Java基础之HashCode解读
前言
在Object类中,提供了一个native方法,public native int hashCode(),该方法的返回值类型是int类型。
Hash的概念
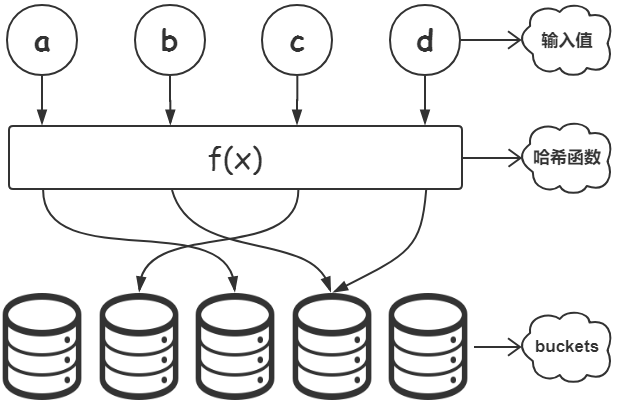
Hash,一般翻译成“散列”,或者直译为“哈希”,把任意长度的输入x,通过散列算法f(x),变成固定的长度输出,该输出值就是散列码。
1.如果结构中存在和输入值K相等的记录,则必定在f(K)的存储位置上。
2.对应关系f称为散列函数,按这个事先建立的表称为散列表,散列表由多个bucket构成,每个bucket可以存储多个散列码的位置。
3.对于两个不同的输入值K1、K2,可能得到的散列码不同,即,K1 != K2 → f(K1) == f(K2) ,这种现象称为碰撞。
4.在同一个散列函数中,如果两个输入值K1、K2,得到的散列码 f(K1) != f(K2),那么K1与K2必定不相同。
HashCode的概念
HashCode是JDK根据对象的地址,或者字符串或者数字算出来int类型的值,这个值我们称为HashCode,换一句话来说,上述提到通过散列函数得出的散列码就是HashCode。
HashCode的几个重要的性质:
1.一致性,在Java应用程序执行期间,在同一个Hash算法下,同一个对象的HashCode必定永远相同。
2.在同一个Hash算法下,当两个对象的HashCode相同,两个对象的equals方法也不一定相同,只能说明在散列的数据结构中,他们存储在同一个位置。
3.如果两个对象的equals方法相等,那么他们的HashCode必定相同。
4.重写了Object类中的equals方法,HashCode也尽量重写。
HashCode的作用
HashCode的存在就为了查找的快捷,因为HashCode是用来在散列存储结构中确定对象的存储地址,即:使用hashcode来代表对象在hash表中的位置。
举个例子,我们在内存中要维护1-10000一万个数字,我们可以采用数组,存储,当我存第9001的数字时,需要去遍历前面9000个数字,判断是否是重复,这样的操作会极为耗时,在使用hashcode,假设有200个bucket,hash表中有200个位置,比如要维护数字1,取到的hashcode为1,那就放在第一个bucket中,依次类推,当存储500时,hashcode同样为1,假设第一个位置已经有10个元素,那么只要比较10次,如果没
有相同,那就放在这个bucket中。
因此,HashCode就是为了查找便捷而生。
equals方法和hashcode方法的联系
通过上面的举例,在散列数据结构的查找中,我们先得出hashcode知道具体的位置,如果该位置上有多个元素,那么逐一比对,即调用equals方法,因此证明了以上提到的观点,
1.hashcode相同的两个对象,两个对象不一定相同,只能说明两个对象在散列数据结构中存放在同一个位置,
2.equals相同的两个对象,他们的hashcode必然相同。
为什么重写Object类中的equals方法尽量重写Object类中的hashcode方法

1 public class HashCodeTest { 2 3 private Long id; 4 private String name; 5 6 public Long getId() { 7 return id; 8 } 9 @Override 10 public boolean equals(Object obj){ 11 if(obj instanceof HashCodeTest) { 12 HashCodeTest t = (HashCodeTest)obj; 13 if(id.equals(t.id) && name.equals(t.name())) { 14 return true; 15 } 16 } 17 return false; 18 } 19 }
我们重写了Object类中的equals方法,只有两个对象类型相同,并且两个成员属性相同,两个对象才认为是相等。
1 public static void main(String[] args) { 2 System.out.println(new HashCodeTest(1L,"tom").hashCode()); 3 System.out.println(new HashCodeTest(1L,"tom").hashCode()); 4 System.out.println(new HashCodeTest(1L,"tom").hashCode()); 5 System.out.println(new HashCodeTest(1L,"tom").hashCode()); 6 System.out.println(new HashCodeTest(1L,"tom").hashCode()); 7 }
打印出来的结果是:
1528637575
1190524793
472654579
26117480
870698190
equals方法中希望id和name都完全相同则返回true,上述new HashCodeTest中的id和name均相同,如果重写hashcode,就违背了【两个对象的equals相同,hashcode必然相同】的原则,那么我们应该如何处理呢?
很简单,我们自定义一个id和name保持唯一的算法用来重写HashCode方法。
下期预告
这段时间花了大量的精力聊树结构,聊散列结构,都是为了 下期对HashMap原代码的解读打下坚实的基础。谢谢关注。
发表是最好的记忆,实践是最好的成长。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步