语言模型
语言模型:是用来计算一个句子产生概率的概率模型,即P(w_1,w_2,w_3…w_m),m表示词的总个数。根据贝叶斯公式:P(w_1,w_2,w_3 … w_m) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2) … P(w_m|w_1,w_2 … w_{m-1})。
N-Gram:
它利用马尔科夫假设,认为句子中每个单词只与其前n–1个单词有关,即假设产生w_m这个词的条件概率只依赖于前n–1个词,则有P(w_m|w_1,w_2…w_{m-1}) = P(w_m|w_{m-n+1},w_{m-n+2} … w_{m-1})。其中n越大,模型可区别性越强,n越小,模型可靠性越高。
N-Gram语言模型简单有效,但是它只考虑了词的位置关系,没有考虑词之间的相似度,词语法和词语义,并且还存在数据稀疏的问题,所以后来,又逐渐提出更多的语言模型,例如Class-based ngram model,topic-based ngram model,cache-based ngram model,skipping ngram model,指数语言模型(最大熵模型,条件随机域模型)等。
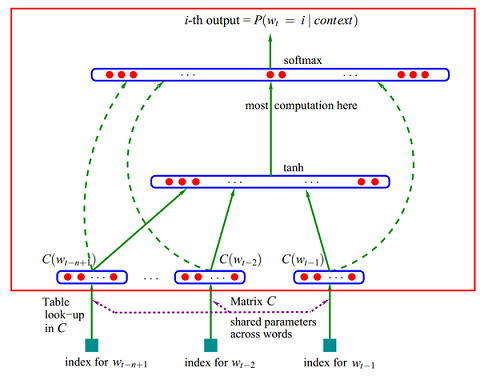
A Neural Probabilistic Language Model(神经网络语言模型)--ffnnlm:
它也是基于N-Gram的,首先将每个单词w_{m-n+1},w_{m-n+2} … w_{m-1}映射到词向量空间,再把各个单词的词向量组合成一个更大的向量作为神经网络输入,输出是P(w_m)。
解决了传统n-gram的两个缺陷:(1)词语之间的相似性可以通过词向量来体现;(2)自带平滑功能。
state-of-the-art--rnnlm:
循环神经网络相比于传统前馈神经网络,其特点是:可以存在有向环,将上一次的输出作为本次的输入。而rnnlm和ffnnlm的最大区别是:ffnnmm要求输入的上下文是固定长度的,也就是说n-gram中的 n 要求是个固定值,而rnnlm不限制上下文的长度,可以真正充分地利用所有上文信息来预测下一个词,本次预测的中间隐层信息(例如下图中的context信息)可以在下一次预测里循环使用。
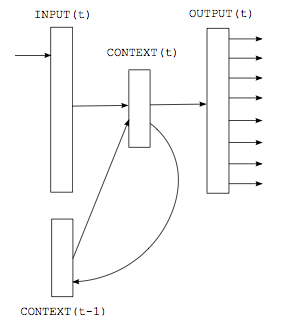
如上图所示,这是一个最简单的rnnlm,神经网络分为三层,第一层是输入层,第二层是隐藏层(也叫context层),第三层输出层。 假设当前是t时刻,则分三步来预测P(w_m):
- 单词w_{m-1}映射到词向量,记作input(t)
- 连接上一次训练的隐藏层context(t–1),经过sigmoid function,生成当前t时刻的context(t)
- 利用softmax function,预测P(w_m)
基于RNN的language model利用BPTT(BackPropagation through time)算法比较难于训练,原因就是深度神经网络里比较普遍的vanishing gradient问题(在RNN里,梯度计算随时间成指数倍增长或衰减,称之为Exponential Error Decay)。所以后来又提出基于LSTM(Long short term memory)的language model,LSTM也是一种RNN网络,LSTM通过网络结构的修改,从而避免vanishing gradient问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号