生成表达式时对表达式中可能出现的括号的位置进行了一一列举,其中没有加括号对应三种情况,由于两操作数加括号没有意义因而我们只是考虑了三操作数的两种加括号情况和四操作数的十种加括号情况。
需求6:此需求的实现比较曲折,一开始我们是打算构建表达式二叉树,对结点是加号或者乘号的左右子树递归进行交换,如果经过交换之后的两棵二叉树是同构的,则判断表达式重复,但是考虑到每生成一个新的表达式都要和前面已经生成的表达式进行建树比较,可能会比较麻烦,因而我们果断抛弃了这个想法,参照了一篇博文的思路,形成我们最终的实现思想:根据后缀表达式转换成查重表达式,再将查重表达式转换成我们统一的标准查重表达式,接着将这些标准查重表达式扔进set容器中,让容器自己给我们判断是否重复。其中查重表达式的结构为:运算符在前,后面跟着这个运算符的操作数,而我们的标准的查重表达式为:在查重表达式结构的基础上,第一运算符如果是加号或者乘号,则将这个运算符后的两个数比较大小,根据是否需要交换位置执行操作来形成从小到大的顺序。
举个例子:
3+(2+1)和1+2+3这两个题目是重复的,因为根据它们的运算符的优先级以及结合性,均是先计算1和2的和再加上3,而这两个题目的后缀表达式分别为321++,12+3+,它们的查重表达式是+21+3和+12+3,它们的第一个运算符是加号,交换后两操作数变成标准查重表达式:+12+3,这样set容器就可以判断是否重复了,同理1+2+3和3+2+1是不重复的两道题,它们的后缀表达式是:12+3+和32+1+,查重表达式是:+12+3和+32+1,即使转换成标准的查重表达式:+12+3,+23+1它们也是不同的,所以查重表达式能直观地观察到它们是否是等价的两个表达式,按照这个思路能把重复的表达式排除掉,重新去生成新的表达式。
需求7:我们用了ArrayList来先存放生成的规范的题目和答案,然后再用Java的写文件的方法,把题目和答案从ArrayList中取出来按题号分别存放在Exercises.txt和Answers.txt中,其中存放的格式为规范的题目形式,具体请看我们的测试部分的展示以及Github上的文件。
需求8:程序支持一万道题目的生成。
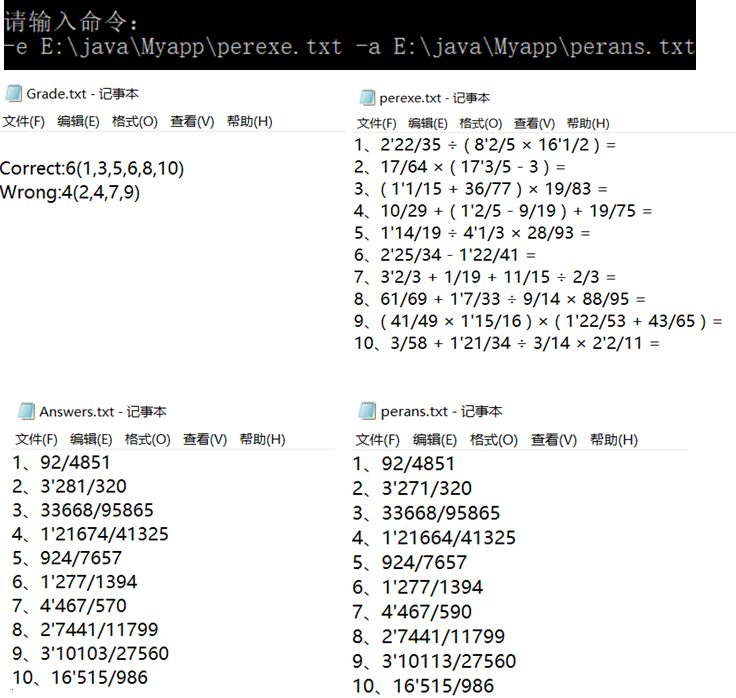
需求9:我们是用了两个txt文档(perexe.txt和perans.txt),分别存放了规范设计的10道题目和答案,为了检验程序是否能统计答案的对错数,我们把这10道题中的一部分答案设置成错误的,程序的实现为:从perexe.txt读取题目,再调用我们的计算方法,把得到的结果和perans.txt中的答案进行比对,同时计数,并将统计的结果写入Grade.txt。
五,代码说明:
1,MyappTest类是实现命令行界面的主类
import java.io.*;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MyappTest {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
System.out.println("-----------------------------------------------------");
System.out.println("小学四则运算 -功能: ");
System.out.println("Myapp.exe -n [生成题目个数] ");
System.out.println("Myapp.exe -r [题目数值范围] ");
System.out.println("Myapp.exe -e <exercisefile>.txt -a <answerfile>.txt ");
System.out.println("-----------------------------------------------------");
String [] temp;
// while(true){
System.out.println("请输入命令:");
String s = sc.nextLine();
String s2 = sc.nextLine();
String [] in = s.trim().split(" ");
String [] in2 = s2.trim().split(" ");
if(in.length==2){
BufferedWriter bw1 = new BufferedWriter(new FileWriter("G:/java/Myapp/Exercises.txt"));
BufferedWriter bw2 = new BufferedWriter(new FileWriter("G:/java/Myapp/Answers.txt"));
Expression e = new Expression();
Fraction f = new Fraction();
Calculation c = new Calculation();
ArrayList<String> list = new ArrayList<>();
int resetRange = 0;
if(in[0].equals("-n") && in2[0].equals("-r")){
e.setnumofexp(Integer.valueOf(in[1]));
resetRange = Integer.valueOf(in2[1]);
}
else if(in[0].equals("-n") ){
e.setnumofexp(Integer.valueOf(in[1]));
resetRange = f.defaultRange;
}
else if(in[0].equals("-r") ){
resetRange = Integer.valueOf(in[1]);
}
else{
System.out.println("指令输入错误,请重新输入!");
//continue;
}
list = c.getExp_Ans(e,resetRange);
for(int i=0;i<list.size();i++){
temp = list.get(i).split(":");
i++;
bw1.write(i+"、"+temp[0]);
bw1.newLine();
bw1.flush();
bw2.write(i+"、"+temp[1]);
bw2.newLine();
bw2.flush();
i--;
}
bw1.close();
bw2.close();
}
/*
* 这里是要自己写一个题目文件和题目答案,然后程序去读这个文件,
* 然后应该是要程序自己再根据读到的题目边计算边判断之前自己写的题目答案和正确答案的比较情况
* 然后把比较结果写到Grade文件中去
*/
else if(in.length==4 && in[0].equals("-e") && in[2].equals("-a")){
File fExercises = new File(in[1]);
File fAnswers = new File(in[3]);
if( fExercises.exists() && fAnswers.exists()) {
BufferedReader br1=new BufferedReader(new FileReader(fExercises));
BufferedReader br2=new BufferedReader(new FileReader(fAnswers));
Calculation c = new Calculation();
//theme为读入的题目
String theme ;
int right = 0;
int wrong = 0;
int l = 0;
int rcount[] = new int[10];
int wcount[] = new int[10];
String regex = "\\=";
Pattern r = Pattern.compile(regex);
while((theme = br1.readLine()) != null ){
String str[] = theme.split("、");
theme = str[1];
Matcher m = r.matcher(theme);
String []arr = m.replaceAll(" ").trim().split(" ");
//对每个题目进行计算, corranswer为正确答案
String corranswer = c.getresult(c.getpostfixExp(arr));
//testanswer为输入测试的答案
String[] str2=br2.readLine().split("、");
String testanswer=str2[1];
if(corranswer.equals(testanswer)){ //验证答案,统计正确和错误的个数
rcount[l] = Integer.valueOf(str2[0]);
right++;
}
else {
wcount[l] = Integer.valueOf(str2[0]);
wrong++;
}
l++;
}
br2.close();
br1.close();
File fi=new File("G:/java/Myapp/Grade.txt");
int count1 = 0;
int count2 = 0;
FileWriter fw = new FileWriter(fi, false);
PrintWriter pw = new PrintWriter(fw);
pw.println(" ");
pw.print("Correct:"+right+"(");
for (int i = 0; i < rcount.length; i++) {
if (rcount[i] != 0 && (count1 == right-1)){
pw.print(rcount[i]);
}
else if(rcount[i] != 0){
pw.print(rcount[i] + ",");
count1++;
}
}
pw.println(")");
pw.print("Wrong:"+wrong+"(");
for (int j = 0; j < wcount.length; j++) {
if (wcount[j] != 0 && (count2 == wrong-1)){
pw.print(wcount[j]);
}
else if(wcount[j] != 0){
pw.print(wcount[j] + ",");
count2++;
}
}
pw.print(")");
pw.flush();
try {
fw.flush();
pw.close();
fw.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}else
throw new FileNotFoundException("文件不存在");
}
else {
System.out.println("输入的需求模式有误,请重新输入!");
// break;
}
//}
sc.close();
}
}
2,Fraction类实现分数的相关构造和四则运算
import java.util.*;
public class Fraction {
Random random=new Random();
int numOfFraction = random.nextInt(3)+2; //随机生成的分数的个数
int defaultRange = 10;
int[] numerator = new int[numOfFraction];//分子
int[] denominator = new int[numOfFraction];//分母
//设置数值的范围
public void setRange(int a){
this.defaultRange = a;
}
public int getRange(){
return this.defaultRange;
}
public Fraction(){
for(int i=0;i<numOfFraction;i++){
int a,b;
a = random.nextInt(defaultRange);
b = random.nextInt(defaultRange-1)+1;
int c = maxcomdivisor(a,b);
numerator[i] = a/c;
denominator[i] = b/c;
}
}
/*
*
* 重新设置自然数,真分数和真分数分母数值范围,
* 其中包括调用最大公约数来化简分数并修改之前赋初值的成员变量numerator和denominator数组
*/
public void reset(int numRange){
for(int i=0;i<numOfFraction;i++){
int a,b;
a = random.nextInt(numRange);
b = random.nextInt(numRange-1)+1;
int c = maxcomdivisor(a,b);
numerator[i] = a/c;
denominator[i] = b/c;
}
}
//numerator1:分数1的分子,denomintor1:分数1的分母,numerator2:分数2的分子,denomintor2:分数2的分母。
//加
public String add(int numerator1,int denominator1,int numerator2,int denominator2 ){
int numerator = numerator1*denominator2+denominator1*numerator2;
int denominator = denominator1*denominator2;
return toString(numerator,denominator);
}
//减
public String sub(int numerator1,int denominator1,int numerator2,int denominator2 ){
int numerator = numerator1*denominator2-denominator1*numerator2;
int denominator = denominator1*denominator2;
return toString(numerator,denominator);
}
//乘
public String mul(int numerator1,int denominator1,int numerator2,int denominator2 ){
int numerator = numerator1*numerator2;
int denominator = denominator1*denominator2;
return toString(numerator,denominator);
}
//除
//当除数的分子为零时,结果的分母就为零,此情况在函数toString有相应的处理
public String dev(int numerator1,int denominator1,int numerator2,int denominator2 ){
int numerator = numerator1*denominator2;
int denominator = denominator1*numerator2;
return toString(numerator,denominator);
}
//求m和n的最大公约数
public static int maxcomdivisor(int m, int n) {
if(n==0) return -1;
else{
while (true) {
if ((m = m % n) == 0)
return n;
if ((n = n % m) == 0)
return m;
}
}
}
//将单独的一个分子和分母转换成一个字符串表示的分数
//其中分母不能为零,分子或分母不能为负
/*
* 考虑到特殊情况,如果分子为负数,并且绝对值大于分母,那么根据下面的算法,就不会转换成想得到的带分数形式,
* 如果传入的denominator为0,则根据下面的算法,就会出现除数为0的情况,
* 所以在方法体的一开始就对分子分母做了判断,保证结果的正确性,
* 同时当计算表达式结果的过程中调用此方法时就能根据返回的N判断到出现了负数和除数为0的情况,并重新生成一个表达式计算
*/
public String toString(int numerator,int denominator) {
if(denominator==0 || numerator<0 || denominator<0)
return "N";
int c = maxcomdivisor(numerator,denominator);
numerator = numerator/c;
denominator = denominator/c;
/*
* 如果分母为1,就将分子转换成字符串返回,否则判断分子和分母之间的大小,
* 当分子大于分母时,将假分数转换成真分数字符串返回,当分子小于分母时,直接以真分数的形式返回
*/
if(denominator==1) {
return String.valueOf(numerator);
}else
if(numerator>denominator) {
return String.format("%d'%d/%d", numerator/denominator,numerator%denominator,denominator);
}else {
return String.format("%d/%d", numerator,denominator);
}
}
}
3,处理括号的同时生成表达式的Expression类
import java.util.*;
public class Expression {
String[] op = new String[]{"+","-","×","÷"};
Random rand = new Random();
int defaultnumofexp = 10;
//设置数值的范围
public void setnumofexp(int a){
this.defaultnumofexp= a;
}
public int getnumofexp(){
return this.defaultnumofexp;
}
/*
* 该方法是实现生成表达式的功能,利用Fraction类的分子分母数组,
* 对应转化成分数形式,存到字符串s数组,
* 再随机生成运算符,对于括号的处理是把所有的括号可能的位置都进行了列举,
* 再和之前形成的分数与运算符一起拼接成表达式
*/
public String generateExp(int numRange){
Fraction fra = new Fraction();
fra.reset(numRange);
boolean isbrackets = rand.nextBoolean();
String [] s = new String[fra.numOfFraction];
//随机生成的分子是大于或等于零的整数,分母的大于零的整数
for(int i=0;i<fra.numOfFraction;i++)
s[i]=fra.toString(fra.numerator[i], fra.denominator[i]);
switch(fra.numOfFraction){
//两个操作数,不需要加括号
case 2:
return s[0]+" "+op[rand.nextInt(4)]+" "+s[1];
//三个操作数,有三种情况
case 3:
if(isbrackets){
switch(new Random().nextInt(2)){
case 0: //(a?b)?c
return "("+" "+s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+")"+" "+op[rand.nextInt(4)]+" "+s[2];
case 1: //a?(b?c)
return s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]+" "+")";
}
}
// a?b?c
return s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2];
//四个操作数,有七种情况
case 4:
if(isbrackets){
switch(new Random().nextInt(10)){
case 0: //(a?b)?c?d
return "("+" "+s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+")"+" "+op[rand.nextInt(4)]+" "+s[2]
+" "+op[rand.nextInt(4)]+" "+s[3];
case 1: //(a?b?c)?d
return "(" +" "+s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]+" "+")"
+" "+op[rand.nextInt(4)]+" "+s[3];
case 2: //a?(b?c)?d
return s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]+" "+")"
+" "+op[rand.nextInt(4)]+" "+s[3];
case 3: //a?(b?c?d)
return s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]
+" "+op[rand.nextInt(4)]+" "+s[3]+" "+ ")" ;
case 4: //a?b?(c?d)
return s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[2]
+" "+op[rand.nextInt(4)]+" "+s[3]+" "+")" ;
case 5: //(a?b)?(c?d)
return "("+" "+s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+")"+" "+op[rand.nextInt(4)]+" "+"("
+" "+s[2]+" "+op[rand.nextInt(4)]+" "+s[3]+" "+")" ;
case 6: //((a?b)?c)?d
return "("+" "+"("+" "+s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+")"+" "+op[rand.nextInt(4)]
+" "+s[2]+" "+")"+" "+op[rand.nextInt(4)]+" "+s[3];
case 7: //(a?(b?c))?d
return "("+" "+s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]
+" "+")"+" "+")"+" "+op[rand.nextInt(4)]+" "+s[3];
case 8: //a?((b?c)?d)
return s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]
+" "+")"+" "+op[rand.nextInt(4)]+" "+s[3]+" "+")";
case 9: //a?(b?(c?d))
return s[0]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[1]+" "+op[rand.nextInt(4)]+" "+"("+" "+s[2]
+" "+op[rand.nextInt(4)]+" "+s[3]+" "+")"+" "+")";
}
}
// a?b?c?d
return s[0]+" "+op[rand.nextInt(4)]+" "+s[1]+" "+op[rand.nextInt(4)]+" "+s[2]+" "+op[rand.nextInt(4)]+" "+s[3];
}
return generateExp(numRange);
}
}
4,实现具体计算细则的Calculation类
import java.util.*;
public class Calculation {
Fraction f = new Fraction();
Stack<String> stack = new Stack<String>();//该栈是在获得后缀表达式的过程中装运算符。
Stack<String> stack2 = new Stack<String>();//stack2是在计算表达式答案的过程中装中间计算数值和结果。
String reg = "^\\d$";//该正则表达式是在利用逆波兰表达式算法时判断读入字符串是否是单个数字字符。
//获得题目表达式和答案
public ArrayList<String> getExp_Ans(Expression e,int numRange){
ArrayList<String> alist = new ArrayList<>();//用来装符合规范的题目和对应的答案
String [] exp; //对调用Expression类生成表达式的方法生成的表达式,根据空格进行对表达式的拆分。
String postfixExp;//获得的后缀表达式字符串。
String answer;//表达式的答案。
Cnki cnki = new Cnki();//用来判断表达式是否重复的类
int count = 0;
/*
* while循环是对生成的表达式进行过滤来保证得到的表达式规范,
* 其中主要是对计算过程中出现负数和除数为0以及重复的表达式进行剔除,
* 设置了count变量,只有在表达式规范时count进行加一操作,若中途出现负数以及除数为0和重复时,count保持不变,且退出当前循环,进入下一次循环
* 直到count增加到要求生成的表达式数目,就结束循环。
*/
while(count < e.getnumofexp()){//调用Expression类中的获得默认的表达式数或者用户要求的表达式数
exp = e.generateExp(numRange).split(" ");
postfixExp = getpostfixExp(exp);
answer = getresult(postfixExp);
/*
* 此处是在计算过程(getresult方法)中当出现负数和除数为0的情况时,就返回N,
* cnki是判断表达式是否重复,当这两种情况有任何一种情况出现时就跳出当前循环,不再执行其他操作。
*/
if(answer.equals("N") || cnki.isRepeat(postfixExp.trim())){
continue;
}
else{
String exercises = "";
count++;
for(int i=0;i<exp.length;i++){
if(i < exp.length-1){
if(exp[i].equals("(") || exp[i+1].equals(")"))
exercises += exp[i];
else
exercises += exp[i] + " ";
}
else
exercises += exp[i];
}
exercises += " " + "=";
alist.add(exercises +":"+ answer);
}
}
return alist;
}
//利用逆波兰表达式算法获得后缀表达式
public String getpostfixExp(String[] exp){
String postfixExp = "";
for(String s:exp){
//s是数值,加入后缀表达式
if(s.length()>1 || s.matches(reg))
postfixExp += s + " ";
//s是 '(',入栈
else if(s.equals("("))
stack.push(s);
//s是 ')', 依次将栈中元素出栈并加入到后缀表达式, 直到遇到 '(' 并将其从栈中删除
else if(s.equals(")")){
String popstr;
do{
popstr = stack.pop();
if(!popstr.equals("("))
postfixExp += popstr + " ";
}while(!popstr.equals("("));
}else{ //s是运算符op
//栈为空 或者 栈顶元是 '(' ,op入栈
if(stack.isEmpty() || stack.get(stack.size()-1).equals("("))
stack.push(s);
else{
String top = stack.get(stack.size()-1);
//高于栈顶运算符优先级, op入栈
if(map(s) > map(top))
stack.push(s);
/*
* 依次将比op优先级高的和相等的运算符出栈加入到后缀表达式,
* 直到遇到比op优先级低的运算符或左括号(低优先级运算符或左括号不出栈)或栈空为止
* op入栈
* */
else{
String popstr = "";
do{
popstr = stack.pop();
if((map(popstr) >= map(s)) && (map(popstr)!=0))
postfixExp += popstr + " ";
}while((!stack.isEmpty()) && (map(popstr) >= map(s)));
//由于先出栈操作再判断,所以如果popstr是比op优先级低的运算符或左括号则应让它再进栈
if(map(popstr) < map(s))
stack.push(popstr);
stack.push(s);
}
}
}
}
//扫描完毕后栈中所有剩下的运算符出栈加入到后缀表达式
while(!stack.isEmpty())
postfixExp += stack.pop() + " ";
return postfixExp;
}
//计算后缀表达式的值
public String getresult(String postfixExp){
String x="",y="",result="";
String[] postfix = postfixExp.trim().split(" ");
int [] figure1,figure2;//这两个数组是将分数字符串根据‘和/进行拆分之后再进一步转换得到独立的分子分母,数组中下标为0的元素是分子,下标为1的为分母
for(String s:postfix){
//s是操作数,入栈
if(s.length()>1 || s.matches(reg))
stack2.push(s);
/*
* s是操作符op
* 连续从栈中退出两个操作数Y和X(先出栈的为Y)
* 将 X<op>Y的结果入栈
*/
else if(s.equals("+") || s.equals("-") || s.equals("×") || s.equals("÷")){
y = stack2.pop();
x = stack2.pop();
figure1 = toFigure(x);
figure2 = toFigure(y);
/*
* 调用了Fraction类的加减乘除四个方法,来计算表达式的结果,其中如果减法和除法的返回值为N就说明出现了负数或除数为0的情况。
*/
switch(s){
case "+":
result = f.add(figure1[0], figure1[1], figure2[0], figure2[1]);
break;
case "-":
result = f.sub(figure1[0], figure1[1], figure2[0], figure2[1]);
if(result.equals("N"))
return "N";
else break;
case "×":
result = f.mul(figure1[0], figure1[1], figure2[0], figure2[1]);
break;
case "÷":
result = f.dev(figure1[0], figure1[1], figure2[0], figure2[1]);
if(result.equals("N"))
return "N";
else break;
default:
System.out.println("出现未知错误!");
break;
}
stack2.push(result);
}
}
return stack2.pop();
}
/*
* map方法是用于getpostfixExp方法获得后缀表达式的过程中将左右括号和四则运算符,
* 根据它们的优先级分别映射到0,1,2
*/
public int map(String op){
if(op.equals("(") || op.equals(")"))
return 0;
else if(op.equals("+") || op.equals("-"))
return 1;
else
return 2;
}
/*
*返回一个分别存放将分数字符串根据‘和/进行拆分之后再进一步转换得到的独立分子分母数组
*/
public int[] toFigure(String fraction){
int[] figure = new int[2];
int indexOfpoint=fraction.indexOf("'");
int indexOfslash=fraction.indexOf("/");
if(indexOfpoint!=-1) {
int integer=Integer.valueOf(fraction.substring(0, indexOfpoint));
figure[1]=Integer.valueOf(fraction.substring(indexOfslash+1));
figure[0]=integer*figure[1]+Integer.valueOf(fraction.substring(indexOfpoint+1, indexOfslash));
}else if(indexOfslash!=-1) {
figure[1]=Integer.valueOf(fraction.substring(indexOfslash+1));
figure[0]=Integer.valueOf(fraction.substring(0,indexOfslash));
}else {
figure[0]=Integer.valueOf(fraction);
figure[1]=1;
}
return figure;
}
}
5,实现查重表达式的构建和表达式是否重复的判断的Cnki类
import java.util.*;
public class Cnki {
/*
* 实现查重思想:
* 判定两个表达式重复的关键在于计算这两个表达式时的过程是否一致,
* 在四则运算中也只会有加法和乘法在运算中交换左右操作数会出现重复的可能
* 在老师给出的例子中3+(2+1)和1+2+3这两个题目是重复的,
* 它们的后缀表达式分别是321++和12+3+,计算过程是一致的,都是先12相加,再和3相加,
* 为了直观的体现计算过程是否一致,我们引入了查重表达式,是后缀表达式的一种变形:运算在先,后面跟着这个运算符的操作数,
* 以上述为例3+(2+1)的查重表达式就为: +21+3
* 这个表达式的含义就是第一个运算的是加法,加法的操作数是2 和1
* 第二个运算是加法,加法的操作数是前一步计算的结果和3,
* 而1+2+3的查重表达式为:+12+3,
* 这样在做查重是只需判断查重表达式是否一致或者在查重表达式中第一个字符为‘+’ 或者‘*’的情况下
* 后续的两个操作数互换位置后是否一致即可,即上述例子可通过操作数互换位置使后一个表达式和前一个表达式的查重表达式完全一致,
* 所以可以得出尽管两个表达式的后缀表达式不同,但查重表达式一致,所以这两个表达式是重复的
* 所以在实现查重方面就是通过转换表达式的查重表达式来判断两个式子是否是重复的。
*
*/
Stack<String> numstack = new Stack<String>();//该栈是用来存放在后缀表达式转换成查重表达式的过程中后缀表达式的数值。
Set<String> set = new HashSet<String>();//set是一个存放查重表达式的容器,并且它不能添加重复的查重表达式。
Calculation c = new Calculation();
String [] postfixstr;
String regex = "^\\d$";
//给定一个表达式的后缀表达式,判断其是否和已经生成的表达式重复
public boolean isRepeat(String postfixExp){
String s = toCnkiExp(postfixExp);
if(set.add(s))
return false;
else
return true;
}
//将一个后缀表达式转换成标准的查重表达式
public String toCnkiExp(String postfixExp){
String formatpostfix = "";//用于存放查重表达式的字符串。
String x="",y ="";//x,y均是从栈中弹出的两个操作数。
int [] fraction1,fraction2;//fraction1数组是用来存放fraction1的分子和分母,fraction2数组是用来存放fraction2的分子分母
int numerator,denominator;
int flag = 0;//flag是来标记是否对一个第一操作符是'+'或者'x'的查重表达式的后两个操作数进行了交换。
postfixstr = postfixExp.trim().split(" ");
for(String s:postfixstr){
//s是操作数
if(s.length()>1 || s.matches(regex))
numstack.push(s);
else{ //s是操作符
if((s.equals("+") || s.equals("×")) && (flag==0)){
flag = 1;
y = numstack.pop();
x = numstack.pop();
fraction1 = c.toFigure(x);
fraction2 = c.toFigure(y);
numerator = fraction1[0]*fraction2[1]-fraction1[1]*fraction2[0];
denominator = fraction1[1]*fraction2[1];
/*
* 将查重表达式中的第一个操作符为'+'或者'x'的后两个操作数按照数的大小从小到大排序。
* 通过这样来处理一种特殊情况:两个表达式的后缀表达式不同,
* 并且其查重表达式不是直接相同,而是仅仅只需要再交换一次操作数位置后就能判断出这两个是重复的,其余位置的元素均相同,
* 根据查重表达式的定义,当对第一个操作符为'+'和'x'之后的两个操作数在进入set容器前就排序,
* 在对每一个后缀表达式转换成查重表达式之前,通过让原本需要交换位置才能是同一个查重表达式的两个操作数先排序,
* 就可以使set容器辨认出是重复的表达式,从而不会放到set容器中。
*/
if(numerator*denominator<0)
formatpostfix += s + x + y;
else
formatpostfix += s + y + x;
}
else{
formatpostfix += s;
if(!numstack.isEmpty())
formatpostfix += numstack.pop();
}
}
}
return formatpostfix;
}
}
六,测试运行:
1,MyApp.exe界面
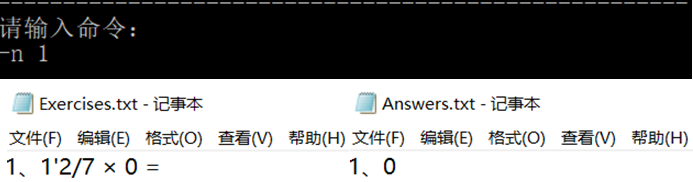
2,测试-n功能
3,测试-r功能
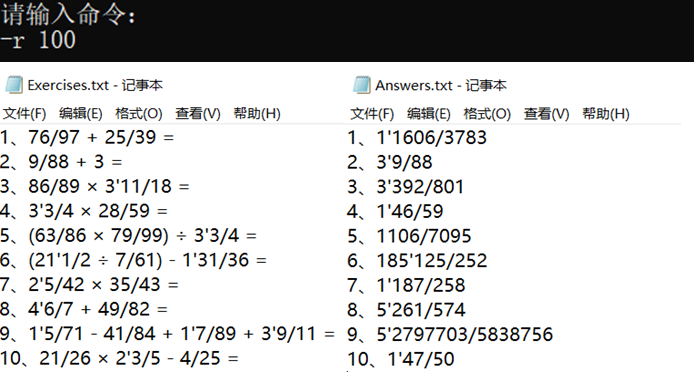
4,测试-n-r 一道题
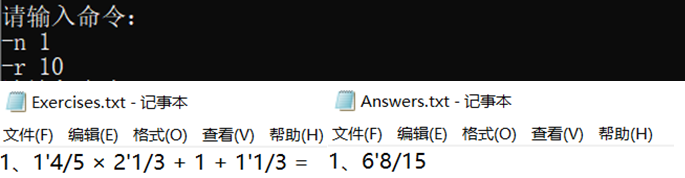
5,测试-n-r 两道题

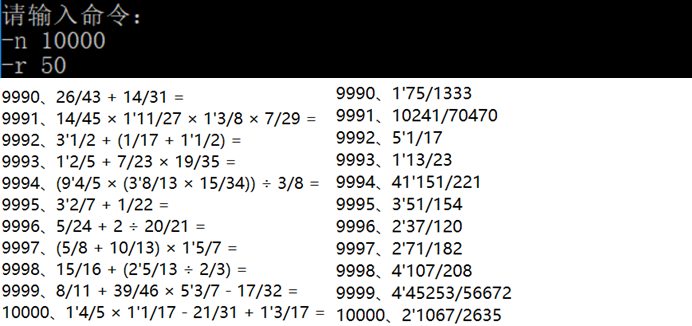
6,测试10000道
7,测试-e-a功能(误题号为2,4,7,9)
8,错误指令演示

9,验证程序正确
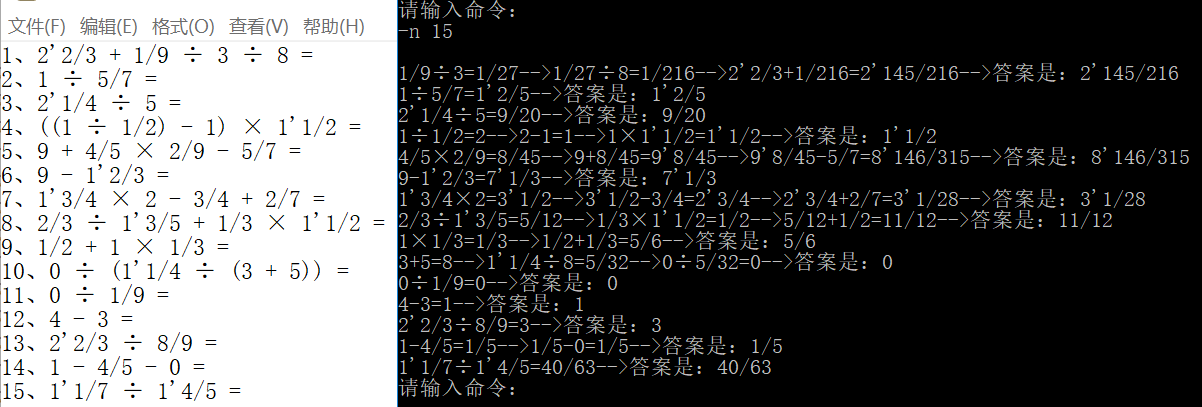
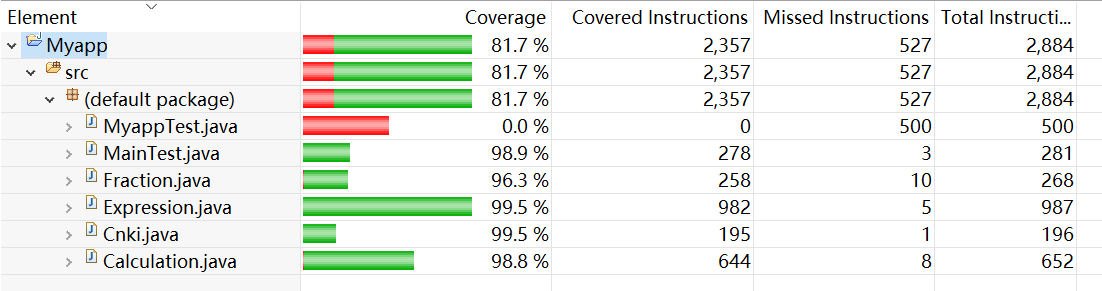
10,代码覆盖率

七,项目小结:
总结:
首先在程序的实现方面,是按照需求实现了所有的功能,其次上一次在个人项目中在思考上很少花费时间,简单考虑之后就开始写代码,之后导致了程序结构非常混乱,这一次合作在思考程序架构方面花了一定的时间,还反复进行了修改,虽然在后面测试时还是出现了不少bug,但是不得不说,在程序编写之前花费一定的时间去思考,真的会为之后的程序设计减少不少时间,同时在打代码时利用eclipse自带的代码调试功能也发现了很多细小的问题,意识到想要完成一个项目,设计之前的思考是必要的,在编码的过程中,对代码的调试也是十分重要的,掌握一定的调试能力可以在代码运行出错时不至于一个劲的来回看,而是更加有目的性的去查找问题根源,之前对调试程序功能的意识不强,之后会再加强一下调试能力,但是此次程序的优化方面完成的并不好,使用了JProfiler去对程序进行效能分析,但是如何去优化有待改善的方法还没有实现,以及关于JProfiler的更多用于分析的好的工具也还没有掌握,在分析处只是分析了cpu的占用时间的部分。虽然在后面测试时还是出现了不少bug,但是不得不说,在程序编写之前花费一定的时间去思考,真的会为之后的程序设计减少不少时间,同时在打代码时利用eclipse自带的代码调试功能也发现了很多细小的问题,意识到想要完成一个项目,设计之前的思考是必要的,在编码的过程中,对代码的调试也是十分重要的,掌握一定的调试能力可以在代码运行出错时不至于一个劲的来回看,而是更加有目的性的去查找问题根源,之前对调试程序功能的意识不强,之后会再加强一下调试能力,但是此次程序的优化方面完成的并不好,使用了JProfiler去对程序进行效能分析,但是如何去优化有待改善的方法还没有实现,以及关于JProfiler的更多用于分析的好的工具也还没有掌握,在分析处只是分析了cpu的占用时间的部分,同时在编码过程中也要注意注释的书写,在完成项目之后,在写报告时,一些变量和具体方法的实现由于没有及时添加相应的注释,都有一些忘了,所以好的编码风格以及合适的注释在编写代码的过程中也是很重要的,
结对感受:
这是我们的第一次结对项目,作为舍友在磨合方面没有太大的难度,但是面对两个人一起完成一个项目时,还是花了一定的时间去适应,之后就开始了愉快的结对项目啦,两个人一起编程最大的好处是可以从开始设置框架的时候就能够通过讨论得到对于两个人而言的最优方法,以及面对问题时可以一起讨论解决方法,同时两个人一起设计一个项目也可以让代码更加严谨,还有一点是两个人编程似乎能减少一些压力和面对程序设计时出现的问题和Debug时的焦虑感,有一个更加平稳的心态去面对出现的问题,在这样相对个人设计时更加良好的氛围下相信也会有更高效的代码,可能个人设计不需要去考虑和同伴在编码方式中的一些不同,也不需要磨合,但是过了一段时期之后,会意识到结对项目的魅力,以及在结对过程中也学习到了一些对方各自的闪光点,比如在设计或者调试时的一些小技巧或者是面对编程时的认真和不断尝试的态度,总之结对项目体验感很棒,获益匪浅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号