spark代码的提交
第一种 spark-shell ,根据官网的example 统计词频:
第一步: shell中新建一个脚本: vi wordCount.sh ;
第二步: 编写脚本:
spark-shell
--master local[2]
--jars /home/hadoop/software/mysql-connector-java-5.1.27-bin.jar
几点注意 :
第一,spark集群下core和momery都需要分配和释放,因此,调试程序时,建议master 用 local模式 ,2个线程,4个线程,看心情指定;
第二,如果需要查询hive表中的数据,而hive的元数据是存在mysql中的,那么就需要引用mysql的jar包: mysql-connector-java-5.1.27-bin.jar(5.1.27是自己安装的mysql的版本);
第三步:在spark的shell中输入scala代码:
val file = spark.sparkContext.textFile("file:///home/hadoop/data/wc.txt")
val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _)
wordCounts.collect
至此,可以喝杯咖啡,欣赏统计结果了。
第二种 spark-submit
第一步: 在idea中新建maven项目,创建scala class (object ),编写代码:
package com.imooc.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkContext,SparkConf}
/*
* 新建一个sqlContext
* 当前idea是在本地,测试数据是在服务器上的
* path = "/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.txt"
* 本地参数 C:\spark\mooc-app-spark-2.11.8-src\main\resources\people.json
* vm options: -Dspark.master=SqlContextTestApp -Dspark.master=spark://172.16.170.153:7077
*
* */
object SqlContextTestApp {
def main(args: Array[String]) = {
val path = args(0)
//1) 创建一个context类
val sparkConf = new SparkConf()
//在测试和生产环境中 appName和masterName通过脚本指定 //.setMaster("spark://172.16.170.153:7077") // a master url "local[2]"
sparkConf.setAppName("SQLContextApp").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val sqlcontext = new SQLContext(sc)
//2) 相关处理
val people = sqlcontext.read.format("json").load(path)
people.printSchema()
people.show()
//3) 关闭资源
sc.stop()
}
}
第二步 本地配置args参数后,运行,可以看到json数据在本地的运行结果如下:
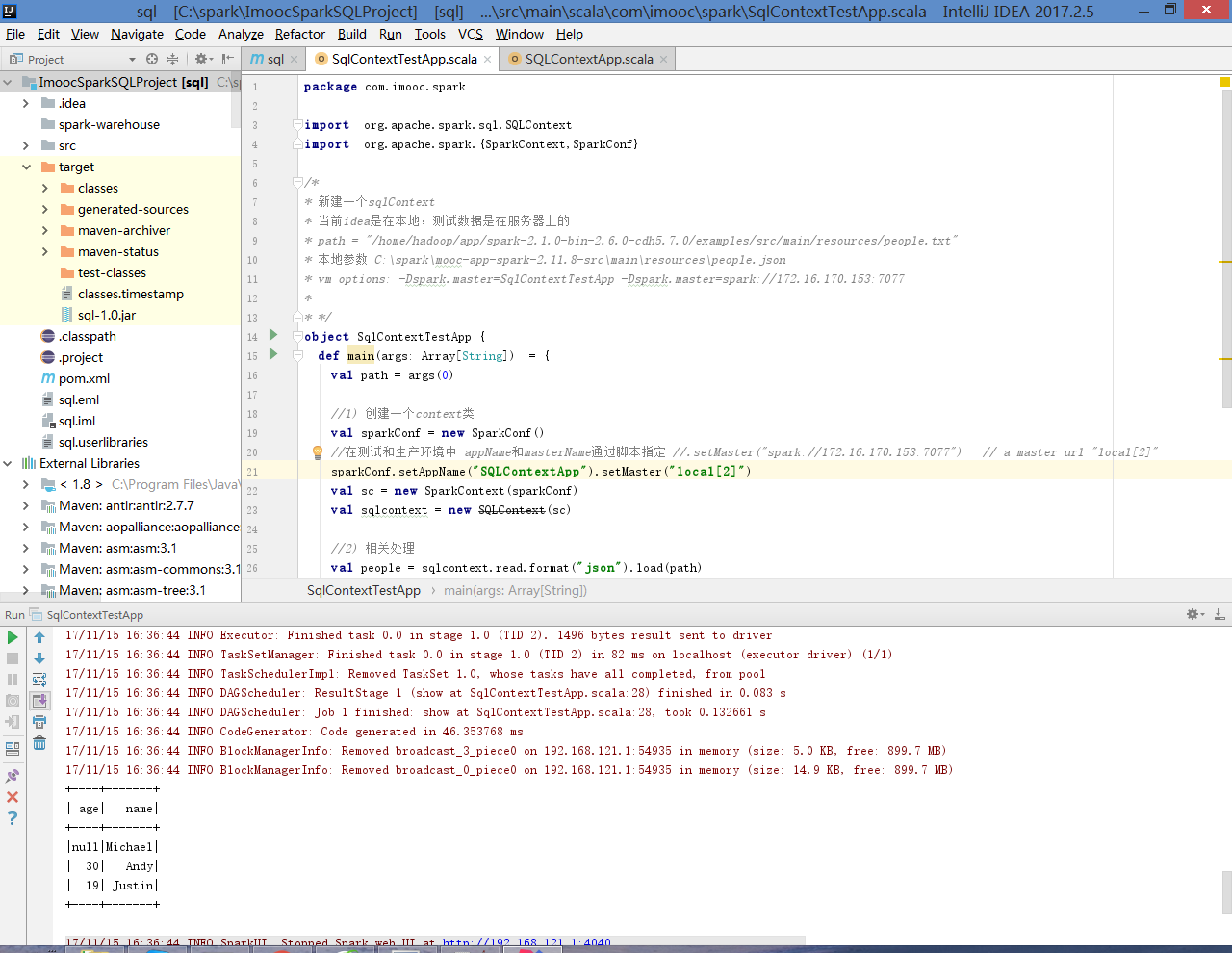
第三步 将target下的jar包 sql-1.0.jar 上传到集群;
第四步 服务器上新建脚本 sqlContext.sh:
spark-submit \ --class com.imooc.spark.SQLContextApp \ --master local[2] \ /home/hadoop/lib/sql-1.0.jar \ /home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json
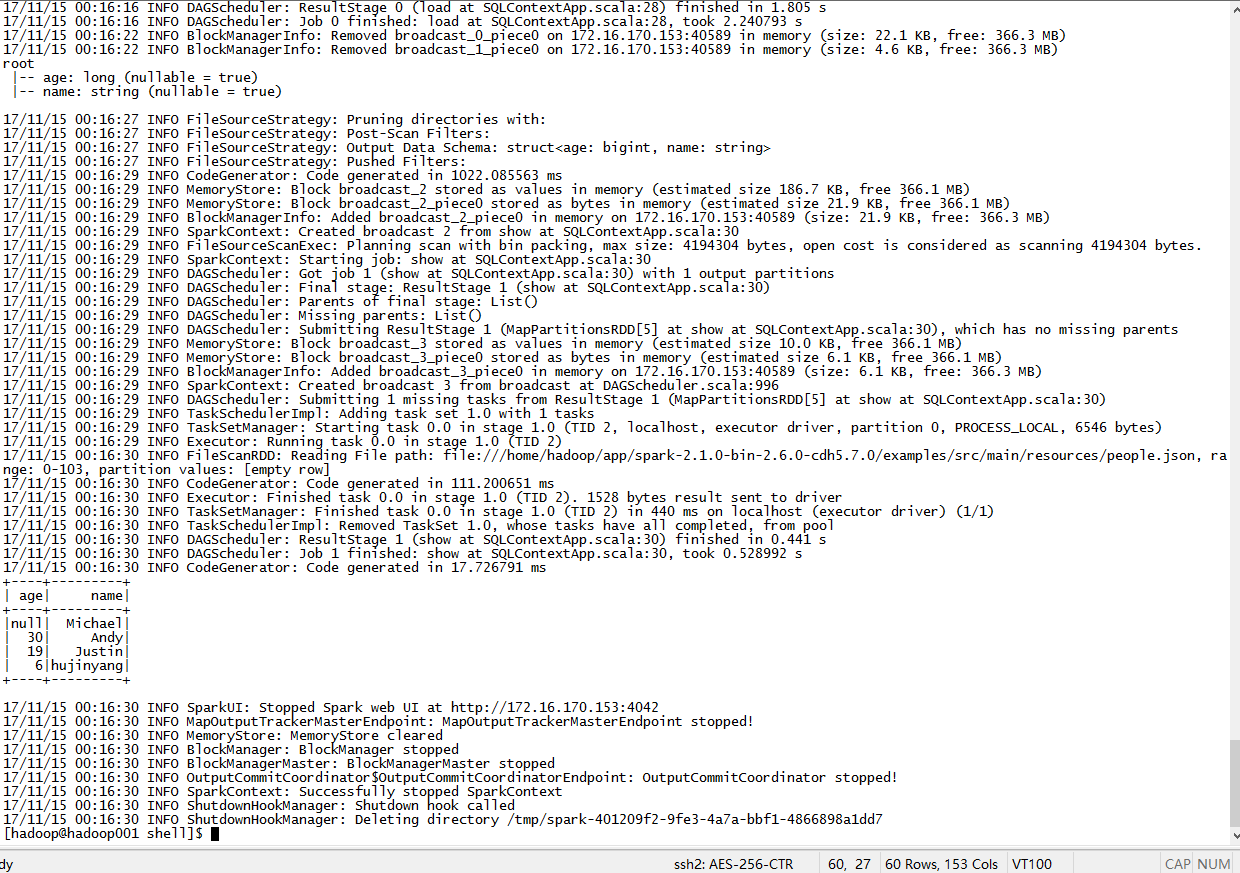
喝杯咖啡,欣赏服务器上的运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号