
JS中的堆内存与栈内存
在js引擎中对变量的存储主要有两种位置,堆内存和栈内存。
和java中对内存的处理类似,栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Null,**以及对象变量的指针,这时候栈内存给人的感觉就像一个线性排列的空间,每个小单元大小基本相等。
而堆内存主要负责像对象Object这种变量类型的存储,如下图
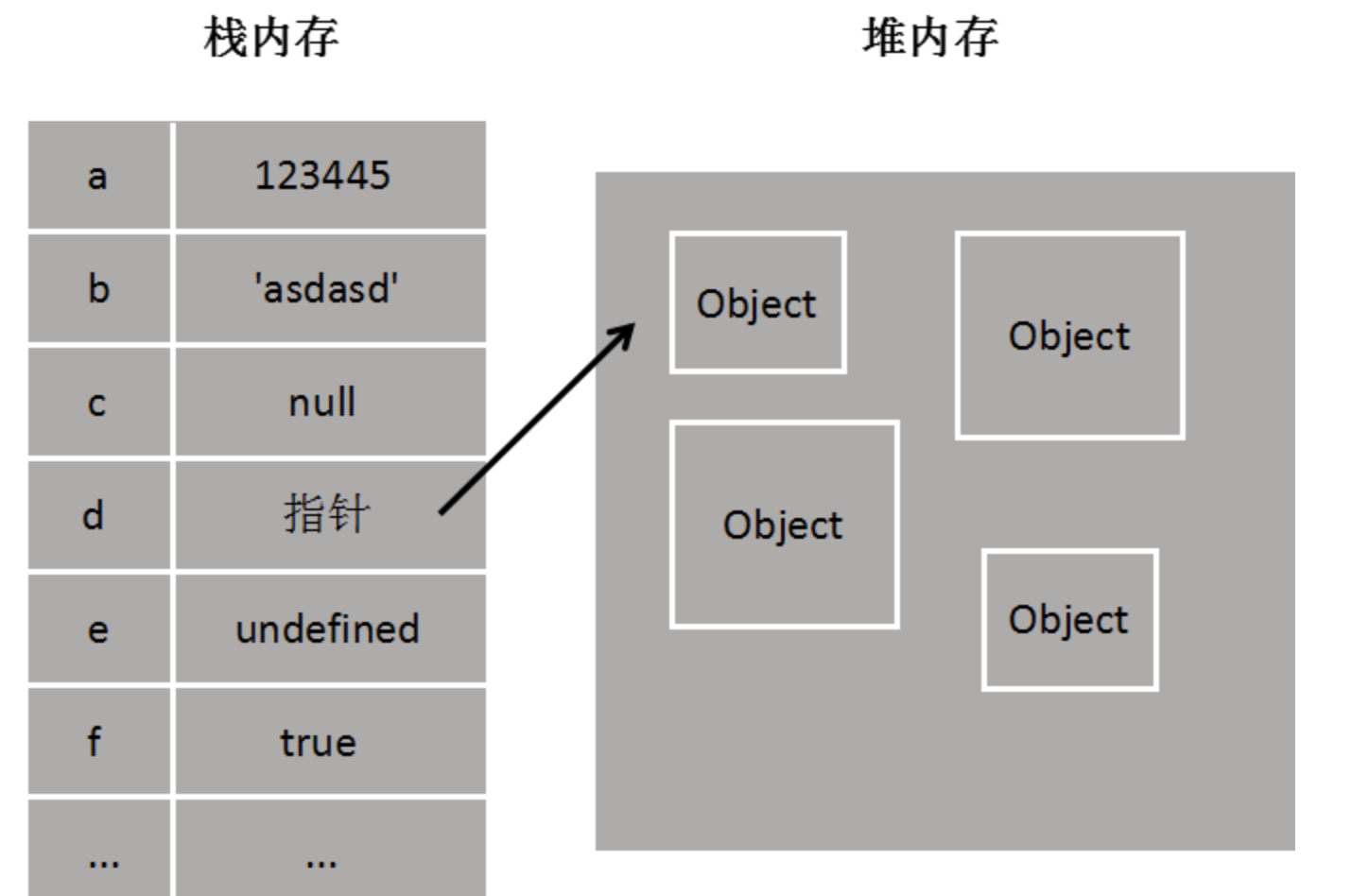
栈内存中的变量一般都是已知大小或者有范围上限的,算作一种简单存储。而堆内存存储的对象类型数据对于大小这方面,一般都是未知的。个人认为,这也是为什么null作为一个object类型的变量却存储在栈内存中的原因。
因此当我们定义一个const对象的时候,我们说的常量其实是指针,就是const对象对应的堆内存指向是不变的,但是堆内存中的数据本身的大小或者属性是可变的。而对于const定义的基础变量而言,这个值就相当于const对象的指针,是不可变。
既然知道了const在内存中的存储,那么const、let定义的变量不能二次定义的流程也就比较容易猜出来了,每次使用const或者let去初始化一个变量的时候,会首先遍历当前的内存栈,看看有没有重名变量,有的话就返回错误。
说到这里,有一个十分很容易忽略的点,之前也是自己一直没有注意的就是,使用new关键字初始化的之后是不存储在栈内存中的。为什么呢?new大家都知道,根据构造函数生成新实例,这个时候生成的是对象,而不是基本类型。再看一个例子
var a = new String('123')
var b = String('123')
var c = '123'
console.log(a==b, a===b, b==c, b===c, a==c, a===c)
>>> true false true true true false
console.log(typeof a)
>>> 'object'
我们可以看到new一个String,出来的是对象,而直接字面量赋值和工厂模式出来的都是字符串。但是根据我们上面的分析大小相对固定可预期的即便是对象也可以存储在栈内存的,比如null,为啥这个不是呢?再继续看
var a = new String('123')
var b = new String('123')
console.log(a==b, a===b)
>>> false false
很明显,如果a,b是存储在栈内存中的话,两者应该是明显相等的,就像null === null是true一样,但结果两者并不相等,说明两者都是存储在堆内存中的,指针指向不一致。
说到这里,再去想一想我们常说的值类型和引用类型其实说的就是栈内存变量和堆内存变量,再想想值传递和引用传递、深拷贝和浅拷贝,都是围绕堆栈内存展开的,一个是处理值,一个是处理指针。
内存分配和垃圾回收
一般来说栈内存线性有序存储,容量小,系统分配效率高。而堆内存首先要在堆内存新分配存储区域,之后又要把指针存储到栈内存中,效率相对就要低一些了。
垃圾回收方面,栈内存变量基本上用完就回收了,而推内存中的变量因为存在很多不确定的引用,只有当所有调用的变量全部销毁之后才能回收。
继续往下思考的话,其中还有很多的东西需要去学习,今天先到这里,后续再来补充。
话说~NaN会不会也是存储在堆内存中的呢?大家想想吧,欢迎大家来一起讨论讨论~文中如有错误欢迎指出~
--参考木子墨的博客

