机器学习模型并行训练
机器学习模型的并行训练方法概括分为两类:
1、数据并行
2、模型并行
关于两者区别可参考
https://leimao.github.io/blog/Data-Parallelism-vs-Model-Paralelism/
数据并行
pytorch提供了torch.nn.parallel.DistributedDataParallel接口实现模型并行训练,具体可参考该网址
https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
并行原理简单来说是把一个batch的数据分成多份,每份数据包含原来batch里的一部分样本,可看做是把一个batch划分为多个微批,这些微批同时分配到不同gpu(节点)上进行前馈反馈处理,这些节点的模型都是完整模型的拷贝,前馈反馈完成后汇集各自的梯度进行平均,同步到各个节点实现参数更新,然后进入下个batch的训练。
模型并行
模型并行是把原本完整的模型拆分成几部分,每部分在一个单独的节点(cpu或gpu)进行计算,数据如同流水线一般在不同节点间传递计算,每个节点处理的数据都是一个完整的batch,这是与数据并行的不同点,详细内容可参考
https://zhuanlan.zhihu.com/p/71566775
https://zhuanlan.zhihu.com/p/87596314
https://www.cnblogs.com/rossiXYZ/p/15681576.html
混合并行
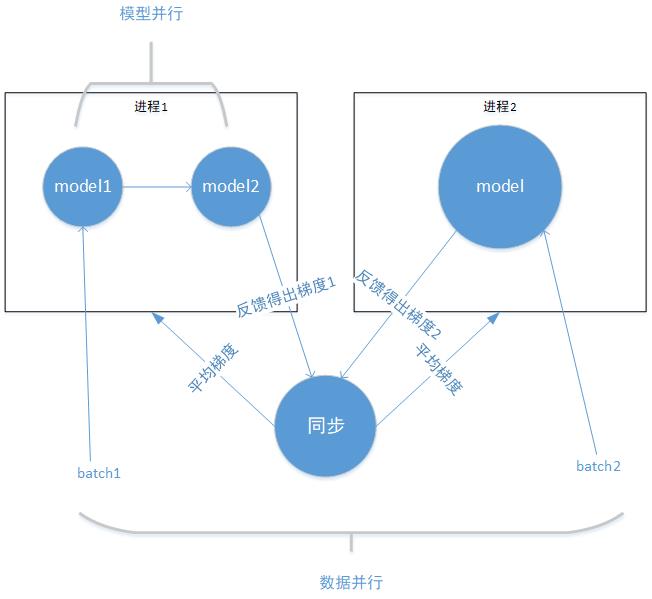
下图是混合并行架构的简化展示,只为便于理解概念。混合并行即同时使用模型并行与数据并行进行模型训练。
从进程外部来看,数据被分为batch1 、batch2,可看做是一个batch分为了两个子集,每个子集输入到对应的进程计算,最后计算出平均梯度更新参数,这是数据并行。
从进程内部看,进程1中的model1、model2分别是进程2中model拆分的两个子部分,batch1 输入到model1,其输出又作为model2的输入,最后得出整个模型的输出,这是模型并行。
自定义分布式并行训练
本节内容是对pytorch官网
https://pytorch.org/tutorials/beginner/dist_overview.html
关于并行与分布式训练的总结。
自定义分布式训练是指利用较底层的api实现定制的分布式并行模型。
可使用的接口大致三类,分别是
1、底层api(点对点通信)
主要指torch.distributed.send torch.distributed.isend
torch.distributed.recv torch.distributed.irecv等函数,该类函数属于通信原语,可实现点对点的同步或异步通信,可基于此实现较复杂的通信模式。
详细可见
https://pytorch.org/docs/stable/distributed.html
2、中层api
torch.distributed.rpc.rpc_sync(to, func, args=None, kwargs=None, timeout=- 1.0)
该函数是同步通信接口,他的功能是在指定worker上执行指定的函数,返回值是执行结果。参数1是worker的标识,参数2是需要执行的函数。
torch.distributed.rpc.rpc_async与torch.distributed.rpc.rpc_sync的区别在于,前者是异步接口,返回值是torch.future类型,可使用torch.futures.wait_all函数等待future的执行结果。
torch.distributed.rpc.remote函数也是异步接口,效果与
torch.distributed.rpc.rpc_async类似,不同的是前者返回的是torch.distributed.rpc.RRef对象,RRef是对远程对象的引用,这里的远程对象就是worker的执行结果。RRef对象引用的数据可由to_here函数获取。
pytorch针对RRef类型额外提供了基于以上函数包装的工具函数,例如
RRef.rpc_sync 、 RRef.rpc_async 、 RRef.remote , 分别对应上述三个函数,这些工具函数不再需要提供参数to,而是自己解析出来,简化开发者工作。
3、高层模式api
以all_reduce为代表的高层api实现了固定模式的数据传输方式,这部分不是本文重点,可自研。
https://pytorch.org/docs/stable/distributed.html
实例讲解
下面通过实例着重介绍中层api的使用方法。以下实例是上述混合并行架构的具体实现,参见源码https://gitee.com/ggkm/rnn-text-classifier
代码中启动了3个进程,一个为master,负责将数据分成2份,统筹各个worker计算并实现分布式求导及参数更新;每个worker负责具体的前馈运算,运算规则分别由NetShard1 , NetShard2两个类定义,两个类内部的数据流转都是linear->relu->linear,区别在于NetShard1是在一个设备上中完成计算;NetShard2的一部分在cuda:0上计算,然后再传到cuda:1上完成后续操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号