Greenplum详解
一、Greenplum的发展历史
Greenplum的发展可以分为下面6个阶段:
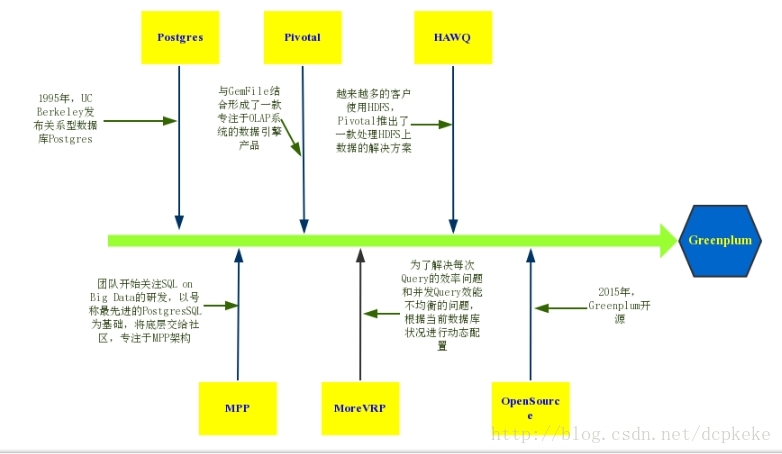
图 1 Greenplum时间线
Postgres关系型数据库。Postgres是UC Berkeley开发的关系型数据库,现已更名为PostgreSQL。PostgerSQL官网介绍自己是最先进的数据库,有强大的SQL支持能力,扩展性好,并且支持空间扩展。通过空间数据引擎PostGIS的支持可以存储和操作空间数据。
SQL queries on Big Data。Greenplum初步成型,由于数据越存越多,如何在大量数据中继续使用SQL来进行查询成了一个需要解决的问题。Greenplum开发者在X86架构和Postgres数据库的基础上,结合Postgres社区和应用生态使用MPP架构将Postgres实例组织起来,并通过MPP后端来实现存储和查询。
Pivotal商业公司。Emc2公司将Greenplum与分布式缓存GemFile一起结合形成了一款专注于OLAP系统的数据引擎产品,并以这个产品为核心组建了新的公司Pivotal。
收购MoreVRP。最初的Greenplum希望对每一次query操作都能做到尽可能的快,这样使得所有的资源都被一次query占用。然而当并发多的时候,会造成query效果变差。因此Greenplum最初将query按类型划分到了不同的队列,然后按优先级给队列分配资源,进而解决了这个问题。但是因为query是在不断变动的,这时候这种策略也需要不断调整,因此Pivotal收购了一家专注于动态配置数据库的公司MoreVRP。
发布HAWQ。由于市场上越来越多的客户将数据存放在HDFS上,基于Hadoop的Hive和Impala带给了Greenplum也受到了很大的冲击。Pivotal因此推出了一个处理HDFS上数据的解决方案HAWQ,但是HAWQ在HDFS上使用的是Greenplum专利格式来存储数据,其他的软件不能对这个格式进行操作,并不方便。
开源Greenplum。2015年,Pivotal公司拥抱了开源社区,将Greenplum开源。
二、Greenplum的几个关键词
1、shared-nothing
Shared Everthting:一般是针对单个主机,完全透明共享CPU/MEMORY/IO,并行处理能力差,典型的代表SQLServer。 shared-everything架构优点很明显,但是网络,硬盘很容易就会成为系统瓶颈。
Shared Disk:各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统。典型的代表Oracle Rac, 它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能 。
Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。Share-Nothing架构在扩展性和成本上都具有明显优势。2、MPP
大规模并行处理系统是由许多松耦合处理单元组成的,借助MPP这种高性能的系统架构,Greenplum可以将TB级的数据仓库负载分解,并使用所有的系统资源并行处理单个查询。3、MVCC
与事务型数据库系统通过锁机制来控制并发访问的机制不同, GPDB使用多版本控制(Multiversion Concurrency Control/MVCC)保证数据一致性。 这意味着在查询数据库时,每个事务看到的只是数据的快照,其确保当前的事务不会看到其他事务在相同记录上的修改。据此为数据库的每个事务提供事务隔离。
MVCC以避免给数据库事务显式锁定的方式,最大化减少锁争用以确保多用户环境下的性能。在并发控制方面,使用MVCC而不是使用锁机制的最大优势是, MVCC对查询(读)的锁与写的锁不存在冲突,并且读与写之间从不互相阻塞。三、Greenplum架构
Greenplum主要由Master节点、Segment节点、interconnect三大部分组成。Greenplum master是Greenplum数据库系统的入口,接受客户端连接及提交的SQL语句,将工作负载分发给其它数据库实例(segment实例),由它们存储和处理数据。Greenplum interconnect负责不同PostgreSQL实例之间的通信。Greenplum segment是独立的PostgreSQL数据库,每个segment存储一部分数据。大部分查询处理都由segment完成。
Master节点不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据
Segment节点负责数据的存储,可以对分布键进行优化以充分利用Segment节点的io性能来扩展整集群的io性能
存储方式可以根据数据热度或者访问模式的不同而使用不同的存储方式。一张表的不同数据可以使用不同的物理存储方式:行存储、列存储、外部表
3.1 大规模数据存储
(1)Greenplum数据库通过将数据分布到多个节点上来实现规模数据的存储。数据库的瓶颈经常发生在I/O方面,数据库的诸多性能问题最终总能归罪到I/O身上,久而久之,IO瓶颈成为了数据库性能的永恒的话题。
(2)Greenplum采用分而治之的办法,将数据规律的分布到节点上,充分利用Segment主机的IO能力,以此让系统达到最大的IO能力(主要是带宽)。
(3)在Greenplum中每个表都是分布在所有节点上的。Master节点首先通过对表的某个或多个列进行hash运算,然后根据hash结果将表的数据分布到Segment节点中。整个过程中Master节点不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
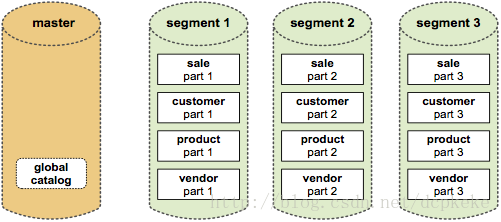
图 2 Greenplum存储结构
Greenplum提供称为“多态存储”的灵活存储方式。多态存储可以根据数据热度或者访问模式的不同而使用不同的存储方式。一张表的不同数据可以使用不同的物理存储方式。支持的存储方式包含:
行存储:行存储是传统数据库常用的存储方式,特点是访问比较快,多列更新比较容易。
列存储:列存储按列保存,不同列的数据存储在不同的地方(通常是不同文件中)。适合一次只访问宽表中某几个字段的情况。列存储的另外一个优势是压缩比高。
外部表:数据保存在其他系统中例如HDFS,数据库只保留元数据信息。
3.2 并行查询计划和执行
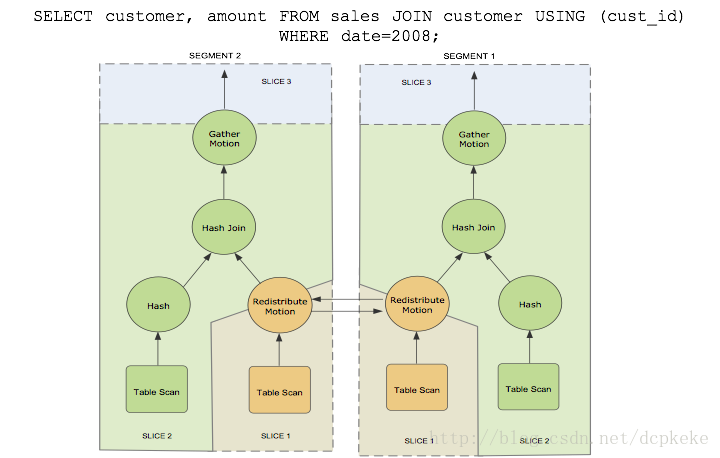
下图为一个简单SQL语句,从两张表中找到2008年的销售数据。图中右边是这个SQL的查询计划。从生成的查询计划树中看到有三种不同的颜色,颜色相同表示做同一件事情,我们称之为分片/切片(Slice)。最下层的橙色切片中有一个重分发节点,这个节点将本节点的数据重新分发到其他节点上。中间绿色切片表示分布式数据关联(HashJoin)。最上面切片负责将各个数据节点收到的数据进行汇总。
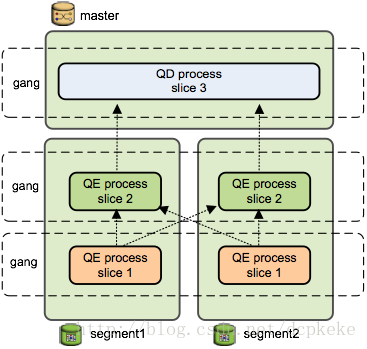
然后看看这个查询计划的执行。主节点(Master)上的调度器(QD)会下发查询任务到每个数据节点,数据节点收到任务后(查询计划树),创建工作进程(QE)执行任务。如果需要跨节点数据交换(例如上面的HashJoin),则数据节点上会创建多个工作进程协调执行任务。不同节点上执行同一任务(查询计划中的切片)的进程组成一个团伙(Gang)。数据从下往上流动,最终Master返回给客户端。
3.3 并行数据加载
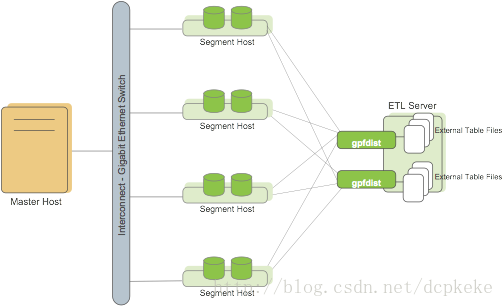
(1)并行加载技术充分利用分布式计算和分布式存储的优势,保证发挥出每一块Disk的I/O资源
(2)并行加载比串行加载,速度提高40-50倍以上,减少ETL窗口时间
(3)增加Segment和ETL Server,并行加载速度呈线性增长
四、应用生态
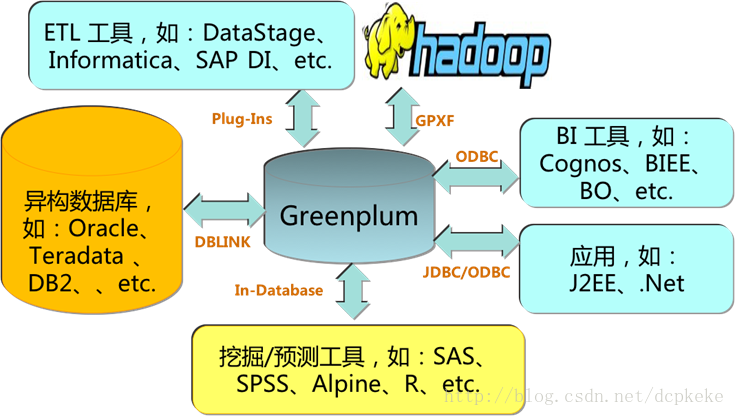
图3 Greenplum应用生态
在标准的X86平台上,Greenplum与其它异构数据库、BI工具、挖掘预测工具、ETL工具和J2EE/.NET应用程序均有良好的连通性。
利用Greenplum外部表技术,映射Hadoop集群中的HDFS、HIVE、HBASE 等多种格式数据,使用ANSI SQL访问,数据无需中间落地
Greenplum对亚马逊S3的全面读写支持
Pivotal又刚刚宣布了Greenplum数据库对微软Azure云平台的支持,用户可以在微软Azure云平台上方便地使用到Greenplum
五、Greenplum特点
借助MPP,Greenplum在大型数据集上执行复杂SQL分析的速度比很多解决方案都要快。Greenplum也带来了其它开源方案中没有的数据管理质量特性、升级和扩展能力。同时,Greenplum也降低了大规模实时数据分析的门槛,相比于 Map-Reduce,SQL语法简单,功能强大,易上手,使用和开发成本低,易于对接其他第三方数据分析工具。
标准SQL接口,比MapReduce接入更方便
完整的分布式事务能力,确保强数据一致性
近乎线性的在线扩展能力
高并发数据加载技术
高灵活的行、列以及混合存储及压缩技术
高可用技术方案
支持多方式的授权管理及审计,表级别粒度
丰富的生态系统,便捷对接hadoop等
七、常用指令:
1.取端口号:select * from gp_segment_configuration
2.select * from pg_stat_activity 该表能查看到当前数据库连接的IP 地址,用户名,提交的查询等。
3.select pg_size_pretty(pg_relation_size('schema.tablename'));查看数据库占用空间
4.select pg_size_pretty(pg_database_size('databasename));查看表占用空间
5.Vacuum analyze tablename 回收垃圾和收集统计信息
6.Select gp_segment_id,count(*) from tablename group by 1 ;查看数据分布情况
7.gp_segment_configuration实例恢复
8.8.SELECT locktype, database, c.relname, l.relation, l.transactionid, l.transaction, l.pid, l.mode, l.granted, a.current_query FROM pg_locks l, pg_class c, pg_stat_activity a WHERE l.relation=c.oid AND l.pid=a.procpid ORDER BY c.relname;
主要字段说明:
relname: 表名
locktype、mode 标识了锁的类型
九、表分布Hash分布:create table ... Distributed by(column1,column2...);同样数值的内容被分配到同一个segmment(如没有明确定义分布键,系统会把第一个字段作为分布键)
循环分布:create table ... Distributed randomly;
十、表相关:
1.创建表:CREATA TABLE 表名 DISTRIBUTED BY(表分布键); --指定分布键
CREATA TABLE 表名 DISTRIBUTED RANDOMLY --默认表的第一列作为分布键
【注:分布键设置类型不能为几何数据类型或用户自定义数据类型】
NOT NULL 列约束
UNIQUE 列约束【注:每表只能一个,被UNIQUE定义列会作为表分布键,如果表设置了主键则不允许有UNIQUE约束】
PRIMATY KEY 表约束
删除:DROPEXTERNAL [WEB] TABLE
存储模式:堆存储、只追加(AO)、行存储、列存储、压缩表(只可以是AO表)
创建堆表:CREATE TABLE 表名(a int ,b text) DISTRIBUTED BY (列名);
只追加表:CREATE TABLE 表名(a int ,b text) WITH(appendonly = true);
列存表:CREAT TABLE 表名(a int,b text) WITH(appendonly=true,orientation=列名) DISTRIBUTED BY(列名);没有指定orientation的为行存表
压缩表:CREATE TABLE 表名(a int,b text)
WITH(appendonly=true,compresstype=zilb,compresslevel=5); --创建一张5级ZLIB压缩的AO表
5.删除表
DDROP TABLE 表名;
DELETE FROM 表名; --不删除表但清空表中记录
TRUNCATE 表名 --不删除表单清空表中记录
决定因素:(1)表是否足够大?(百万级或以上条记录)、
(2)对目前性能不满意?
(3)查询条件是否能匹配分区条件?(检查查询语句的where条件是否与考虑分区的column一致)
(4)数据仓库是否需要滚动历史数据?(可按照记录日期分区)
(5)按照某个规则数据是否可被均匀分拆?
创建分区表:通过使用start、end值、every子句定义分区增量实现自动产生分区
【注:start值总是被包含而end值总是被排除】
Eg:CREATE TABLE 表名(列1,列2......) DISTRIBUTED BY(列名)
PARTITION BY RANGE(分区键)
(START(分区键值1)INCLUSIVE
END(分区键值2)EXCLUSIVE
EVERY(INTERVAL ‘增量值’));
每个分区单独指定名称:
【注:每个分区范围是连续的则不需为每个分区指定END值】
Eg:CREATE TABLE 表名(列1,列2......) DISTRIBUTED BY(列名)
PARTITION BY RANGE(分区键)
(PARTITION 分区1名 START(分区键值1)INCLUSIVE,
PARTITION 分区2名 START(分区键值2)INCLUSIVE,
PARTITION 分区3名 START(分区键值3)INCLUSIVE,
......
END(分区键值n)EXCLUSIVE);
分区表限制:主键或唯一约束必须包含表上所有分区键。而唯一索引可不包含分区键
查看分区设计:SELECT partitionboundary,partitionablename,partitionlevel,partitionrank FROM pg_partitions WHERE tablename=’表名’;
添加新分区:ALRER TABLE表名 ADD PARTITION
START() INCLUSIVE
END() EXCLUSIVE;
删除分区:ALTER TABLE 表名DROP PARTITION FOR(RANK(partitionrank))
RABK(partitiontank)指范围分区同意层级中的顺序
清空分区数据:ALTER TABLE 表名 TRUNCATE PARTITION FOR(RANK(partitionrank));
CREATE VIEW CRREATE INDEX
DROP VIEW DROP INDEX
使用索引需考虑:
1.查询工作负载:对于查询工作负载需返回大量数据的情况而言索引未必有效
2.压缩表:对于压缩数据而言,索引访问方法是解压需要的记录而不是全部解压
3.避免你在频繁更新列表上使用索引:会消耗大量写磁盘和CPU计算资源
4.创建选择性B-tree索引:选择性指数=DISTINCT值数量/表记录数,即表中重复记录越多,建立B-tree索引越有用(DISTINCT值在100到100000之间最佳,超100000之后不宜使用)
5.低选择性列上使用位图索引
6.索引列用于关联:或许可以改善join(关联)性能
7.索引列经常用在查询条件中:对大表来说,查询语句where条件中常用到的列可考虑使用索引
创建索引:
1.创建B-tree索引:CREATE INDEX 索引名 ON 表名(索引键);
2.创建位图索引:CREATE INDEX 索引名ON 表名 USING bitmap(索引键);
更新记录:UPDATE 表名 SET 赋值表达式 WHERE 查询条件;
删除记录:DELETE FROM 表名 WHERE 查询条件;
GP是通过roles来管理数据的访问控制。
Roles包含2个概念:Users和Groups。
一个role可以是一个数据库的user或group,也可以是两者兼备。
Role能拥有数据库的对象(例如:tables),并且能够把访问数据库对象权限开放给其它的role。
一个Role也可是另一个角色的成员,子role可以继承父role的权限。
每个GP数据库系统可以说是数据库roles(users和groups)的集合。
一般登入时默认使用操作系统当前用户登入。
Roles被定义成系统级别,意味着在系统中他们能访问所有的数据库。
【gpadmin用户】
在初始化数据库的时候,一般都使用gpadmin (既是操作系统用户,又是数据库的超级用户),它拥有数据库的最高权限。
gpadmin的权限太大了,一定要控制好权限,只用来做一个数据库维护工作(如:数据库升级或扩展)。
【创建Role】
语法如下:
CREATE ROLE name [ [ WITH ] option [ ... ] ]
option参数(加粗的为缺省值):
SUPERUSER | NOSUPERUSER --是否有最高权限,慎用。授权之前首先自己必须是superuser
CREATEDB | NOCREATEDB -- 是否能创建DB
| CREATEROLE | NOCREATEROLE --是否能创建role
| CREATEUSER | NOCREATEUSER --是否能创建user
| INHERIT | NOINHERIT --是否能继承
| LOGIN | NOLOGIN --是否能登入
| CONNECTION LIMIT connlimit --允许多少用户同时连接,-1表示没限制
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD ’password’--加密/设置密码,不设置默认为null,将无法登入
| VALID UNTIL ’timestamp’--密码有效期
如果ROLE已经创建的话,可以用Alter Role修改参数。
例如:修改缺省的search path
ALTER ROLE admin SET search_path TO myschema,public;
Role和User的区别:ROLE + LOGIN权限 = USER
【创建Groups】
Role也是一个Group,使用GRANT和REVOKE来增加和删除role。
例如:
=# CREATE ROLE admin CREATEROLE CREATEDB;
=# GRANT admin TO john, sally;
=# REVOKE admin FROM bob;
可以针对独立对象权限进行授权:
=# GRANT ALL ON TABLE mytable TO admin;
=# GRANT ALL ON SCHEMA myschema TO admin;
=# GRANT ALL ON DATABASE mydb TO admin;
(图:对象权限)
GP当前只支持到对象级别访问。不支持行级和列级访问。如果实在要进行访问控制的话,可以使用views。
【数据加密】
PostgreSQL提供可选数据加密解密包: pgcrypto (默认不安装)
七、更多参考资料
【1】Shared nothing architecture
【2】Greenplum vs Hive vs Impala

 浙公网安备 33010602011771号
浙公网安备 33010602011771号