dom4j解析技术
第一步导入dom4j解析技术的jar包,一般放到lib目录里面:

一般直接复制进去的时候是这样,但是这样是不能够使用,我们还要把它加入到我们类库中使用:点击选中,右键选中add as library,点击确定即可,如下图所示:
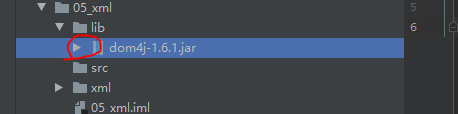
因为我们不仅需要会使用这个dom4j,同时还要学会查看里面的内容:
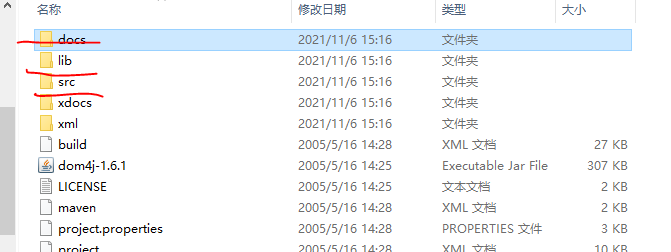
docs里面是相关的文档,在里面我们可以直接打开index,可以到dom4j的官网查看如何使用。
lib是这个dom4j所依赖的jar包。
src是这个dom4j的源程序。
我们进入dom4j官网看看吧:
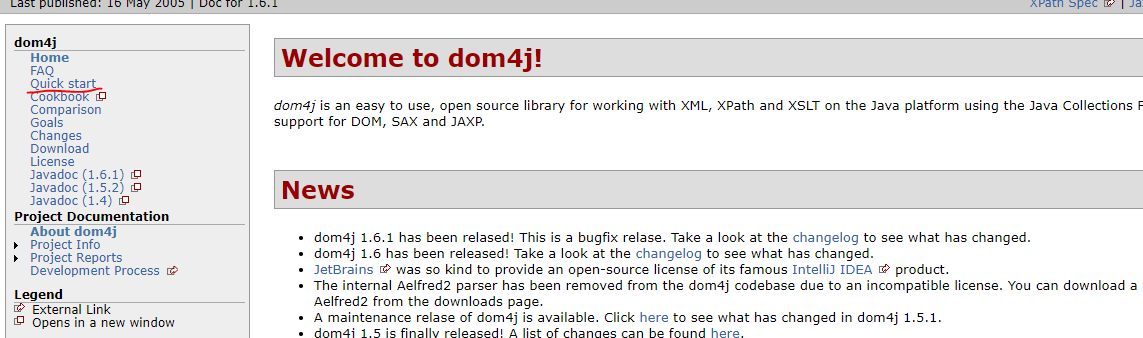
我们点击quick start快速入门:
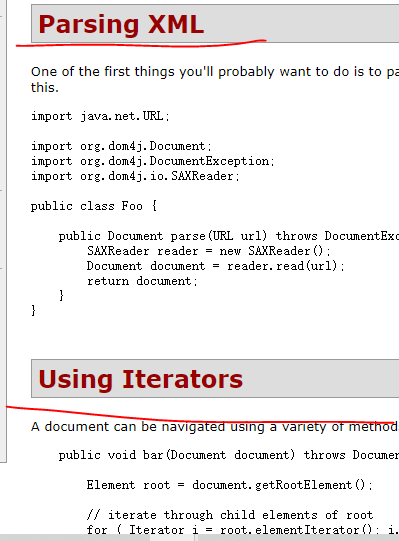
在里面我们可以找到我们所需要的很多的使用方法。
接下来就是学习如何使用dom4j了:
第一步是加载XML文档来创建Document对象
第二步是通过Document对象来获取根元素对象
第三步是通过根元素.标签名来获取我们一个遍历的集合,这个集合里面包含我们想要的标签的元素对象
第四步是找到我们想要的子元素进行增删改查操作
第五步是保存在硬盘上。
接下来我们进行完整的获取XML文档的操作吧!
第一步就是创建我们想要读取的XML文档,在src里面创建我们需要读取的XML文件,同时在src中创建读取的类,结构如下:
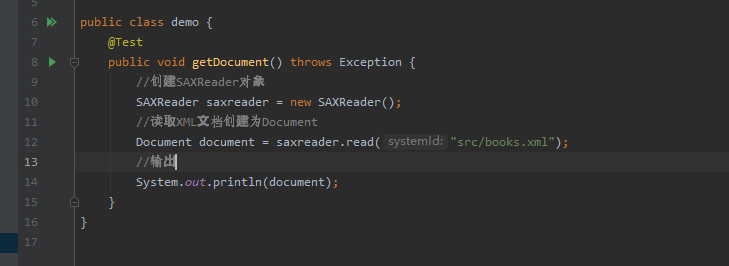
然后在demo类中书写下列代码:
我这个是在IDEA中运行,一直在报错:

我不会,上网查找之后还是不会,于是我在eclipse里面试下,是可以运行的正确如下:
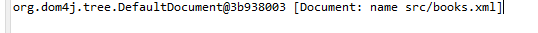
我们现在已经读取到XML里面的内容,那现在就开始将他们显示出来,这里我们要用到Element.asXML()这个方法,这个方法是将当前元素转换为String对象。
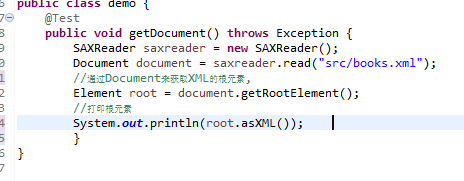
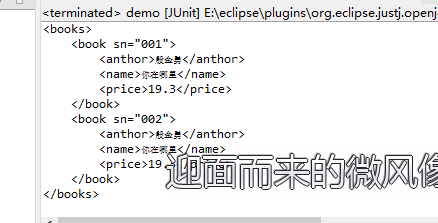
这是第二步,通过Document来获取XML的根元素,因为下面我们要用根元素来获取他的子元素。正确结果如下:
下面是通过根元素来获取他们的所有的元素,这里需要用到集合List:
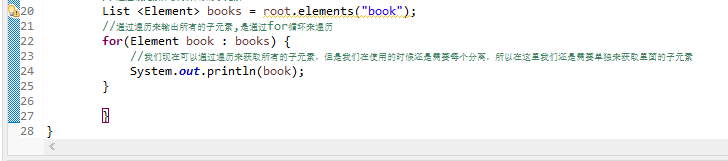
下面就是在遍历的集合里面单独获取他们的值。
在集合中获取单个元素的值有两个方法,第一个是先获取标签对象,再获取里面的值:

另一种是直接获取制定的标签对象的值:

下面就是完整的:

在这里我选择的是第二种方法,可以有效的减少代码量,在后面我输出的时候创建了一个类book,那是因为我想通过把数据传输到book这个类中再传输出来,其中价格的数据类型应该是Double才是,然后赋值的时候也应该是Double.parseDouble()才对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号