
(如何根治HTTP请求响应中的乱码)tomcat中的字符集问题,测试以及总结
HTTP服务器的通常作用可以理解成,接收来自浏览器的请求,读取其中的信息,并返回http格式的数据
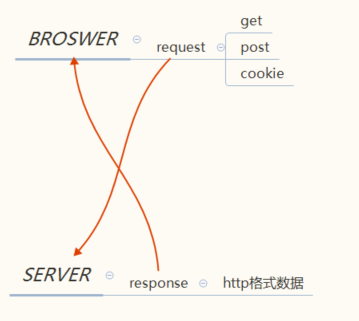
其中,浏览器发送的数据主要以三种形式传递,get方式提交的参数,post方式的参数,以及cookie中携带的参数三类
而服务器端,生成http返回数据的形式主要有3种
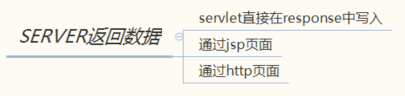
其中,JSP在本质上与Servlet无异,一般可认为JSP在Servlet的基础上,加上了Html的框架,不过如果把JSP代码中的HTML代码去掉,两者基本就是一个东西了。
整个流程中,需要注意到字符集问题的地方,从动作而言,分为四步:

字符集问题出现在信息从一级流通到另一级的过程中,也就是这4个动作当中。要规避字符集问题,需要了解四个动作中,分别的,其使用的字符集的确认方式。
也就是说,
浏览器发送数据时,采用哪种字符集?
服务器解析浏览器发送的数据时,采用哪种字符集?
服务器在返回数据时,使用哪种字符集?
浏览器解析服务器返回的数据时,使用哪种字符集?
这么四个问题。
以下就这四个问题展开讨论
1、浏览器发送数据时,采用哪种字符集?
浏览器发起一个请求,需要通过URL访问
根据形式分为,直接在浏览器中输入URL访问,以及通过链接跳转访问,通过链接跳转访问则包括form表单以及超链接两种形式

而无论哪种形式,最终浏览器都会将其包装成HTTP格式进行访问,也即如下格式:
POST /MyTestProject6/Test_Servlet_002 HTTP/1.1
Host: localhost
Connection: keep-alive
Content-Length: 39
Cache-Control: max-age=0
Origin: http://localhost
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://localhost/MyTestProject6/Test_003.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: JSESSIONID=1420F43C4B8259D6FCCD46E87B095DB3; _ga=GA1.1.1822121407.1535547634
request信息中,并不会指定编码集。
那参数在传递过程中,对中文进行编码的格式如何确定呢?
首先将浏览器访问服务器的动作分为两种
1、在URL栏中直接输入URL访问
2、在已经呈现的HTML页面中跳转
直接在URL栏中输入的中文,会以浏览器默认的编码集进行编码。

如此去访问,火狐浏览器的结果是:
chrome浏览器的结果也是:

而其他的的访问,也即是由页面生成的URL,其内容的编码格式取决于该页面在编码时使用的字符集
一定程度上,也就是页面中的<meta charset="XXX">标签,该标签标注了该页面的编码格式
(不过当然没这么简单,之后会在第四部分详细说明)
当页面中<meta charset="XXX">标签缺省时。浏览器会采用默认字符集对页面进行编译,这也是由这个页面所产生的URL在生成request时所采用的字符集。
总结:浏览器发送数据时,采用哪种字符集?
1、直接输入URL的,依浏览器(chrome:utf-8,火狐:gbk)
2、页面采用何种字符集编码,则发送数据时采用何种字符集
3、页面未指定字符集时,chrome和火狐都默认使用GKB进行编码
2、服务器解析浏览器发送的数据时,使用何种字符集?
上文提到,request中并不会携带关于request的内容由哪种字符集信息。
因此,服务器在解析数据时,随缘。。。
比如某个用户在URL中自己手动输入中文参数,可能会影响。
但大多数URL都由服务器自身的页面发出,统一字符集的话,一般不会受到字符集问题的影响。
以下,以TOMCAT9为例,阐述如何应对GET请求,POST请求的处理方式。
总所周知,一条URL请求,会由浏览器包装成HTTP格式,再发送到服务器,因此服务器接受到的数据是一个数据包,而非单单一个URL字符串。
其中访问路径信息path在第一行的中间,并且以get形式提交的数据显示在了path当中。
tomcat7以上的版本,对于path的内容,会自动用utf-8去解码。其也可以在server.xml中去配置。
而tomcat7以及以下的版本,默认的字符集依然是iso-8859-1。因此需要通过对应的格式去decode。
不过TOMCAT9自动默认UTF-8也有不好的地方,get请求的参数默认就直接UTF-8编码了,也就是无论GBK还是UTF-8发送过来都成了UTF-8。也就无法读取GET里面的内容了
而POST请求,TOMCAT并不会自动解码,而默认的字符集是iso-8859-1,只需要设置其为对应的字符集即可,也就是
request.setCharacterEncoding("XXX");
此外,COOKIE数据也是浏览器在访问服务器时会携带的,但COOKIE数据不能包含中文(使用iso-8859-1编码)
而COOKIE数据本身就是服务器原先自己添加进去的,因此需要按照添加时转换所使用的字符集去解析。
总结:服务器解析浏览器发送的数据时,使用何种字符集?
1、首先参照上一节中描述的get数据和post数据在浏览器端编码的规则
2、get数据一般默认iso-8859-1,tomcat7以上get请求默认utf-8,server.xml可以设置默认读取方式,默认GBK但传入UTF-8会很尴尬
3、post数据默认iso-8859-1,通过设置request.setCharacterEncoding("XXX")可以修改(在每次请求传入时),也可以将这一步写入filter中。
4、COOKIE数据默认iso-8859-1,按照服务器之前存入COOKIE时的字符集去解码
3、服务器返回数据时,使用何种字符集?
服务器返回http数据时,一般有三种方式。

不过如果最终返回的是页面,三种方式最终返回的数据,在浏览器看来是没啥区别的。
(1)servlet
首先测试servlet,仅写入这么一条service的内容,不做其他设置
response.getWriter().append("Served at: ").append(request.getContextPath());
查看浏览器端接收的数据中response的head
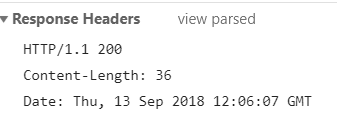
结合页面显示效果,不难发现
如果未设置contentType,浏览器会使用默认的iso-8859-1进行解析
如果设置了contentType,比如:
response.setContentType("text/html;charset=utf-8");
response.getWriter().append("测试直接传输一个中文");
则浏览器会使用对应的字符集进行解析,也就是参照contentType中设置的charset
HTTP/1.1 200 Content-Type: text/html;charset=utf-8 Content-Length: 104 Date: Fri, 14 Sep 2018 03:14:30 GMT
BUT,需要注意的是,最终传输的数据的字符集需要与此时设置的字符集保持一致。
不一致的情况包括而不限于:
比如上述代码的.java文件字符集是其他的,比如
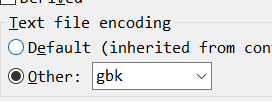
而代码中设置的字符集为UTF-8,因此最终页面会乱码

这也是JSP跟HTTP页面中需要注意的
(2)html页面
在HTML页面中,主要通过<meta charset="xxx"> 来控制页面使用的字符集。
<!DOCTYPE html> <html> <head> <meta charset="gbk"> <title>Insert title here</title> </head> <body> 中文 </body> </html>
HTTP/1.1 200
Accept-Ranges: bytes
ETag: W/"300-1536840847318"
Last-Modified: Thu, 13 Sep 2018 12:14:07 GMT
Content-Type: text/html
Content-Length: 300
Date: Thu, 13 Sep 2018 12:14:10 GMT
不难看出,在访问HTTP页面时,其response的头中,根本没有标注其所使用的字符集
可以理解成,服务器在响应返回html页面时,并不会对其内容进行解析,而是直接发送过去,因此服务器也不知道该html的字符集
而浏览器在接收到response相应之后,也是在读取response的content部分中的meta标签才确定字符集。
HTML文件同样需要注意,最终传输的数据的字符集需要与此时设置的字符集保持一致。
缺省时,chrome和火狐都默认使用gkb编码(应对contentType为text/html)
(3)JSP页面
在JSP文件中,可以设置的字符集格式文件包括pageEncoding,contentType,以及其html代码中的meta标签。
不过contentType可以缺省,contentType缺省时服务器会根据pageEncoding设置contentType中的charset。
比如:
<%@page pageEncoding="utf-8"%> 这是一个中文
HTTP/1.1 200
Content-Type: text/html;charset=utf-8
Content-Length: 22
Date: Thu, 13 Sep 2018 12:22:49 GMT
而如果在已经有pageEncoding的情况下再去设置contentType的charset,后者会覆盖前者,比如:
<%@page contentType="text/html;charset=gbk" pageEncoding="utf-8"%> 这是一个中文
HTTP/1.1 200
Content-Type: text/html;charset=gbk
Content-Length: 16
Date: Thu, 13 Sep 2018 12:24:04 GMT
当contentType设置了时,pageEncoding可以缺省,此时会默认使用contentType中设置的字符集作为pageEncoding的字符集。
此时依然需要注意,最终传输的数据的字符集需要与此时设置的字符集保持一致。
但此时,如果字符集冲突,其冲突是在JSP的编译阶段,而不是在浏览器上的显示阶段。
比如,当我设置了pageEncoding,但是跟.jsp文件采用的字符集不同时,其结果是在编译而成的.java文件中就出现了乱码
比如

<%@page pageEncoding="utf-8"%> 这是个中文
则访问乱码

其.java文件中就已经出现了乱码
response.setContentType("text/html;charset=utf-8");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("���Ǹ�����\r\n");
当pageEncoding和contentType都缺省时,JSP编译器会很晕。。然后用iso-8859-1编码
总之!!JSP页面就是不用meta里面设置的字符集。。。
<%@page%> <!DOCTYPE html> <html> <head> <meta charset="gbk" /> <title>Insert title here</title> </head> <body>我是个中文 </body> </html>
因为JSP在编译过程中就在response的head中指定了字符集吖o(* ̄▽ ̄*)ブ

HTTP/1.1 200
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 136
Date: Thu, 13 Sep 2018 12:34:10 GMT
总结:服务器返回数据时,使用何种字符集?
1、servlet端需要设置contentType,注意与代码的编码文件格式保持一致,缺省时浏览器使用iso-8859-1。
2、html文件需要设置<meta charset>,注意与html文件的编码格式保持一致,缺省时浏览器使用gbk。
3、jsp文件需要设置contentType或pageEncoding,注意与jsp文件的编码格式保持一致,缺省时浏览器使用gbk,但JSP编译器会通过iso-8859-1去编译。
4、浏览器解析数据时,采用何种字符集
依照上文,大致能概括出浏览器在解析数据时使用的逻辑,以及不同charset设置的优先级和覆盖关系:
浏览器在解析时使用的字符集,依照response的head中的contentType中的charset参数。
当该参数缺省时,会去寻找文件中的<meta charset>标签。
都缺省时,使用浏览器默认字符集。
如果head中没有contentType,则使用iso-8859-1。
可以在servlet中测试如下:
ServerSocket ss = new ServerSocket(8081); while (true) { Socket s = ss.accept(); PrintWriter pw = new PrintWriter(s.getOutputStream()); pw.println("HTTP/1.1 200"); pw.println("Content-Type: text/html"); pw.println(); pw.println("<meta charset='utf-8'>"); pw.println("中文"); pw.flush(); s.close(); }
测试结果
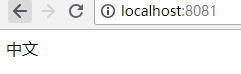

也就是这样子啦。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号