ES读写操作详解
目前的Elasticsearch有两个明显的身份,一个是分布式搜索系统,另一个是分布式NoSQL数据库,对于这两种不同的身份,读写语义基本类似,但也有一点差异。

写操作
-
实时性:
- 搜索系统的Index一般都是NRT(Near Real Time),近实时的,比如Elasticsearch中,Index的实时性是由refresh控制的,默认是1s,最快可到100ms,那么也就意味着Index doc成功后,需要等待一秒钟后才可以被搜索到。
- NoSQL数据库的Write基本都是RT(Real Time),实时的,写入成功后,立即是可见的。Elasticsearch中的Index请求也能保证是实时的,因为Get请求会直接读内存中尚未Flush到存储介质的TransLog。
-
可靠性:
- 搜索系统对可靠性要求都不高,一般数据的可靠性通过将原始数据存储在另一个存储系统来保证,当搜索系统的数据发生丢失时,再从其他存储系统导一份数据过来重新rebuild就可以了。在Elasticsearch中,通过设置TransLog的Flush频率可以控制可靠性,要么是按请求,每次请求都Flush;要么是按时间,每隔一段时间Flush一次。一般为了性能考虑,会设置为每隔5秒或者1分钟Flush一次,Flush间隔时间越长,可靠性就会越低。
- NoSQL数据库作为一款数据库,必须要有很高的可靠性,数据可靠性是生命底线,决不能有闪失。如果把Elasticsearch当做NoSQL数据库,此时需要设置TransLog的Flush策略为每个请求都要Flush,这样才能保证当前Shard写入成功后,数据能尽量持久化下来。
上面简单介绍了下NoSQL数据库和搜索系统的一些异同,我们会在后面有一篇文章,专门用来介绍Elasticsearch作为NoSQL数据库时的一些局限和特点。
Lucene数据模型
Lucene中包含了四种基本数据类型,分别是:
- Index:索引,由很多的Document组成。
- Document:由很多的Field组成,是Index和Search的最小单位。
- Field:由很多的Term组成,包括Field Name和Field Value。
- Term:由很多的字节组成,可以分词。
上述四种类型在Elasticsearch中同样存在,意思也一样。
Lucene中存储的索引主要分为三种类型:
-
Invert Index:倒排索引,或者简称Index,通过Term可以查询到拥有该Term的文档。可以配置为是否分词,如果分词可以配置不同的分词器。索引存储的时候有多种存储类型,分别是:
- DOCS:只存储DocID。
- DOCS_AND_FREQS:存储DocID和词频(Term Freq)。
- DOCS_AND_FREQS_AND_POSITIONS:存储DocID、词频(Term Freq)和位置。
- DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:存储DocID、词频(Term Freq)、位置和偏移。
- DocValues:正排索引,采用列式存储。通过DocID可以快速读取到该Doc的特定字段的值。由于是列式存储,性能会比较好。一般用于sort,agg等需要高频读取Doc字段值的场景。
- Store:字段原始内容存储,同一篇文章的多个Field的Store会存储在一起,适用于一次读取少量且多个字段内存的场景,比如摘要等。
Lucene中提供索引和搜索的最小组织形式是Segment,Segment中按照索引类型不同,分成了Invert Index,Doc Values和Store这三大类(还有一些辅助类,这里省略),每一类里面都是按照Doc为最小单位存储。Invert Index中存储的Key是Term,Value是Doc ID的链表;Doc Value中Key 是Doc ID和Field Name,Value是Field Value;Store的Key是Doc ID,Value是Filed Name和Filed Value。
由于Lucene中没有主键概念和更新逻辑,所有对Lucene的更新都是Append一个新Doc,类似于一个只能Append的队列,所有Doc都被同等对等,同样的处理方式。其中的Doc由众多Field组成,没有特殊Field,每个Field也都被同等对待,同样的处理方式。
从上面介绍来看,Lucene只是提供了一个索引和查询的最基本的功能,距离一个完全可用的完整搜索引擎还有一些距离:
Lucene的不足
- Lucene是一个单机的搜索库,如何能以分布式形式支持海量数据?
Lucene中没有更新,每次都是Append一个新文档,如何做部分字段的更新? - Lucene中没有主键索引,如何处理同一个Doc的多次写入?
- 在稀疏列数据中,如何判断某些文档是否存在特定字段?
- Lucene中生成完整Segment后,该Segment就不能再被更改,此时该Segment才能被搜索,这种情况下,如何做实时搜索?
上述几个问题,对于搜索而言都是至关重要的功能诉求,我们接下来看看Elasticsearch中是如何来解这些问题的。
Elasticsearch怎么做
在Elasticsearch中,为了支持分布式,增加了一个系统字段_routing(路由),通过_routing将Doc分发到不同的Shard,不同的Shard可以位于不同的机器上,这样就能实现简单的分布式了。
采用类似的方式,Elasticsearch增加了_id、_version、_source和_seq_no等等多个系统字段,通过这些Elasticsearch中特有的系统字段可以有效解决上述的几个问题,新增的系统字段主要是下列几个:
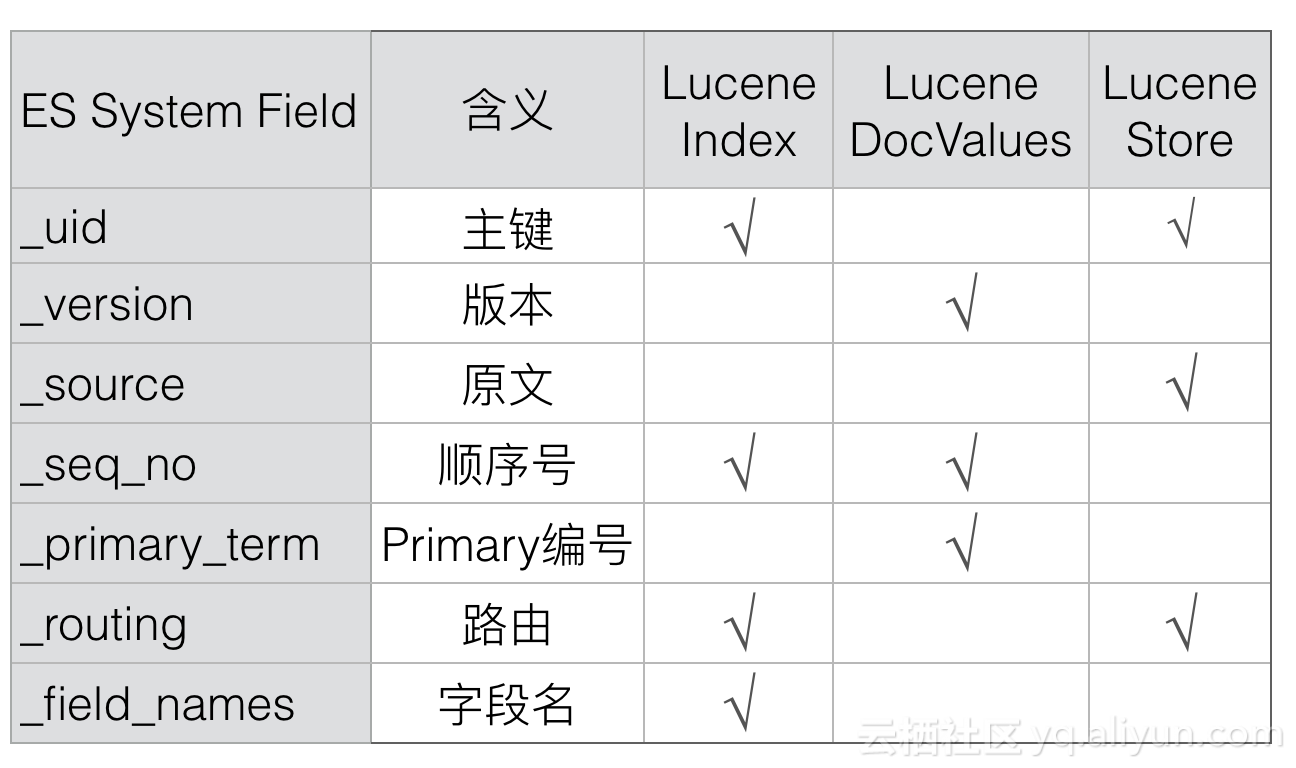
下面我们逐个字段的剖析下上述系统字段的作用,先来看第一个_id字段:
1. _id
Doc的主键,在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
Lucene中没有主键索引,要保证系统中同一个Doc不会重复,Elasticsearch引入了_id字段来实现主键。每次写入的时候都会先查询id,如果有,则说明已经有相同Doc存在了。
通过_id值(ES内部转换成_uid)可以唯一在Elasticsearch中确定一个Doc。
Elasticsearch中,_id只是一个用户级别的虚拟字段,在Elasticsearch中并不会映射到Lucene中,所以也就不会存储该字段的值。
_id的值可以由_uid解析而来(_uid =type + '#' + id),Elasticsearch中会存储_uid。
2. _uid
_uid的格式是:type + '#' + id。
_uid会存储在Lucene中,在Lucene中的映射关系如下:dex下可能存在多个id值相同的Doc,而6.0.0之后只支持单Type,同Index下id值是唯一的。
uid会存储在Lucene中,在Lucene中的映射关系如下:
_uid 只是存储了倒排Index和原文store:倒排Index的目的是可以通过_id快速查询到文档;原文store用来在返回的Response里面填充完整的_id值。
在Lucene中存储_uid,而不是_id的原因是,在6.0.0之前版本里面,_uid可以比_id表示更多的信息,比如Type。在6.0.0版本之后,同一个Index只能有一个Type,这时候Type就没多大意义了,后面Type应该会消失,那时候_id就会和_uid概念一样,到时候两者会合二为一,也能简化大家的理解。
3. _version
Elasticsearch中每个Doc都会有一个Version,该Version可以由用户指定,也可以由系统自动生成。如果是系统自动生成,那么每次Version都是递增1。
_version是实时的,不受搜索的近实时性影响,原因是可以通过_uid从内存中versionMap或者TransLog中读取到。
Version在Lucene中也是映射为一个特殊的Field存在。
Elasticsearch中Version字段的主要目的是通过doc_id读取Version,所以Version只要存储为DocValues就可以了,类似于KeyValue存储。
Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失:
- 首次写入Doc的时候,会为Doc分配一个初始的Version:V0,该值根据VersionType不同而不同。
- 再次写入Doc的时候,如果Request中没有指定Version,则会先加锁,然后去读取该Doc的最大版本V1,然后将V1+1后的新版本写入Lucene中。
- 再次写入Doc的时候,如果Request中指定了Version:V1,则继续会先加锁,然后去读该Doc的最大版本V2,判断V1==V2,如果不相等,则发生版本冲突。否则版本吻合,继续写入Lucene。
- 当做部分更新的时候,会先通过GetRequest读取当前id的完整Doc和V1,接着和当前Request中的Doc合并为一个完整Doc。然后执行一些逻辑后,加锁,再次读取该Doc的最大版本号V2,判断V1==V2,如果不相等,则在刚才执行其他逻辑时被其他线程更改了当前文档,需要报错后重试。如果相等,则期间没有其他线程修改当前文档,继续写入Lucene中。这个过程就是一个典型的read-then-update事务。
4. _source
Elasticsearch中有一个重要的概念是source,存储原始文档,也可以通过过滤设置只存储特定Field。
Source在Lucene中也是映射为了一个特殊的Field存在:
Elasticsearch中_source字段的主要目的是通过doc_id读取该文档的原始内容,所以只需要存储Store即可。
_source其实是名为_source的虚拟Store Field。
Elasticsearch中使用_source字段可以实现以下功能:
- Update:部分更新时,需要从读取文档保存在_source字段中的原文,然后和请求中的部分字段合并为一个完整文档。如果没有_source,则不能完成部分字段的Update操作。
- Rebuild:最新的版本中新增了rebuild接口,可以通过Rebuild API完成索引重建,过程中不需要从其他系统导入全量数据,而是从当前文档的_source中读取。如果没有_source,则不能使用Rebuild API。
- Script:不管是Index还是Search的Script,都可能用到存储在Store中的原始内容,如果禁用了_source,则这部分功能不再可用。
- Summary:摘要信息也是来源于_source字段。
5. _seq_no
严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no。
_seq_no在Primary Node中由SequenceNumbersService生成,但其实真正产生这个值的是LocalCheckpointTracker,每次递增1:
/**
* The next available sequence number.
*/
private volatile long nextSeqNo;
/**
* Issue the next sequence number.
*
* @return the next assigned sequence number
*/
synchronized long generateSeqNo() {
return nextSeqNo++;
}每个文档在使用Lucene的document操作接口之前,会获取到一个_seq_no,这个_seq_no会以系统保留Field的名义存储到Lucene中,文档写入Lucene成功后,会标记该seq_no为完成状态,这时候会使用当前seq_no更新local_checkpoint。
checkpoint分为local_checkpoint和global_checkpoint,主要是用于保证有序性,以及减少Shard恢复时数据拷贝的数据拷贝量,更详细的介绍可以看这篇文章:Sequence IDs: Coming Soon to an Elasticsearch Cluster Near You。
_seq_no在Lucene中的映射:
Elasticsearch中_seq_no的作用有两个,一是通过doc_id查询到该文档的seq_no,二是通过seq_no范围查找相关文档,所以也就需要存储为Index和DocValues(或者Store)。由于是在冲突检测时才需要读取文档的_seq_no,而且此时只需要读取_seq_no,不需要其他字段,这时候存储为列式存储的DocValues比Store在性能上更好一些。
_seq_no是严格递增的,写入Lucene的顺序也是递增的,所以DocValues存储类型可以设置为Sorted。
另外,_seq_no的索引应该仅需要支持存储DocId就可以了,不需要FREQS、POSITIONS和分词。如果多存储了这些,对功能也没影响,就是多占了一点资源而已。
6. _primary_term
_primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
_primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。
Elasticsearch中_primary_term只需要通过doc_id读取到即可,所以只需要保存为DocValues就可以了.
7. _routing
路由规则,写入和查询的routing需要一致,否则会出现写入的文档没法被查到情况。
在mapping中,或者Request中可以指定按某个字段路由。默认是按照_Id值路由。
_routing在Lucene中映射为:
Elasticsearch中文档级别的_routing主要有两个目的,一是可以查询到使用某种_routing的文档有哪些,当发生_routing变化时,可以对历史_routing的文档重新读取再Index,这个需要倒排Index。另一个是查询到文档后,在Response里面展示该文档使用的_routing规则,这里需要存储为Store。
8. _field_names
该字段会索引某个Field的名称,用来判断某个Doc中是否存在某个Field,用于exists或者missing请求。
_field_names在Lucene中的映射:

Elasticsearch中_field_names的目的是查询哪些Doc的这个Field是否存在,所以只需要倒排Index即可。
读操作
下一篇《Elasticsearch 查询流程简介》中再详细介绍。
上面大概对比了下搜索和NoSQL在写方面的特点,接下来,我们看一下Elasticsearch 6.0.0版本中写入流程都做了哪些事情,希望能对大家有用。
写操作的关键点
在考虑或分析一个分布式系统的写操作时,一般需要从下面几个方面考虑:
- 可靠性:或者是持久性,数据写入系统成功后,数据不会被回滚或丢失。
- 一致性:数据写入成功后,再次查询时必须能保证读取到最新版本的数据,不能读取到旧数据。
- 原子性:一个写入或者更新操作,要么完全成功,要么完全失败,不允许出现中间状态。
- 隔离性:多个写入操作相互不影响。
- 实时性:写入后是否可以立即被查询到。
- 性能:写入性能,吞吐量到底怎么样。
Elasticsearch作为分布式系统,也需要在写入的时候满足上述的四个特点,我们在后面的写流程介绍中会涉及到上述四个方面。
接下来,我们一层一层剖析Elasticsearch内部的写机制。
Lucene的写
众所周知,Elasticsearch内部使用了Lucene完成索引创建和搜索功能,Lucene中写操作主要是通过IndexWriter类实现,IndexWriter提供三个接口:
public long addDocument();
public long updateDocuments();
public long deleteDocuments();通过这三个接口可以完成单个文档的写入,更新和删除功能,包括了分词,倒排创建,正排创建等等所有搜索相关的流程。只要Doc通过IndesWriter写入后,后面就可以通过IndexSearcher搜索了,看起来功能已经完善了,但是仍然有一些问题没有解:
上述操作是单机的,而不是我们需要的分布式。
- 文档写入Lucene后并不是立即可查询的,需要生成完整的Segment后才可被搜索,如何保证实时性?
- Lucene生成的Segment是在内存中,如果机器宕机或掉电后,内存中的Segment会丢失,如何保证数据可靠性 ?
- Lucene不支持部分文档更新,但是这又是一个强需求,如何支持部分更新?
- 上述问题,在Lucene中是没有解决的,那么就需要Elasticsearch中解决上述问题。
Elasticsearch在解决上述问题时,除了我们在上一篇《Elasticsearch数据模型简介》中介绍的几种系统字段外,在引擎架构上也引入了多重机制来解决问题。我们再来看Elasticsearch中的写机制。
Elasticsearch的写
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。
此外,Elasticsearch整体架构上采用了一主多副的方式: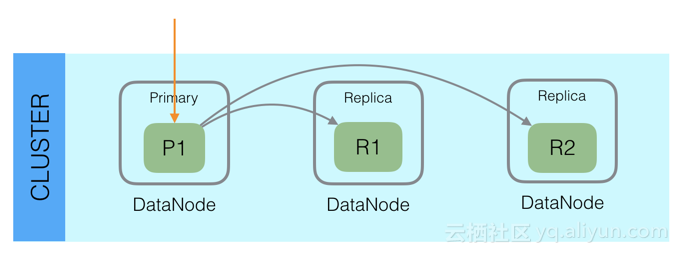
每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),最后从集群的Meta中找出出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
这种模式下,写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。只要有副本在,写入延时最小也是两次单Shard的写入时延总和,写入效率会较低,但是这样的好处也很明显,避免写入后,单机或磁盘故障导致数据丢失,在数据重要性和性能方面,一般都是优先选择数据,除非一些允许丢数据的特殊场景。
采用多个副本后,避免了单机或磁盘故障发生时,对已经持久化后的数据造成损害,但是Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?
对于这种问题,Elasticsearch学习了数据库中的处理方式:增加CommitLog模块,Elasticsearch中叫TransLog。
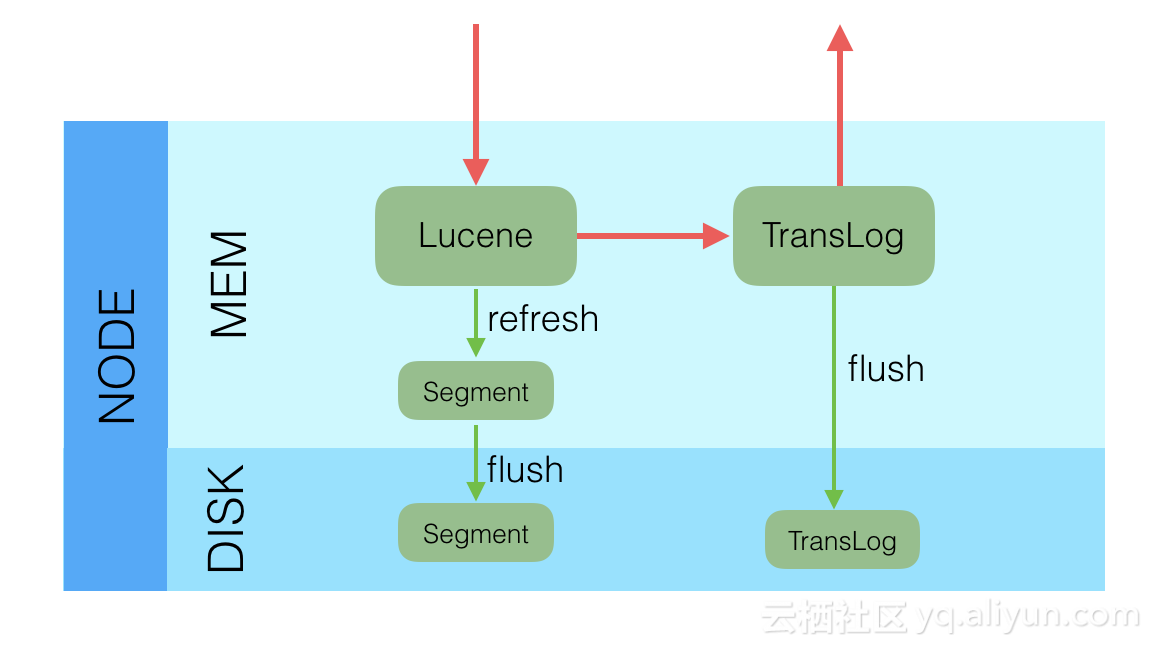
在每一个Shard中,写入流程分为两部分,先写入Lucene,再写入TransLog。
写入请求到达Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户。这里有几个关键点,一是和数据库不同,数据库是先写CommitLog,然后再写内存,而Elasticsearch是先写内存,最后才写TransLog,一种可能的原因是Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,减少recover的复杂度和提高速度,所以就把写Lucene放在了最前面。二是写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统。三是当Elasticsearch作为NoSQL数据库时,查询方式是GetById,这种查询可以直接从TransLog中查询,这时候就成了RT(Real Time)实时系统。四是每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,刷新后索引文件已经持久化了,历史的TransLog就没用了,会清空掉旧的TransLog。
上面介绍了Elasticsearch在写入时的两个关键模块,Replica和TransLog,接下来,我们看一下Update流程: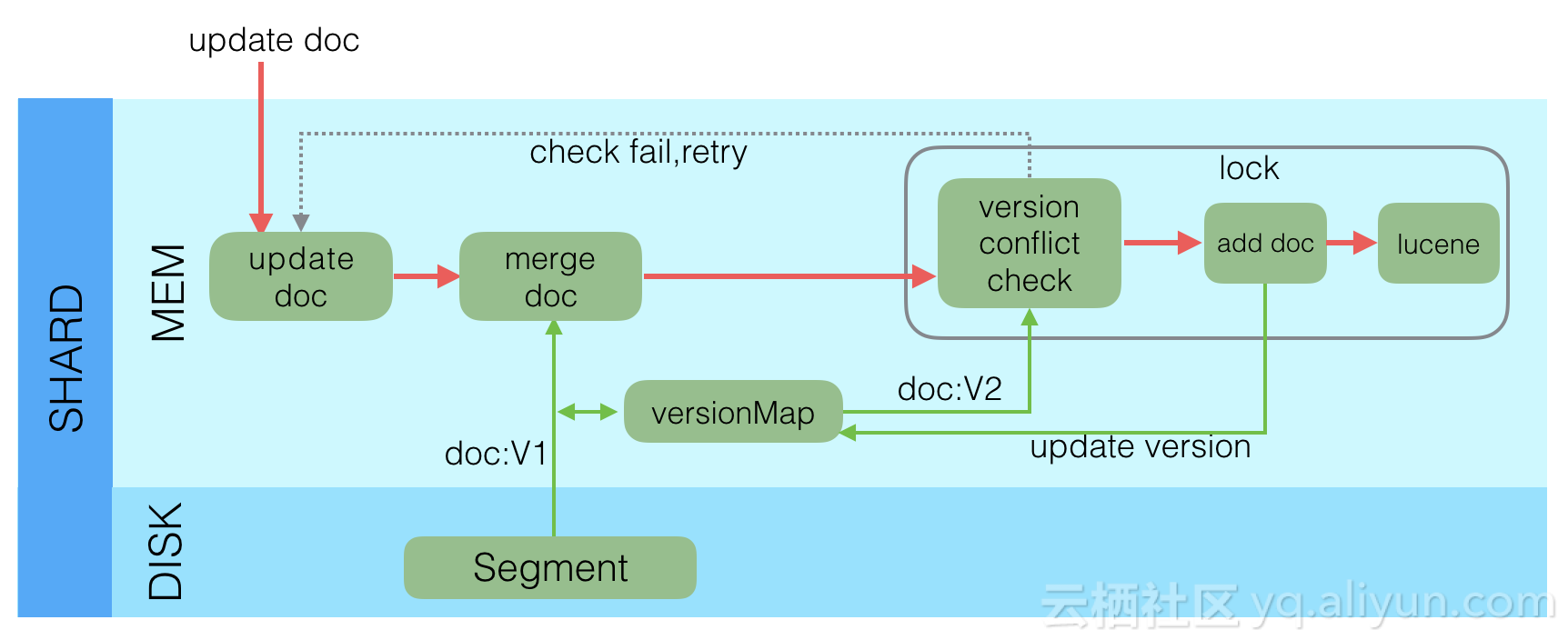
Lucene中不支持部分字段的Update,所以需要在Elasticsearch中实现该功能,具体流程如下:
- 收到Update请求后,从Segment或者TransLog中读取同id的完整Doc,记录版本号为V1。
- 将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc,同时更新内存中的VersionMap。获取到完整Doc后,Update请求就变成了Index请求。
- 加锁。
- 再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取,这里基本都会从versionMap中获取到。
- 检查版本是否冲突(V1==V2),如果冲突,则回退到开始的“Update doc”阶段,重新执行。如果不冲突,则执行最新的Add请求。
- 在Index Doc阶段,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
- 释放锁,部分更新的流程就结束了。
介绍完部分更新的流程后,大家应该从整体架构上对Elasticsearch的写入有了一个初步的映象,接下来我们详细剖析下写入的详细步骤。
Elasticsearch写入请求类型
Elasticsearch中的写入请求类型,主要包括下列几个:Index(Create),Update,Delete和Bulk,其中前3个是单文档操作,后一个Bulk是多文档操作,其中Bulk中可以包括Index(Create),Update和Delete。
在6.0.0及其之后的版本中,前3个单文档操作的实现基本都和Bulk操作一致,甚至有些就是通过调用Bulk的接口实现的。估计接下来几个版本后,Index(Create),Update,Delete都会被当做Bulk的一种特例化操作被处理。这样,代码和逻辑都会更清晰一些。
下面,我们就以Bulk请求为例来介绍写入流程。
Elasticsearch写入流程图
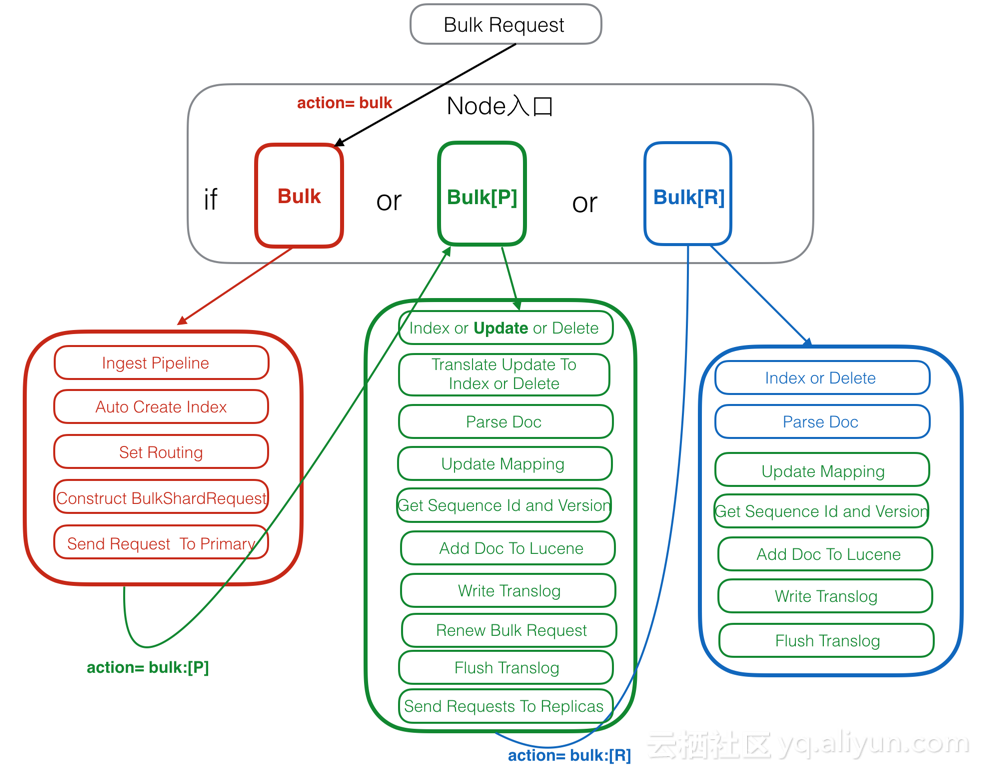
- 红色:Client Node。
- 绿色:Primary Node。
- 蓝色:Replica Node。
注册Action
在Elasticsearch中,所有action的入口处理方法都是注册在ActionModule.java中,比如Bulk Request有两个注册入口,分别是Rest和Transport入口:

如果请求是Rest请求,则会在RestBulkAction中Parse Request,构造出BulkRequest,然后发给后面的TransportAction处理。
TransportShardBulkAction的基类TransportReplicationAction中注册了对Primary,Replica等的不同处理入口: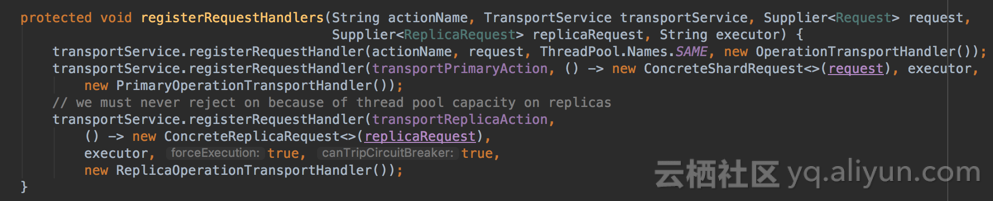
这里对原始请求,Primary Node请求和Replica Node请求各自注册了一个handler处理入口。
Client Node
Client Node 也包括了前面说过的Parse Request,这里就不再赘述了,接下来看一下其他的部分。
1. Ingest Pipeline
在这一步可以对原始文档做一些处理,比如HTML解析,自定义的处理,具体处理逻辑可以通过插件来实现。在Elasticsearch中,由于Ingest Pipeline会比较耗费CPU等资源,可以设置专门的Ingest Node,专门用来处理Ingest Pipeline逻辑。
如果当前Node不能执行Ingest Pipeline,则会将请求发给另一台可以执行Ingest Pipeline的Node。
2. Auto Create Index
判断当前Index是否存在,如果不存在,则需要自动创建Index,这里需要和Master交互。也可以通过配置关闭自动创建Index的功能。
3. Set Routing
设置路由条件,如果Request中指定了路由条件,则直接使用Request中的Routing,否则使用Mapping中配置的,如果Mapping中无配置,则使用默认的_id字段值。
在这一步中,如果没有指定id字段,则会自动生成一个唯一的_id字段,目前使用的是UUID。
4. Construct BulkShardRequest
由于Bulk Request中会包括多个(Index/Update/Delete)请求,这些请求根据routing可能会落在多个Shard上执行,这一步会按Shard挑拣Single Write Request,同一个Shard中的请求聚集在一起,构建BulkShardRequest,每个BulkShardRequest对应一个Shard。
5. Send Request To Primary
这一步会将每一个BulkShardRequest请求发送给相应Shard的Primary Node。
Primary Node
Primary 请求的入口是在PrimaryOperationTransportHandler的messageReceived,我们来看一下相关的逻辑流程。
1. Index or Update or Delete
循环执行每个Single Write Request,对于每个Request,根据操作类型(CREATE/INDEX/UPDATE/DELETE)选择不同的处理逻辑。
其中,Create/Index是直接新增Doc,Delete是直接根据_id删除Doc,Update会稍微复杂些,我们下面就以Update为例来介绍。
2. Translate Update To Index or Delete
这一步是Update操作的特有步骤,在这里,会将Update请求转换为Index或者Delete请求。首先,会通过GetRequest查询到已经存在的同_id Doc(如果有)的完整字段和值(依赖_source字段),然后和请求中的Doc合并。同时,这里会获取到读到的Doc版本号,记做V1。
3. Parse Doc
这里会解析Doc中各个字段。生成ParsedDocument对象,同时会生成uid Term。在Elasticsearch中,_uid = type # _id,对用户,_Id可见,而Elasticsearch中存储的是_uid。这一部分生成的ParsedDocument中也有Elasticsearch的系统字段,大部分会根据当前内容填充,部分未知的会在后面继续填充ParsedDocument。
4. Update Mapping
Elasticsearch中有个自动更新Mapping的功能,就在这一步生效。会先挑选出Mapping中未包含的新Field,然后判断是否运行自动更新Mapping,如果允许,则更新Mapping。
5. Get Sequence Id and Version
由于当前是Primary Shard,则会从SequenceNumber Service获取一个sequenceID和Version。SequenceID在Shard级别每次递增1,SequenceID在写入Doc成功后,会用来初始化LocalCheckpoint。Version则是根据当前Doc的最大Version递增1。
6. Add Doc To Lucene
这一步开始的时候会给特定_uid加锁,然后判断该_uid对应的Version是否等于之前Translate Update To Index步骤里获取到的Version,如果不相等,则说明刚才读取Doc后,该Doc发生了变化,出现了版本冲突,这时候会抛出一个VersionConflict的异常,该异常会在Primary Node最开始处捕获,重新从“Translate Update To Index or Delete”开始执行。
如果Version相等,则继续执行,如果已经存在同id的Doc,则会调用Lucene的UpdateDocument(uid, doc)接口,先根据uid删除Doc,然后再Index新Doc。如果是首次写入,则直接调用Lucene的AddDocument接口完成Doc的Index,AddDocument也是通过UpdateDocument实现。
这一步中有个问题是,如何保证Delete-Then-Add的原子性,怎么避免中间状态时被Refresh?答案是在开始Delete之前,会加一个Refresh Lock,禁止被Refresh,只有等Add完后释放了Refresh Lock后才能被Refresh,这样就保证了Delete-Then-Add的原子性。
Lucene的UpdateDocument接口中就只是处理多个Field,会遍历每个Field逐个处理,处理顺序是invert index,store field,doc values,point dimension,后续会有文章专门介绍Lucene中的写入。
7. Write Translog
写完Lucene的Segment后,会以keyvalue的形式写TransLog,Key是_id,Value是Doc内容。当查询的时候,如果请求是GetDocByID,则可以直接根据_id从TransLog中读取到,满足NoSQL场景下的实时性要去。
需要注意的是,这里只是写入到内存的TransLog,是否Sync到磁盘的逻辑还在后面。
这一步的最后,会标记当前SequenceID已经成功执行,接着会更新当前Shard的LocalCheckPoint。
8. Renew Bulk Request
这里会重新构造Bulk Request,原因是前面已经将UpdateRequest翻译成了Index或Delete请求,则后续所有Replica中只需要执行Index或Delete请求就可以了,不需要再执行Update逻辑,一是保证Replica中逻辑更简单,性能更好,二是保证同一个请求在Primary和Replica中的执行结果一样。
9. Flush Translog
这里会根据TransLog的策略,选择不同的执行方式,要么是立即Flush到磁盘,要么是等到以后再Flush。Flush的频率越高,可靠性越高,对写入性能影响越大。
10. Send Requests To Replicas
这里会将刚才构造的新的Bulk Request并行发送给多个Replica,然后等待Replica的返回,这里需要等待多个Replica成功返回后,Primary Node才会返回用户,具体需要多少Replica Node返回,可以通过配置或者请求参数设置。
这里,同时会将SequenceID,PrimaryTerm,GlobalCheckPoint等传递给Replica。
发送给Replica的请求中,Action Name等于原始ActionName + [R],这里的R表示Replica。通过这个[R]的不同,可以找到处理Replica请求的Handler。
11. Receive Response From Replicas
Replica中请求都处理完后,且满足最小Replica返回数后,会更新Primary Node的LocalCheckPoint。
Replica Node
Replica 请求的入口是在ReplicaOperationTransportHandler的messageReceived,我们来看一下相关的逻辑流程。
1. Index or Delete
根据请求类型是Index还是Delete,选择不同的执行逻辑。这里没有Update,是因为在Primary Node中已经将Update转换成了Index或Delete请求了。
2. Parse Doc
3. Update Mapping
以上都和Primary Node中逻辑一致
4. Get Sequence Id and Version
Primary Node中会生成Sequence ID和Version,然后放入ReplicaRequest中,这里只需要从Request中获取到就行。
5. Add Doc To Lucene
由于已经在Primary Node中将部分Update请求转换成了Index或Delete请求,这里只需要处理Index和Delete两种请求,不再需要处理Update请求了。比Primary Node会更简单一些。
6. Write Translog
7. Flush Translog
以上都和Primary Node中逻辑一致。
最后
上面详细介绍了Elasticsearch的写入流程及其各个流程的工作机制,我们在这里再次总结下之前提出的分布式系统中的六大特性:
====================================================================================
- 可靠性:由于Lucene的设计中不考虑可靠性,在Elasticsearch中通过Replica和TransLog两套机制保证数据的可靠性。
- 一致性:Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但是Add完成后仍然有可能立即发生Flush,导致Segment可读。这样就没法保证Primary和所有其他Replica可以同一时间Flush,就会出现查询不稳定的情况,这里只能实现最终一致性。
- 原子性:Add和Delete都是直接调用Lucene的接口,是原子的。当部分更新时,使用Version和锁保证更新是原子的。
- 隔离性:仍然采用Version和局部锁来保证更新的是特定版本的数据。
- 实时性:使用定期Refresh Segment到内存,并且Reopen Segment方式保证搜索可以在较短时间(比如1秒)内被搜索到。通过将未刷新到磁盘数据记入TransLog,保证对未提交数据可以通过ID实时访问到。
- 性能:性能是一个系统性工程,所有环节都要考虑对性能的影响,在Elasticsearch中,在很多地方的设计都考虑到了性能,一是不需要所有Replica都返回后才能返回给用户,只需要返回特定数目的就行;二是生成的Segment现在内存中提供服务,等一段时间后才刷新到磁盘,Segment在内存这段时间的可靠性由TransLog保证;三是TransLog可以配置为周期性的Flush,但这个会给可靠性带来伤害;四是每个线程持有一个Segment,多线程时相互不影响,相互独立,性能更好;五是系统的写入流程对版本依赖较重,读取频率较高,因此采用了versionMap,减少热点数据的多次磁盘IO开销。Lucene中针对性能做了大量的优化。后面我们也会有文章专门介绍Lucene中的优化思路。
读操作
对于搜索而言是近实时的,延迟在100ms以上,对于NoSQL则需要是实时的。
一致性指的是写入成功后,那么下次读一定要能读取到最新的数据。对于搜索,这个要求会低一些,可以有一些延迟。但是对于NoSQL数据库,则一般要求最好是强一致性的。
结果匹配上,NoSQL作为数据库,查询过程中只有符合不符合两种情况,而搜索里面还有是否相关,类似于NoSQL的结果只能是0或1,而搜索里面可能会有0.1,0.5,0.9等部分匹配或者更相关的情况。
结果召回上,搜索一般只需要召回最满足条件的Top N结果即可,而NoSQL一般都需要返回满足条件的所有结果。
搜索系统一般都是两阶段查询,第一个阶段查询到对应的Doc ID,也就是PK;第二阶段再通过Doc ID去查询完整文档,而NoSQL数据库一般是一阶段就返回结果。而在Elasticsearch中两种都支持。
目前NoSQL的查询,聚合、分析和统计等功能上都是要比搜索弱的。
Lucene的读
Elasticsearch使用了Lucene作为搜索引擎库,通过Lucene完成特定字段的搜索等功能,在Lucene中这个功能是通过IndexSearcher的下列接口实现的:
public TopDocs search(Query query, int n);
public Document doc(int docID);
public int count(Query query);
......(其他)第一个search接口实现搜索功能,返回最满足Query的N个结果;第二个doc接口实现通过doc id查询Doc内容的功能;第三个count接口实现通过Query获取到命中数的功能。
这三个功能是搜索中的最基本的三个功能点,对于大部分Elasticsearch中的查询都是比较复杂的,直接用这个接口是无法满足需求的,比如分布式问题。这些问题都留给了Elasticsearch解决,我们接下来看Elasticsearch中相关读功能的剖析。
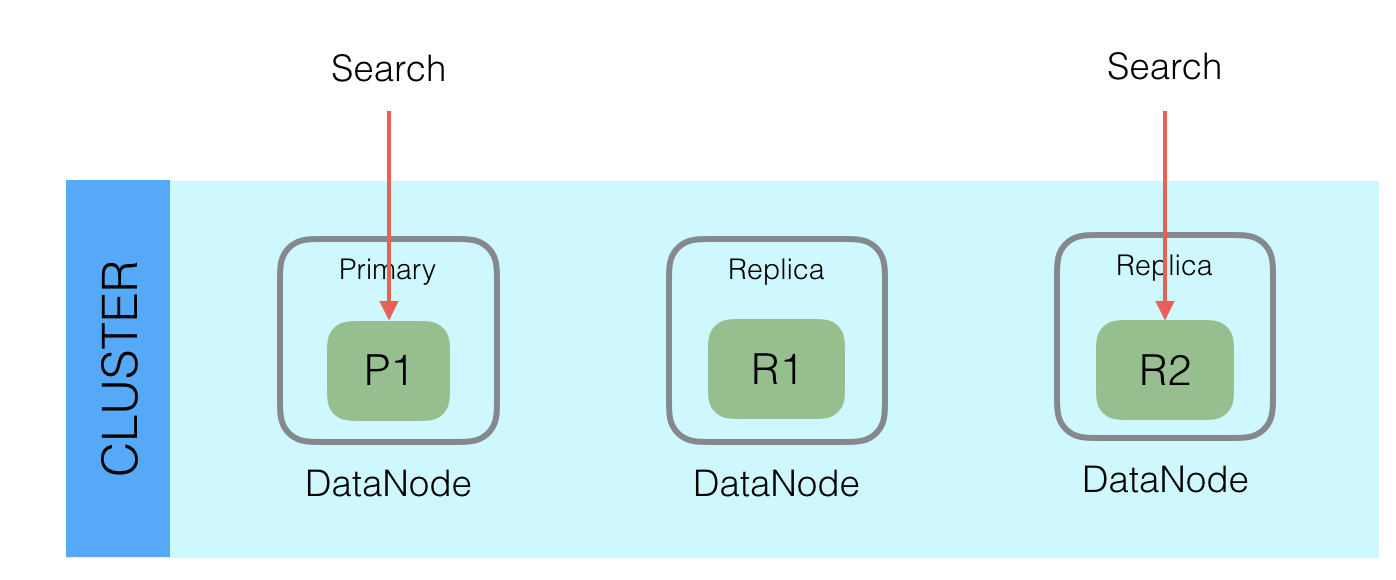
在上图中,该Shard有1个Primary和2个Replica Node,当查询的时候,从三个节点中根据Request中的preference参数选择一个节点查询。preference可以设置local,primary,_replica以及其他选项。如果选择了primary,则每次查询都是直接查询Primary,可以保证每次查询都是最新的。如果设置了其他参数,那么可能会查询到R1或者R2,这时候就有可能查询不到最新的数据。
上述代码逻辑在OperationRouting.Java的searchShards方法中。
接下来看一下,Elasticsearch中的查询是如何支持分布式的。
Elasticsearch中通过分区实现分布式,数据写入的时候根据_routing规则将数据写入某一个Shard中,这样就能将海量数据分布在多个Shard以及多台机器上,已达到分布式的目标。这样就导致了,查询的时候,潜在数据会在当前index的所有的Shard中,所以Elasticsearch查询的时候需要查询所有Shard,同一个Shard的Primary和Replica选择一个即可,查询请求会分发给所有Shard,每个Shard中都是一个独立的查询引擎,比如需要返回Top 10的结果,那么每个Shard就会查询并且返回Top 10的结果,然后在Client Node里面会接收所有Shard的结果,然后通过优先级队列二次排序,选择出Top 10的结果,返回给用户。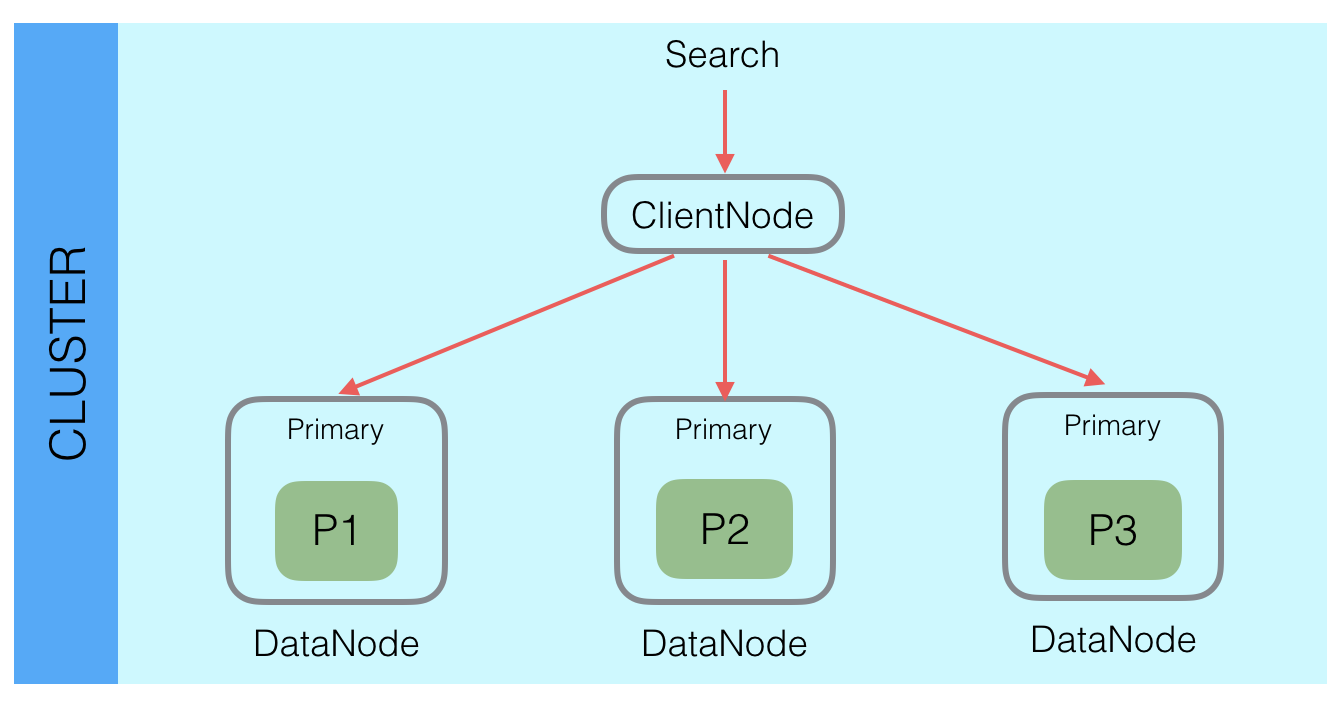
这里有一个问题就是请求膨胀,用户的一个搜索请求在Elasticsearch内部会变成Shard个请求,这里有个优化点是,虽然是Shard个请求,但是这个Shard个数不一定要是当前Index中的Shard个数,只要是当前查询相关的Shard即可,通过这种方式可以优化请求膨胀数。
Elasticsearch中的查询主要分为两类,Get请求:通过ID查询特定Doc;Search请求:通过Query查询匹配Doc。
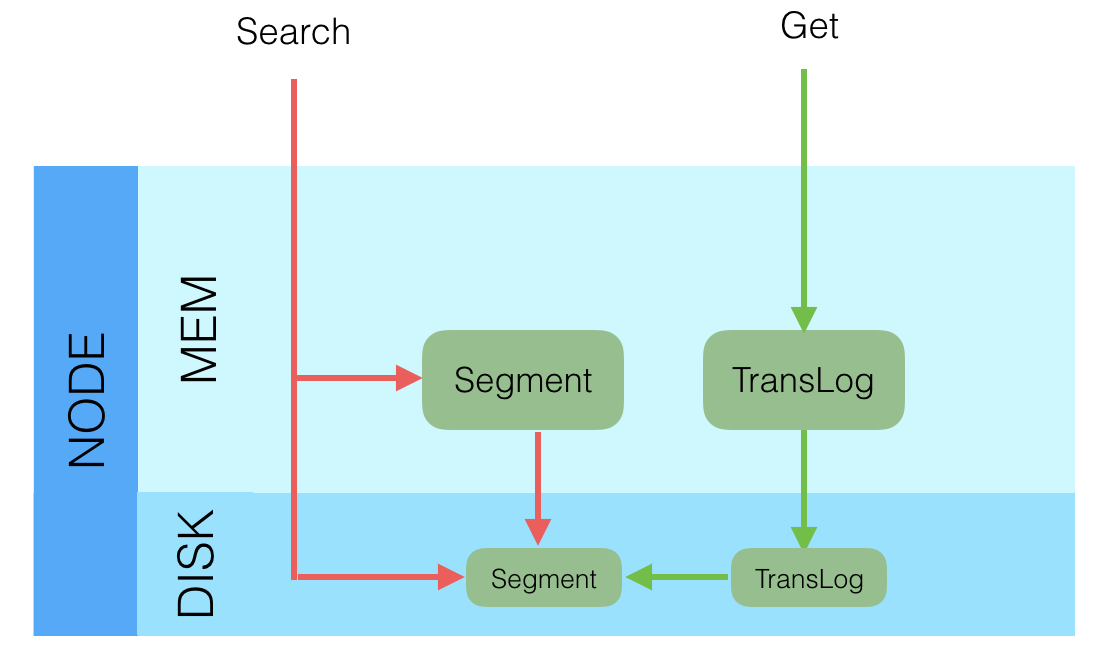
上图中内存中的Segment是指刚Refresh Segment,但是还没持久化到磁盘的新Segment,而非从磁盘加载到内存中的Segment。
对于Search类请求,查询的时候是一起查询内存和磁盘上的Segment,最后将结果合并后返回。这种查询是近实时(Near Real Time)的。
对于Get类请求,查询的时候是先查询内存中的TransLog,如果找到就立即返回,如果没找到再查询磁盘上的TransLog,如果还没有则再去查询磁盘上的Segment。这种查询是实时(Real Time)的。这种查询顺序可以保证查询到的Doc是最新版本的Doc,这个功能也是为了保证NoSQL场景下的实时性要求。
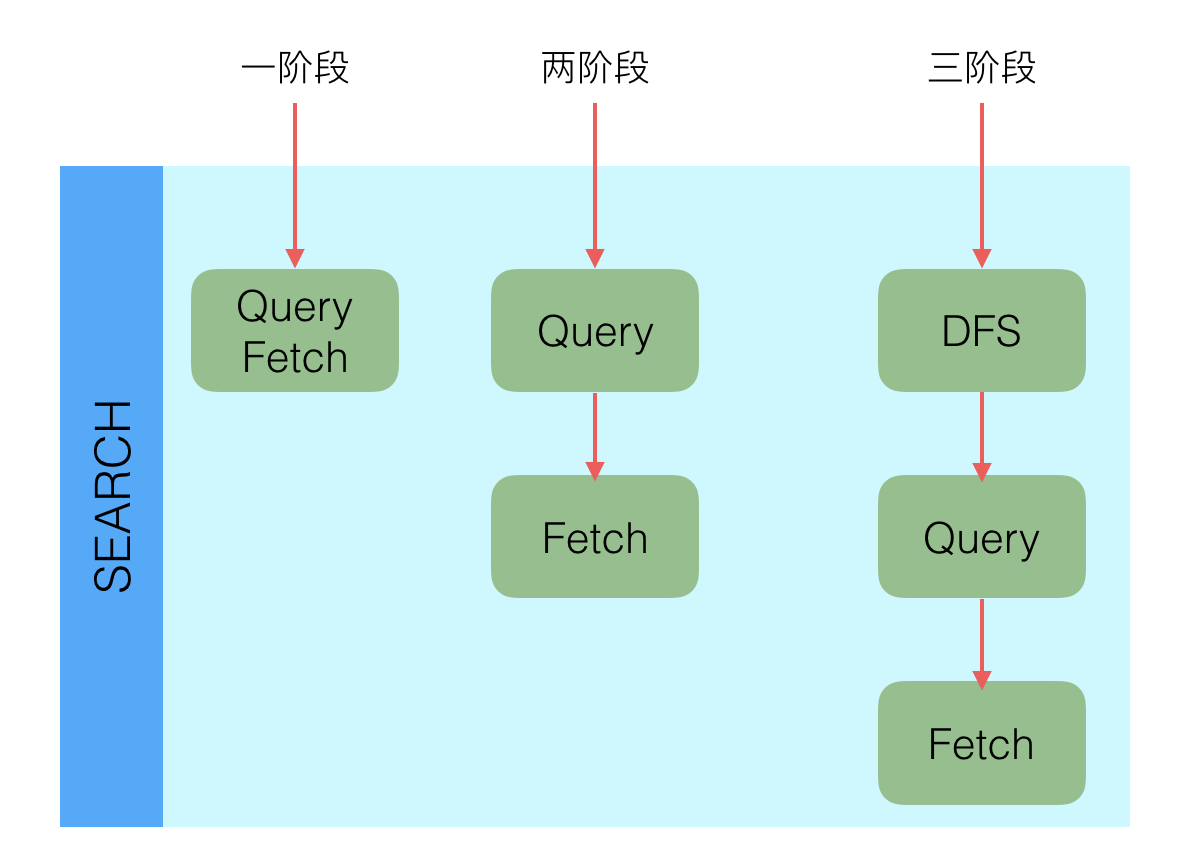
所有的搜索系统一般都是两阶段查询,第一阶段查询到匹配的DocID,第二阶段再查询DocID对应的完整文档,这种在Elasticsearch中称为query_then_fetch,还有一种是一阶段查询的时候就返回完整Doc,在Elasticsearch中称作query_and_fetch,一般第二种适用于只需要查询一个Shard的请求。
除了一阶段,两阶段外,还有一种三阶段查询的情况。搜索里面有一种算分逻辑是根据TF(Term Frequency)和DF(Document Frequency),但是Elasticsearch中查询的时候,是在每个Shard中独立查询的,每个Shard中的TF和DF也是独立的,虽然在写入的时候通过_routing保证Doc分布均匀,但是没法保证TF和DF均匀,那么就有会导致局部的TF和DF不准的情况出现,这个时候基于TF、DF的算分就不准。为了解决这个问题,Elasticsearch中引入了DFS查询,比如DFS_query_then_fetch,会先收集所有Shard中的TF和DF值,然后将这些值带入请求中,再次执行query_then_fetch,这样算分的时候TF和DF就是准确的,类似的有DFS_query_and_fetch。这种查询的优势是算分更加精准,但是效率会变差。另一种选择是用BM25代替TF/DF模型。
Elasticsearch查询流程
Elasticsearch中的大部分查询,以及核心功能都是Search类型查询,上面我们了解到查询分为一阶段,二阶段和三阶段,这里我们就以最常见的的二阶段查询为例来介绍查询流程。
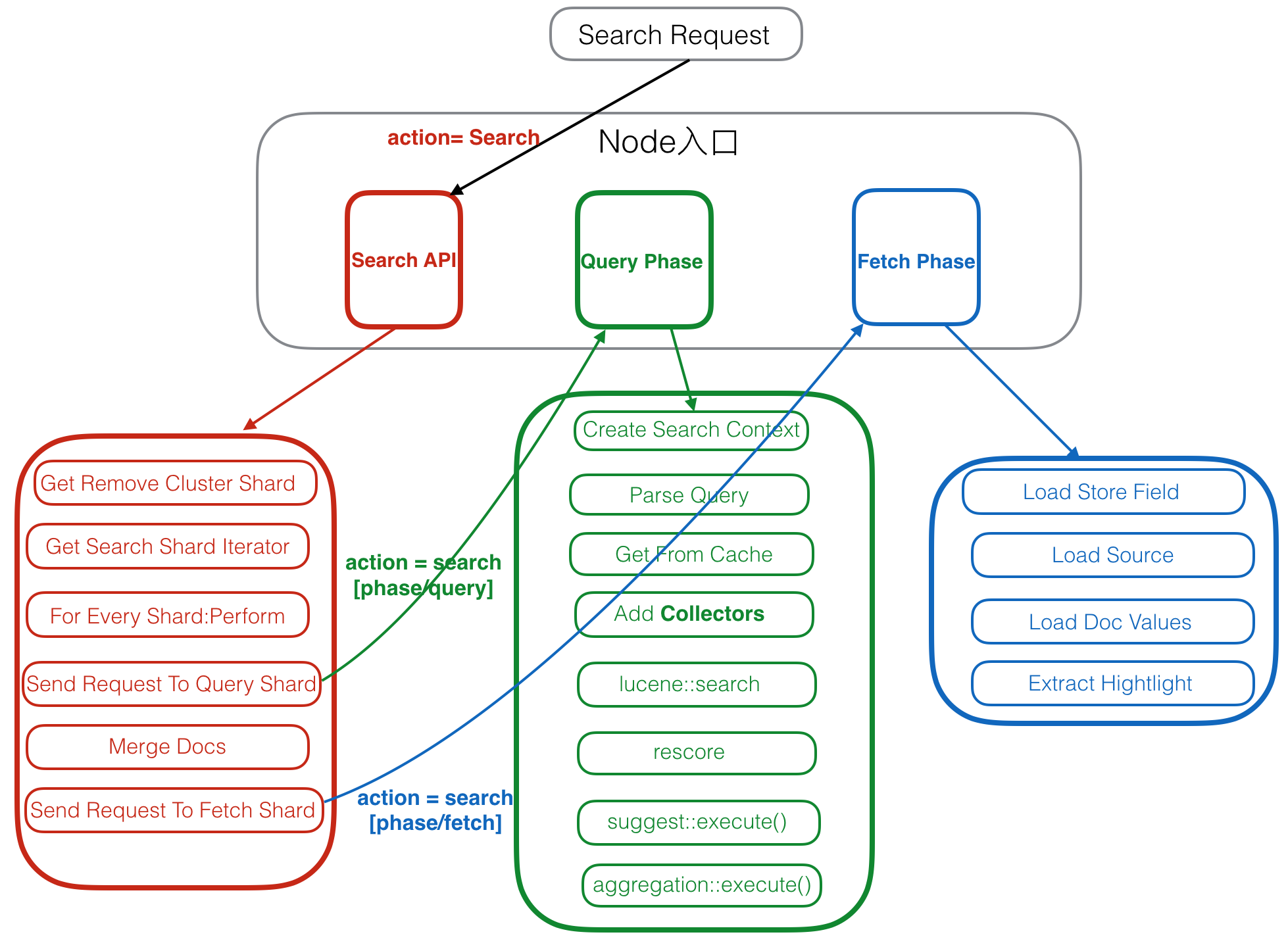
注册Action
Elasticsearch中,查询和写操作一样都是在ActionModule.java中注册入口处理函数的。
registerHandler.accept(new RestSearchAction(settings, restController));
......
actions.register(SearchAction.INSTANCE, TransportSearchAction.class);
......如果请求是Rest请求,则会在RestSearchAction中解析请求,检查查询类型,不能设置为dfs_query_and_fetch或者query_and_fetch,这两个目前只能用于Elasticsearch中的优化场景,然后发给后面的TransportSearchAction.class处理。然后构造SearchRequest,将请求发送给TransportSearchAction中处理。


如果是第一阶段的Query Phase请求,则会调用SearchService的executeQueryPhase方法
如果是第二阶段的Fetch Phase请求,则会调用SearchService的executeFetchPhase方法。
Client Node
Client Node 也包括了前面说过的Parse Request,这里就不再赘述了,接下来看一下其他的部分。
1. Get Remove Cluster Shard
判断是否需要跨集群访问,如果需要,则获取到要访问的Shard列表。
2. Get Search Shard Iterator
获取当前Cluster中要访问的Shard,和上一步中的Remove Cluster Shard合并,构建出最终要访问的完整Shard列表。
这一步中,会在Primary Node和多个Replica Node中选择出一个要访问的Shard。
3. For Every Shard:Perform
遍历每个Shard,对每个Shard执行后面逻辑。
4. Send Request To Query Shard
将查询阶段请求发送给相应的Shard。
5. Merge Docs
上一步将请求发送给多个Shard后,这一步就是异步等待返回结果,然后对结果合并。这里的合并策略是维护一个Top N大小的优先级队列,每当收到一个shard的返回,就把结果放入优先级队列做一次排序,直到所有的Shard都返回。
翻页逻辑也是在这里,如果需要取Top 30~ Top 40的结果,这个的意思是所有Shard查询结果中的第30到40的结果,那么在每个Shard中无法确定最终的结果,每个Shard需要返回Top 40的结果给Client Node,然后Client Node中在merge docs的时候,计算出Top 40的结果,最后再去除掉Top 30,剩余的10个结果就是需要的Top 30~ Top 40的结果。
上述翻页逻辑有一个明显的缺点就是每次Shard返回的数据中包括了已经翻过的历史结果,如果翻页很深,则在这里需要排序的Docs会很多,比如Shard有1000,取第9990到10000的结果,那么这次查询,Shard总共需要返回1000 * 10000,也就是一千万Doc,这种情况很容易导致OOM。
另一种翻页方式是使用search_after,这种方式会更轻量级,如果每次只需要返回10条结构,则每个Shard只需要返回search_after之后的10个结果即可,返回的总数据量只是和Shard个数以及本次需要的个数有关,和历史已读取的个数无关。这种方式更安全一些,推荐使用这种。
如果有aggregate,也会在这里做聚合,但是不同的aggregate类型的merge策略不一样,具体的可以在后面的aggregate文章中再介绍。
6. Send Request To Fetch Shard
选出Top N个Doc ID后发送Fetch Shard给这些Doc ID所在的Shard,最后会返回Top N的Doc的内容。
Query Phase
接下来我们看第一阶段查询的步骤:
1. Create Search Context
创建Search Context,之后Search过程中的所有中间状态都会存在Context中,这些状态总共有50多个,具体可以查看DefaultSearchContext或者其他SearchContext的子类。
2. Parse Query
解析Query的Source,将结果存入Search Context。这里会根据请求中Query类型的不同创建不同的Query对象,比如TermQuery、FuzzyQuery等。
这里包括了dfsPhase、queryPhase和fetchPhase三个阶段的preProcess部分,只有queryPhase的preProcess中有执行逻辑,其他两个都是空逻辑,执行完preProcess后,所有需要的参数都会设置完成。
由于Elasticsearch中有些请求之间是相互关联的,并非独立的,比如scroll请求,所以这里同时会设置Context的生命周期。
同时会设置lowLevelCancellation是否打开,这个参数是集群级别配置,同时也能动态开关,打开后会在后面执行时做更多的检测,检测是否需要停止后续逻辑直接返回。
3. Get From Cache
判断请求是否允许被Cache,如果允许,则检查Cache中是否已经有结果,如果有则直接读取Cache,如果没有则继续执行后续步骤,执行完后,再将结果加入Cache。
4. Add Collectors
Collector主要目标是收集查询结果,实现排序,自定义结果集过滤和收集等。这一步会增加多个Collectors,多个Collector组成一个List。
- FilteredCollector:先判断请求中是否有Post Filter,Post Filter用于Search,Agg等结束后再次对结果做Filter,希望Filter不影响Agg结果。如果有Post Filter则创建一个FilteredCollector,加入Collector List中。
- PluginInMultiCollector:判断请求中是否制定了自定义的一些Collector,如果有,则加入Collector List。
- MinimumScoreCollector:判断请求中是否制定了最小分数阈值,如果指定了,则创建MinimumScoreCollector加入Collector List中,在后续收集结果时,会过滤掉得分小于最小分数的Doc。
- EarlyTerminatingCollector:判断请求中是否提前结束Doc的Seek,如果是则创建EarlyTerminatingCollector,加入Collector List中。在后续Seek和收集Doc的过程中,当Seek的Doc数达到Early Terminating后会停止Seek后续倒排链。
-
CancellableCollector:判断当前操作是否可以被中断结束,比如是否已经超时等,如果是会抛出一个TaskCancelledException异常。该功能一般用来提前结束较长的查询请求,可以用来保护系统。
1.EarlyTerminatingSortingCollector:如果Index是排序的,那么可以提前结束对倒排链的Seek,相当于在一个排序递减链表上返回最大的N个值,只需要直接返回前N个值就可以了。这个Collector会加到Collector List的头部。EarlyTerminatingSorting和EarlyTerminating的区别是,EarlyTerminatingSorting是一种对结果无损伤的优化,而EarlyTerminating是有损的,人为掐断执行的优化。 - TopDocsCollector:这个是最核心的Top N结果选择器,会加入到Collector List的头部。TopScoreDocCollector和TopFieldCollector都是TopDocsCollector的子类,TopScoreDocCollector会按照固定的方式算分,排序会按照分数+doc id的方式排列,如果多个doc的分数一样,先选择doc id小的文档。而TopFieldCollector则是根据用户指定的Field的值排序。
5. lucene::search
这一步会调用Lucene中IndexSearch的search接口,执行真正的搜索逻辑。每个Shard中会有多个Segment,每个Segment对应一个LeafReaderContext,这里会遍历每个Segment,到每个Segment中去Search结果,然后计算分数。
搜索里面一般有两阶段算分,第一阶段是在这里算的,会对每个Seek到的Doc都计算分数,一般是算一个基本分数。这一阶段完成后,会有个排序。然后再第二阶段,再对Top 的结果做一次二阶段算分,在二阶段算分的时候会考虑更多的因子。二阶段算分在下一步中。
Lucene中详细的查询流程,后面会有专门文章介绍。
6. rescore
根据Request中是否包含rescore配置决定是否进行二阶段排序,如果有则执行二阶段算分逻辑,会考虑更多的算分因子。二阶段算分也是一种计算机中常见的多层设计,是一种资源消耗和效率的折中。
Elasticsearch中支持配置多个Rescore,这些rescore逻辑会顺序遍历执行。每个rescore内部会先按照请求参数window选择出Top window的doc,然后对这些doc排序,排完后再合并回原有的Top 结果顺序中。
7. suggest::execute()
如果有推荐请求,则在这里执行推荐请求。如果请求中只包含了推荐的部分,则很多地方可以优化。推荐不是今天的重点,这里就不介绍了,后面有机会再介绍。
8. aggregation::execute()
如果含有聚合统计请求,则在这里执行。Elasticsearch中的aggregate的处理逻辑也类似于Search,通过多个Collector来实现。在Client Node中也需要对aggregation做合并。aggregate逻辑更复杂一些,就不在这里赘述了,后面有需要就再单独开文章介绍。
上述逻辑都执行完成后,如果当前查询请求只需要查询一个Shard,那么会直接在当前Node执行Fetch Phase。
Fetch Phase
Elasticsearch作为搜索系统时,或者任何搜索系统中,除了Query阶段外,还会有一个Fetch阶段,这个Fetch阶段在数据库类系统中是没有的,是搜索系统中额外增加的阶段。搜索系统中额外增加Fetch阶段的原因是搜索系统中数据分布导致的,在搜索中,数据通过routing分Shard的时候,只能根据一个主字段值来决定,但是查询的时候可能会根据其他非主字段查询,那么这个时候所有Shard中都可能会存在相同非主字段值的Doc,所以需要查询所有Shard才能不会出现结果遗漏。同时如果查询主字段,那么这个时候就能直接定位到Shard,就只需要查询特定Shard即可,这个时候就类似于数据库系统了。另外,数据库中的二级索引又是另外一种情况,但类似于查主字段的情况,这里就不多说了。
基于上述原因,第一阶段查询的时候并不知道最终结果会在哪个Shard上,所以每个Shard中管都需要查询完整结果,比如需要Top 10,那么每个Shard都需要查询当前Shard的所有数据,找出当前Shard的Top 10,然后返回给Client Node。如果有100个Shard,那么就需要返回100 * 10 = 1000个结果,而Fetch Doc内容的操作比较耗费IO和CPU,如果在第一阶段就Fetch Doc,那么这个资源开销就会非常大。所以,一般是当Client Node选择出最终Top N的结果后,再对最终的Top N读取Doc内容。通过增加一点网络开销而避免大量IO和CPU操作,这个折中是非常划算的。
Fetch阶段的目的是通过DocID获取到用户需要的完整Doc内容。这些内容包括了DocValues,Store,Source,Script和Highlight等,具体的功能点是在SearchModule中注册的,系统默认注册的有:
- ExplainFetchSubPhase
- DocValueFieldsFetchSubPhase
- ScriptFieldsFetchSubPhase
- FetchSourceSubPhase
- VersionFetchSubPhase
- MatchedQueriesFetchSubPhase
- HighlightPhase
- ParentFieldSubFetchPhase
除了系统默认的8种外,还有通过插件的形式注册自定义的功能,这些SubPhase中最重要的是Source和Highlight,Source是加载原文,Highlight是计算高亮显示的内容片断。
上述多个SubPhase会针对每个Doc顺序执行,可能会产生多次的随机IO,这里会有一些优化方案,但是都是针对特定场景的,不具有通用性。
Fetch Phase执行完后,整个查询流程就结束了。
概念解析
CURD 操作
CURD 操作都是针对具体的某个或某些文档的操作,每个文档的 routing 都是确认的,所以其所在分片也是可以事先确定的。该过程对应 ES 的 Document API。

- 新建(C): 指对某个文档进行索引操作的过程。
- 检索(R): 指从 ES 中获取某个或多个特定文档的过程。
- 删除(D): 指从 ES 中删除某个文档让其不再可被搜索。
- 更新(U): 指在 ES 中更新某个文档的过程,其实质是删除+新建的过程。
搜索
搜索操作是指通过查询条件从 ES 中获取匹配的文档的过程,搜索前不知道哪个文档会匹配查询。该过程对应 ES 的 Search API。
路由和分片
分片
- 文档在索引的时候,需要确定文档存放到哪个分片上去。(通过把 _id 作为 routing 来计算 shard)
- 文档在检索的时候,需要确定文档处在具体哪个分片上。(通过把 _id 作为 routing 来计算 shard)
路由
分片的确定,都是由路由来完成的,具体计算公式如下:
shard = hash(routing) % number_of_primary_shards- routing 值是一个任意字符串,它默认是 _id 但也可以自定义。
- routing 字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所
在的分片。 - 这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
文档的新建、索引和删除
流程
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。并且要等所有复制分片完成后才向请求节点返回。
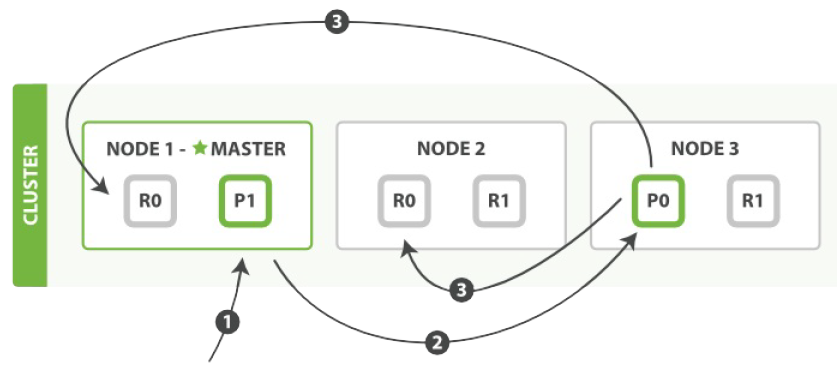
在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
- 1. 客户端给 Node 1 发送新建、索引或删除请求,Node 1 作为协调节点。
- 2. 协调节点使用文档的 _id 确定文档属于分片 0 (通过把 _id 作为 routing 来计算 shard)。它转发请求到 Node 3 (主分片位于这个节点上)。
- 3. Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上。当所有的复制节点报告成功, Node 3 报告成功给协调节点。
- 4. 协调节点返回结果给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。
由于要主分片和复制分片都成功后才返回成功,所以写操作是比较耗时的。
优化
replication:
replication 默认为 sync。也就是要等所有复制分片都操作完后才返回。
设置为 async 运行在主分片操作完成后即返回。
文档的检索
流程
检索文档为读(read)操作,请求只需分片的任意一个副本返回操作结果即完成。
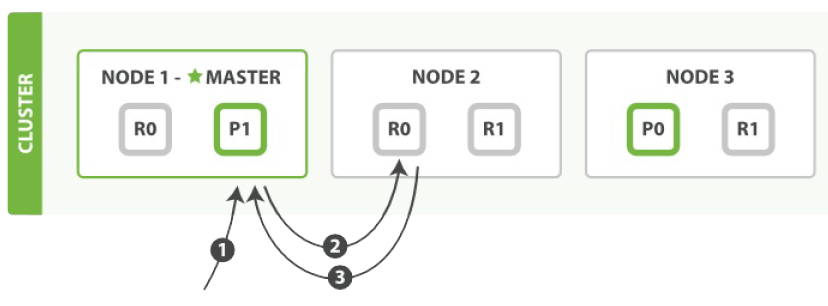
在主分片或复制分片上检索一个文档必要的顺序步骤:
- 1. 客户端给 Node1(主节点) 发送 get 请求,Node 1 作为协调节点。
- 2. 协调节点使用文档的 _id 确定文档属于分片 0(通过把 _id 作为 routing 来计算 shard) 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到 Node 2 。
- 3. Node 2 返回执行结果给协调节点。
- 4. 协调节点返回结果给客户端。
对于读请求,为了平衡负载,协调节点会为每个分片的请求选择不同的副本——它会循环所有分片副本。
文档的更新
流程
更新过程整体流程就是 “读” + “写” 操作。
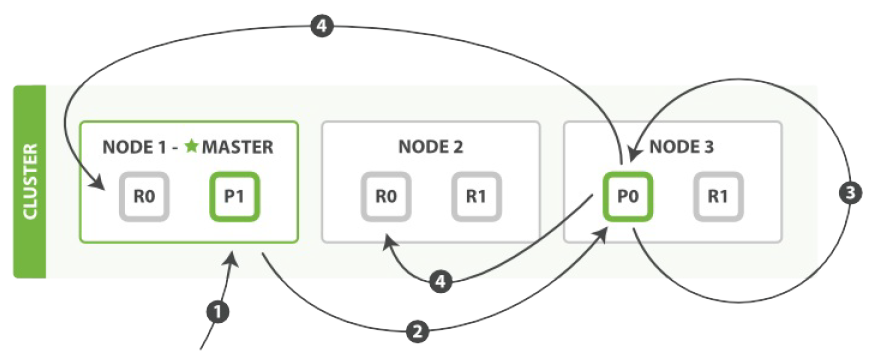
执行更新必要的顺序步骤:
- 1. 客户端给 Node 1 发送更新请求,Node 1 作为协调节点。
- 2. 协调节点转发请求到主分片所在节点 Node 3(主分片) 。
- 3. Node 3 从主分片检索出文档,修改 _source 字段的JSON,然后在主分片上重新索引。如果有其他进程修改了文档,它以 retry_on_conflict 设置的次数重复步骤3,都未成功则放弃。
- 4. 如果 Node 3 成功更新文档,它同时转发文档的新版本到 Node 1 和 Node 2 上的复制分片以重新索引。当所有节点报告成功, Node 3 返回成功给协调节点。
- 5. 协调节点返回结果给客户端。
批量文档操作
批量检索(mget)和批量新建、索引、更新、删除(bulk)操作和单个文档的操作过程类似。
区别在于协调节点知道所有文档所在的分片,并将请求的文档根据所在的分片来分组。然后同时请求需要的节点。
一旦收到所有节点的响应,协调节点再将这多个节点的响应组合成一个响应结果返回给客户端。
流程
mget 操作
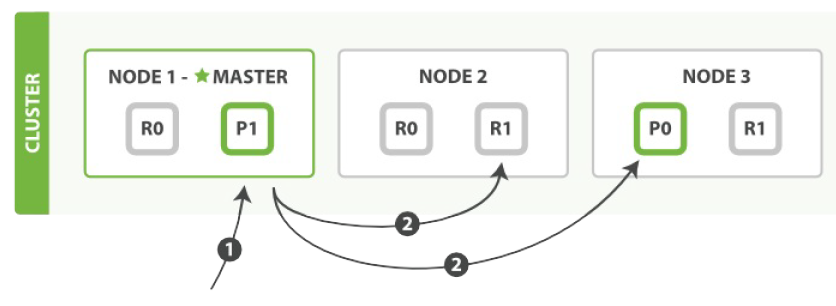
mget 操作过程基本步骤:
- 1. 客户端发送请求到 Node 1,Node 1 作为协调节点。
- 2. 协调节点确认每一个操作请求的目标分片,并根据需要请求的目标分片重新分组。
- 2. 协调节点同时转发每组请求到目标主分片或复制分片(检索操作任意分片都可以)。
- 3. 一旦所有请求的分片都返回,协调节点整理结果,并返回给客户端。
bulk操作

bulk 操作过程基本步骤:
- 1. 客户端发送请求到 Node 1,Node 1 作为协调节点。
- 2. 协调节点确认每一个操作请求的目标主分片,并根据目标主分片重新分组。
- 2. 协调节点同时请求包含这些主分片的节点(步骤2)。
- 3. 每一个主分片一个接一个的处理每一个文档请求——某个文档在主分片上请求成功了,主分片将请求发送给它所有的复制分片,然后就接着处理下一个文档请求。
- 4. 当所有的复制分片请求成功后,主分片所在节点就向协调节点报告成功。
- 5. 协调节点整理所有文档的结果,并返回给客户端。
搜索
文档的 CRUD 操作一次只处理一个单独的文档(批量操作也是单个执行)。CRUD 操作中,文档的唯一性由 _index , _type 和 routing (通常默认是该文档的 _id )的组合来确定。这意味着我们可以准确知道集群中的哪个分片有这个文档。
搜索过程,由于不知道哪个文档会匹配查询(文档可能存放在集群中的任意分片上),所以搜索需要一个更复杂的模型。搜索通过查询每一个我们感兴趣的索引的分片副本,来看是否含有任何匹配的文档。
搜索的执行过程分两个阶段,称为查询然后取回(query then fetch)。
查询阶段
GET /_search
{ "from": 90,
"size": 10
}

1. 客户端发送一个 search(搜索) 请求给 Node 3 , Node 3 创建了一个长度为 from+size 的空优先级队列。
2. Node 3 转发这个搜索请求到索引中每个分片的原本或副本。搜索请求可以被每个分片的原本或任意副本处理。
(并非所有副本都处理同样的请求,而是轮询处理不同的请求,所以多副本能够提高吞吐)
3. 每个分片在本地执行这个查询并且结果将结果到一个大小为 from+size 的有序本地优先队列里去。
4. 每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点 Node 3 。 Node 3 把这些值合并到自己的优先队列里产生全局排序结果。
5. 对于多(multiple)或全部(all)索引的搜索的工作机制和这完全一致——仅仅是多了一些分片而已。
取回阶段
查询阶段辨别出那些满足搜索请求的document,但我们仍然需要取回那些document本身。这就是取回阶段的工作。
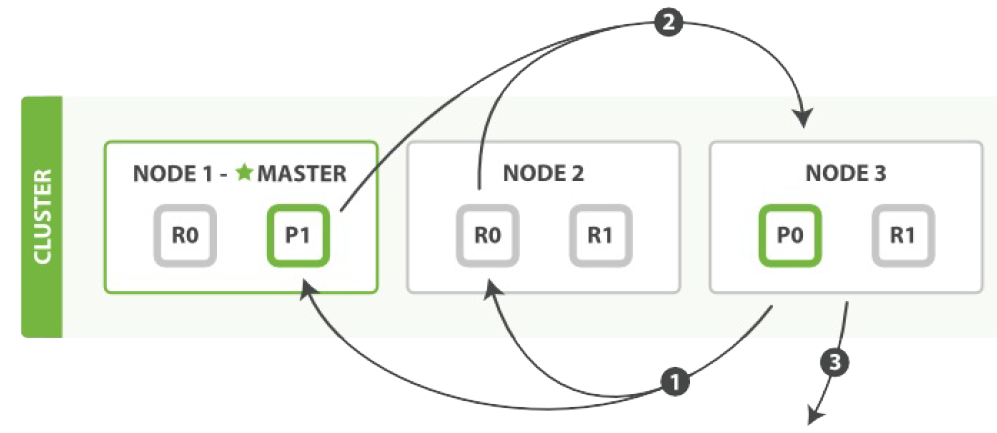
1. 协调节点(请求节点)辨别出哪个document需要取回(比如只取前100项),并且向相关分片发出 GET 请求。
2. 每个分片加载document并且根据需要丰富(enrich)它们,然后再将document返回协调节点。
3. 一旦所有的document都被取回,协调节点会将结果返回给客户端。
es里面分布式search的查询流程如下: 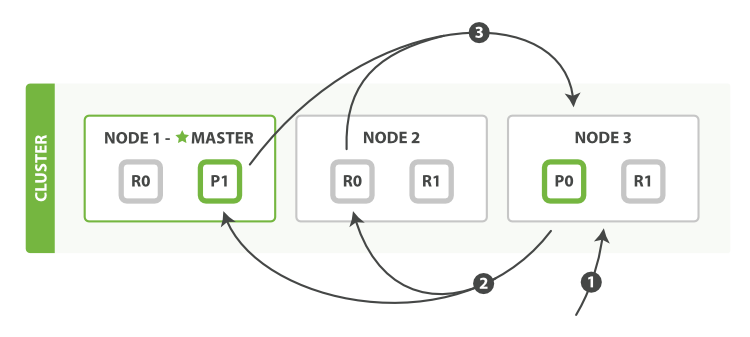
Java代码
1,客户端发送一个search请求到Node 3上,然后Node 3会创建一个优先级队列它的大小=from+size
2,接着Node 3转发这个search请求到索引里面每一个主shard或者副本shard上,每个shard会在本地查询然后添加结果到本地的排序好的优先级队列里面。
3,每个shard返回docId和所有参与排序字段的值例如_score到优先级队列里面,然后再返回给coordinating节点也就是Node 3,然后Node 3负责将所有shard里面的数据给合并到一个全局的排序的列表。
上面提到一个术语叫coordinating node,这个节点是当search请求随机负载的发送到一个节点上,然后这个节点就会成为一个coordinating node,它的职责是广播search请求到所有相关的shard上,然后合并他们的响应结果到一个全局的排序列表中然后进行第二个fetch阶段,注意这个结果集仅仅包含docId和所有排序的字段值,search请求可以被主shard或者副本shard处理,这也是为什么我们说增加副本的个数就能增加搜索吞吐量的原因,coordinating节点将会通过round-robin的方式自动负载均衡。
(二)fetch(读取阶段)
query阶段标识了那些文档满足了该次的search请求,但是我们仍然需要检索回document整条数据,这个阶段称为fetch 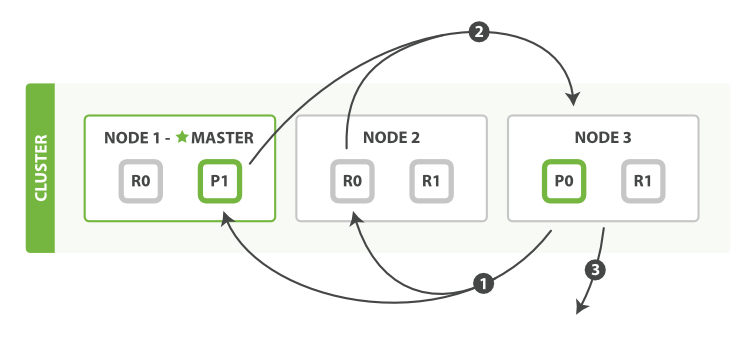
流程如下:
1,coordinating 节点标识了那些document需要被拉取出来,并发送一个批量的mutil get请求到相关的shard上
2,每个shard加载相关document,如果需要他们将会被返回到coordinating 节点上
3,一旦所有的document被拉取回来,coordinating节点将会返回结果集到客户端上。
这里需要注意,coordinating节点拉取的时候只拉取需要被拉取的数据,比如from=90,size=10,那么fetch只会读取需要被读取的10条数据,这10条数据可能在一个shard上,也可能在多个shard上所以
coordinating节点会构建一个multi-get请求并发送到每一个shard上,每个shard会根据需要从_source字段里面获取数据,一旦所有的数据返回,coordinating节点会组装数据进入单个response里面然后将其返回给最终的client。
搜索选项
1. preference:
preference 参数允许你控制使用哪个分片或节点来处理搜索请求。她接受如下一些参数 _primary , _primary_first ,_local , _only_node:xyz , _prefer_node:xyz 和 _shards:2,3
2. timeout:
通常,协调节点会等待接收所有分片的回答。如果有一个节点遇到问题,它会拖慢整个搜索请求。timeout 参数告诉协调节点最多等待多久,就可以放弃等待而将已有结果返回。
3. routing:
指定一个或多个 routing 值来限制只搜索那些分片而不是搜索index里的全部分片。
4. search_type:
- count(计数):当不需要搜索结果只需要知道满足查询的document的数量时,可以使用这个查询类型。
- query_and_fetch:搜索类型将查询和取回阶段合并成一个步骤
- dfs_query_then_fetch 和 dfs_query_and_fetch
- scan:scan(扫描) 搜索类型是和 scroll(滚屏) API连在一起使用的,可以高效地取回巨大数量的结果。它是通过禁用排序来实现的。
转自:https://yq.aliyun.com/articles/581875?spm=a2c4e.11155435.0.0.2597f4beqpiU9A

 浙公网安备 33010602011771号
浙公网安备 33010602011771号