TensorFlow架构与设计:概述
TensorFlow是什么?
TensorFlow基于数据流图,用于大规模分布式数值计算的开源框架。节点表示某种抽象的计算,边表示节点之间相互联系的张量。

TensorFlow支持各种异构的平台,支持多CPU/GPU,服务器,移动设备,具有良好的跨平台的特性;TensorFlow架构灵活,能够支持各种网络模型,具有良好的通用性;此外,TensorFlow架构具有良好的可扩展性,对OP的扩展支持,Kernel特化方面表现出众。
系统概述
TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
- 前端系统:提供编程模型,负责构造计算图;
- 后端系统:提供运行时环境,负责执行计算图。

如上图所示,重点关注系统中如下4个基本组件,它们是系统分布式运行机制的核心。
Client
Client是前端系统的主要组成部分,它是一个支持多语言的编程环境。它提供基于计算图的编程模型,方便用户构造各种复杂的计算图,实现各种形式的模型设计。
Client通过Session为桥梁,连接TensorFlow后端的「运行时」,并启动计算图的执行过程。
Distributed Master
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching(需要的到的参数,例a=1+2,a就是feching)参数,从计算图中反向遍历,找到所依赖的「最小子图」。
然后,Distributed Master负责将该「子图」再次分裂为多个「子图片段」(有多少个Feching参数,就分裂为多少个子图),以便在不同的进程和设备上运行这些「子图片段」。
最后,Distributed Master将这些「子图片段」派发给Work Service,有多少个子图,就有多少个WorkService;随后Work Service启动「子图片段」的执行过程。
Worker Service
对于每以个任务,TensorFlow都将启动一个Worker Service。Worker Service将按照计算图中节点之间的依赖关系,根据当前的可用的硬件环境(GPU/CPU),调用OP的Kernel实现完成OP的运算(一种典型的多态实现技术)。
另外,Worker Service还要负责将OP运算的结果发送到其他的Work Service;或者接受来自其他Worker Service发送给它的OP运算的结果。
Kernel Implements
Kernel是OP在某种硬件设备的特定实现,它负责执行OP的运算。
组件交互
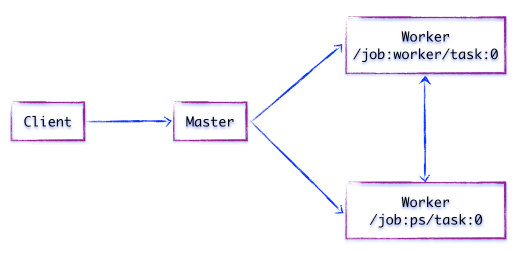
如上图所示,假设存在两个任务:
/job:ps/task:0: 负责模型参数的存储和更新/job:worker/task:0: 负责模型的训练或推理
客户端
Client基于TensorFlow的编程接口,构造计算图。目前,TensorFlow主流支持Python和C++的编程接口,并对其他编程语言接口的支持日益完善。
此时,TensorFlow并未执行任何计算。直至建立Session会话,并以Session为桥梁,建立Client与后端运行时的通道,将Protobuf格式的GraphDef发送至Distributed Master。
也就是说,当Client对OP结果进行求值时,将触发Distributed Master的计算图的执行过程。
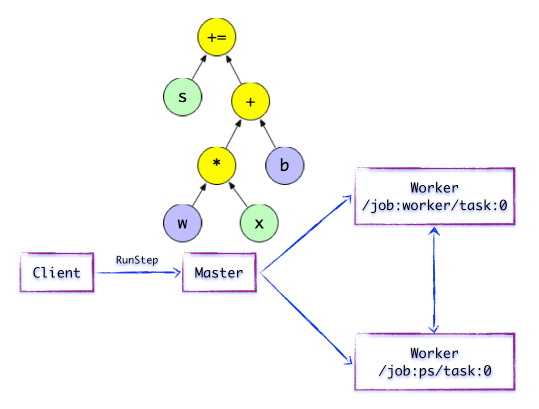
如下图所示,Client构建了一个简单计算图。它首先将w与x进行矩阵相乘,再与截距b按位相加,最后更新至s。

Distributed Master
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的最小子图。
然后Distributed Master负责将该子图再次分裂为多个「子图片段」,以便在不同的进程和设备上运行这些「子图片段」。
最后,Distributed Master将这些图片段派发给Work Service。随后Work Service启动「本地子图」的执行过程。
Distributed Master将会缓存「子图片段」,以便后续执行过程重复使用这些「子图片段」,避免重复计算。
如上图所示,Distributed Master开始执行计算子图。在执行之前,Distributed Master会实施一系列优化技术,例如「公共表达式消除」,「常量折叠」等。随后,Distributed Master负责任务集的协同,执行优化后的计算子图。
子图片段

如上图所示,存在一种合理的「子图片段」划分算法。Distributed Master将模型参数相关的OP进行分组,并放置在PS任务上。其他OP则划分为另外一组,放置在Worker任务上执行。
SEND/RECV节点
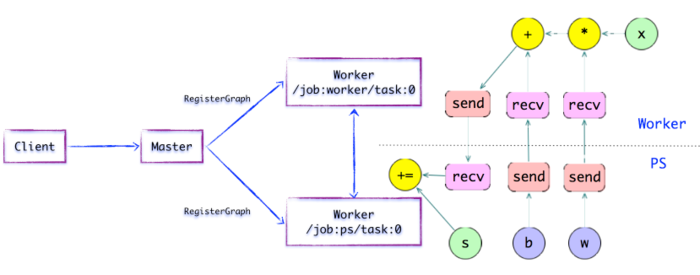
如上图所示,如果计算图的边被任务节点分割,Distributed Master将负责将该边进行分裂,在两个分布式任务之间插入SEND和RECV节点,实现数据的传递。
随后,Distributed Master将「子图片段」派发给相应的任务中执行,在Worker Service成为「本地子图」,它负责执行该子图的上的OP。
Worker Service
对于每个任务,都将存在相应的Worker Service,它主要负责如下3个方面的职责:
- 处理来自
Master的请求; - 调度
OP的Kernel实现,执行本地子图; - 协同任务之间的数据通信。

Worker Service派发OP到本地设备,执行Kernel的特定实现。它将尽最大可能地利用多CPU/GPU的处理能力,并发地执行Kernel实现。
另外,TensorFlow根据设备类型,对于设备间的SEND/RECV节点进行特化实现:
- 使用
cudaMemcpyAsync的API实现本地CPU与GPU设备的数据传输; - 对于本地的
GPU之间则使用端到端的DMA,避免了跨host CPU昂贵的拷贝过程。
对于任务之间的数据传递,TensorFlow支持多协议,主要包括:
- gRPC over TCP
- RDMA over Converged Ethernet
Kernel Implements
TensorFlow的运行时包含200多个标准的OP,包括数值计算,多维数组操作,控制流,状态管理等。每一个OP根据设备类型都会存在一个优化了的Kernel实现。在运行时,运行时根据本地设备的类型,为OP选择特定的Kernel实现,完成该OP的计算。
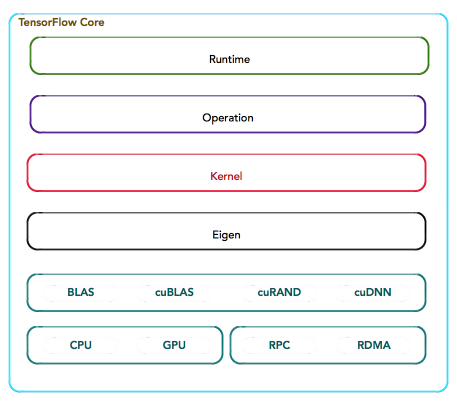
其中,大多数Kernel基于Eigen::Tensor实现。Eigen::Tensor是一个使用C++模板技术,为多核CPU/GPU生成高效的并发代码。但是,TensorFlow也可以灵活地直接使用cuDNN实现更高效的Kernel。
此外,TensorFlow实现了矢量化技术,使得在移动设备,及其满足高吞吐量,以数据为中心的应用需求,实现更高效的推理。
如果对于复合OP的子计算过程很难表示,或执行效率低下,TensorFlow甚至支持更高效的Kernle实现的注册,其扩展性表现相当优越。
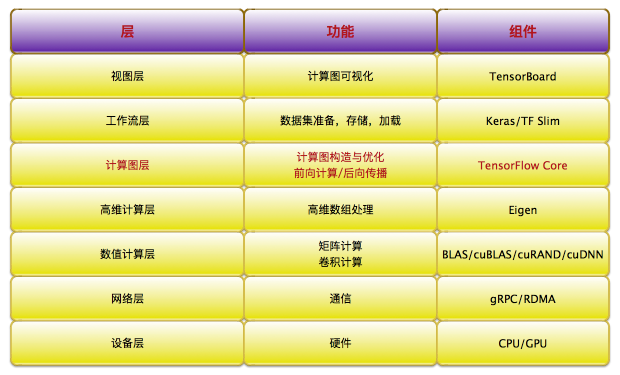
技术栈
最后,按照TensorFlow的软件层次,通过一张表格罗列TensorFlow的技术栈,以便更清晰地对上述内容做一个简单回顾。