交叉熵理解
熵
考虑另一个问题,对于某个事件,有n种可能性,每一种可能性都有一个概率p(xi)
这样就可以计算出某一种可能性的信息量。举一个例子,假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量
| 序号 | 事件 | 概率p | 信息量I |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | -log(p(A))=0.36 |
| B | 电脑无法开机 | 0.2 | -log(p(B))=1.61 |
| C | 电脑爆炸了 | 0.1 | -log(p(C))=2.30 |
我们现在有了信息量的定义,而熵用来表示所有信息量的期望,即:

其中n代表所有的n种可能性,所以上面的问题结果就是

然而有一类比较特殊的问题,比如投掷硬币只有两种可能,字朝上或花朝上。买彩票只有两种可能,中奖或不中奖。我们称之为0-1分布问题(二项分布的特例),对于这类问题,熵的计算方法可以简化为如下算式:
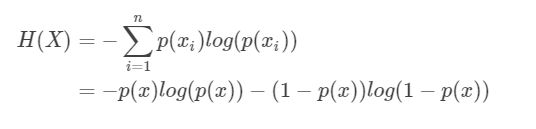
相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1] 直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
KL散度的计算公式:
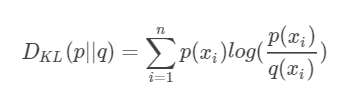 n为事件的所有可能性。DKL的值越小,表示Q分布和P分布越接近
n为事件的所有可能性。DKL的值越小,表示Q分布和P分布越接近
交叉熵
对式上述变形可以得到:
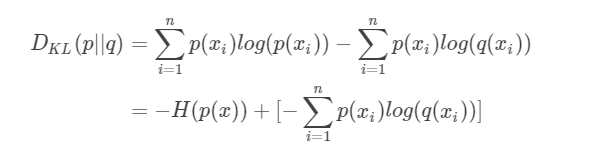
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
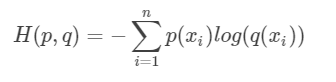
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,由于KL散度中的前一部分−H(y)(熵)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
tensorflow实现交叉熵
def _cross_entropy(y, y_pred): """ calculate cross entropy :param y: true label, one hot :param y_pred: predicted :return: loss """ loss = -tf.reduce_mean(y * tf.log(tf.clip_by_value(y_pred, 1e-5, 1.0))) # tf.clip_by_value, prevent loss Nan return loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号