[学习笔记] 根号数据结构
前几天太摸了,来个大的。参考了 lxl 的 ppt 和神仙们的众多博客。
若没有特殊说明,默认
本文未完。
根号分治
就是在预处理与询问的复杂度之间寻找平衡的一个思想。通常以根号作为问题规模的分界线,规模小于根号的询问可以
一个简单的抽象是有
还有一种常用的技巧是先搞两个暴力出来,然后取个阈值把两个暴力拼一拼,有很大概率能行。
虽然这里说得很简单,但根号分治是一个非常重要的思想,同时也是很厉害的东西,平时做题/考试的时候千万不要把它忘了。
听说 ntf 说过 “没事的时候考虑根号分治”,其实是非常有道理的。
P5901 [IOI2009] regions
容易想到两种暴力:
暴力
暴力
显然这两个暴力都是不能通过的。考虑把这两个暴力拼一拼,设属性为
-
当
-
当
因此总时间复杂度为
CF1039D You Are Given a Tree
注意到若
卡常小技巧:将每个节点的父亲预处理出来,然后按照 DFS 序排序,这样可以直接循环树形 DP,就不需要 DFS了。时间复杂度
分块
分块可以分为动态分块和静态分块两种。
静态分块指的是放一些关键点,预处理关键点到关键点的信息来加速查询,不能支持修改。动态分块指的是把序列分为一些块,每块维护一些信息,可以支持修改。目前认为:如果可以离线,静态分块是莫队算法的子集。
动态分块
以下提到的分块均默认为动态分块。
例题
维护一个序列,支持区间加,查询区间和。
朴素做法有

我们把每次操作完整覆盖的块称为为“整块”,把每次操作没有完整覆盖的块称为“散块”。从上图中可以看出,每次操作我们最多经过
事实上,分块的结构是一个度数为
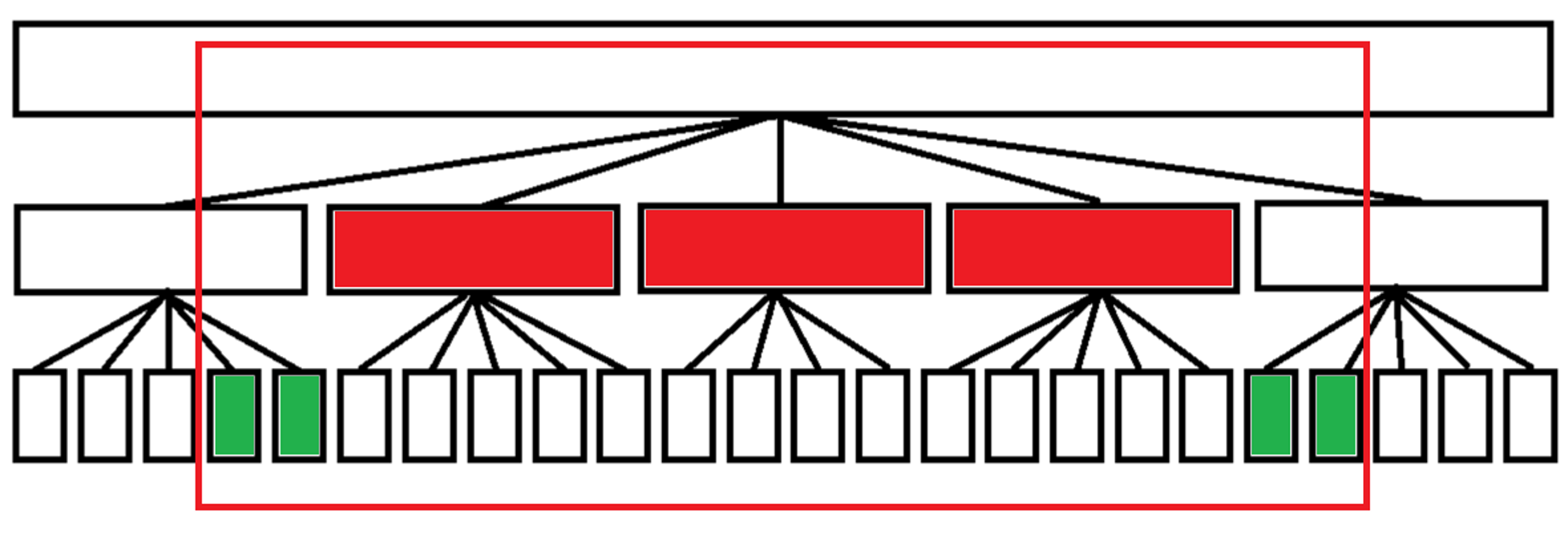
所以如果在分治结构上很难快速合并某些信息,我们就可以考虑利用分块来做。
例题
维护一个序列,支持区间加,查询区间小于
的数的个数。
容易发现,区间加这个操作使得我们没有办法在分治结构上快速地合并信息。考虑分块,维护每个块内排序后的数组。每次区间加时,对整块打标记,散块可以重构。查询时,假设整块查询小于
分析一下复杂度,假设分成了
根号平衡
有时,根据修改和查询次数的不同,我们需要调整每次修改和查询的复杂度,使得整体复杂度得到平衡。以下举几个简单例子:
-
-
-
-
-
-
Chef and Churu
先对函数分块,维护整块的答案,这只需要差分+前缀和预处理出每个数在块内出现的次数,修改是简单的。但查询时,我们希望对于散块能够
P3863 序列
将询问离线,扫描线扫序列维,数据结构维护时间维,然后变成区间加区间排名,分块维护即可。
静态分块
静态分块一般通过预处理一些信息来得到更好的复杂度,通常分整块和散块的几种情况来考虑。它的功能是莫队的子集,因此一般对于强制在线的问题我们才考虑使用静态分块。
P4168 [Violet]蒲公英
考虑分块,设块数为
预处理
P5046 [Ynoi2019 模拟赛] Yuno loves sqrt technology I
考虑分块,设块数为
如果询问不在同一块,我们分几种情况分别考虑:
-
散块及整块内部:预处理每块的前缀答案和后缀答案即可。
-
散块间:
-
散块到整块:设
-
整块到整块:即
取
操作分块
本质是对时间轴分块。
P5443 [APIO2019] 桥梁
如果只有操作
考虑操作分块,设把操作分为
每条边最多被加进
CF1588F Jumping Through the Array
如果直接暴力修改并进行加操作,这样单次复杂度
对于
对于
总复杂度为
莫队
能够高效维护区间信息的一种算法。假设有
对于序列长为
一个基础的卡常方法是奇偶排序,即对于奇数块右端点从小到大排,右端点从大到小排。原理很简单,奇数块右端点会到右边去,偶数块右端点回来的时候就可以顺便处理掉询问了。
P4689 [Ynoi2016] 这是我自己的发明
容易发现换根是假的,根据 DFS 序转化成区间查询,每个点对应
P3604 美好的每一天
能够重排成回文串的条件:区间内至多只有一个数出现奇数次。容易想到异或,每一位代表一种字符出现次数的奇偶性,维护前缀异或值
莫队二次离线
莫队二次离线基于莫队 + 扫描线的思想,通过扫描线,再次将更新答案的过程离线处理,以降低时间复杂度。具体地,若更新答案的复杂度为
其本质是将莫队当做
由于只进行了
P4887 【模板】莫队二次离线(第十四分块(前体))
如果使用用普通莫队,每一次移动指针的复杂度为
注意到,
- 一个前缀和它后面一个数的贡献,这可以预处理。
- 区间
对于其他情况也是类似的,四种情况对应的贡献变化如下:
对于扫描线部分,对每个前缀开一个 vector 存二元组
P5047 [Ynoi2019 模拟赛] Yuno loves sqrt technology II
空间限制
首先
对于第二类贡献如果使用树状数组
带修莫队
带修莫队是一种支持单点修改的莫队算法。
如果没有修改操作,一次询问可以表示为二元组
暴力查询时,如果当前修改数比询问的修改数少就把没修改的进行修改,反之回退。
需要注意的是,修改分为两部分:
-
若修改的位置在当前区间内,需要更新答案。
-
无论修改的位置是否在当前区间内,都要进行修改。
分块大小的选择及复杂度证明
以下用
-
对时间指针:对每个 r 块最坏情况下会移动
-
对左端点指针:l 块内移动每次最多
-
对右端点指针:r 块内移动每次最多
所以总移动次数为
P1903 [国家集训队] 数颜色 / 维护队列
板子题,不讲了,维护一下每个数的颜色和出现次数,按上面说的做就行。
回滚莫队(不删除莫队)
莫队的一个条件是需要在一个可以接受的复杂度内从
具体的方法如下:首先还是对询问排序,排序时以左端点所在块为第一关键字,右端点位置为第二关键字。我们把左端点在同一块内的询问一起处理,设这一块的左端点为
分析一下该做法的复杂度:每块内,右端点单调递增,移动的次数为
AT1219 歴史の研究
板子题,不讲了,维护一下每个数的出现次数,按上面说的做就行。
P5906 【模板】回滚莫队&不删除莫队
和上一题差不多,维护一下每个数最左和最右的位置,然后跑回滚莫队即可。
树上莫队
其实,莫队算法除了序列还可以用于树。复杂度和序列上的莫队相同。
树分块
我们需要先解决一个问题,类似普通莫队,我们如何对一颗树进行分块?更形式化地说,对于给定的常数
先给出如下构造方式,再予以证明:
我们对整棵树进行 DFS,并创建一个栈,DFS 一个点时先记录初始栈顶高度,每 DFS 完当前节点的一棵子树就判断栈内新增节点的数量是否
每块大小
对于当前节点的每一棵子树:
-
若未被分块的节点数
-
若未被分块的节点数
-
若未被分块的节点数
对于 DFS 结束后栈内剩余节点,其数量一定在
修改方式
类似序列上的莫队,我们需要从某个询问
下文中
-
由
-
记录答案时对
对第二步的证明:
把
括号序
另一种做法是将树的括号序分块,然后在上面跑莫队。事实上,无论常数还是代码复杂度,括号序都比树分块要更优。
具体实现就开一个
P4074 [WC2013] 糖果公园
板子题,在括号序上跑带修莫队就行了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】