
有中心局域网集群爬虫
单机爬虫,在通过优先级队列合并下载队列和访问队列,通过统一的下载器去合并下载器以及访问器之后,其机构就变的非常简单。
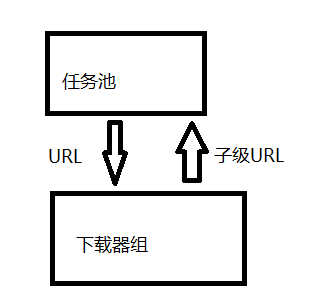
其启动代码也特别简单。
Status.url.add(Setting.url);
for (int i = 0; i < 30; i++) {
new DownloadThread().start();
}
中间还需要加入对访问失败的URL的处理单元,比如建立一个逻辑,访问失败的URL放回任务池中等待重新访问,当访问失败3次就保存到本地。
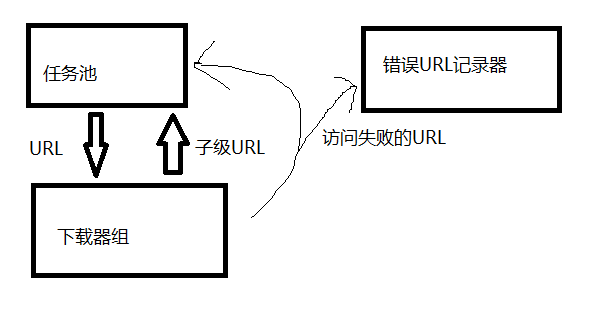
然而,单台计算机当作爬虫,其速度会受到宽带限制,以及服务器的访问速度限制,单台计算机的爬取速度有限。
那么,如何利用单机爬虫,进行改进,制作一个有中心的,利用局域网,结合局域网内IP的数量,提高爬取速度的有中心局域网集群爬虫呢?
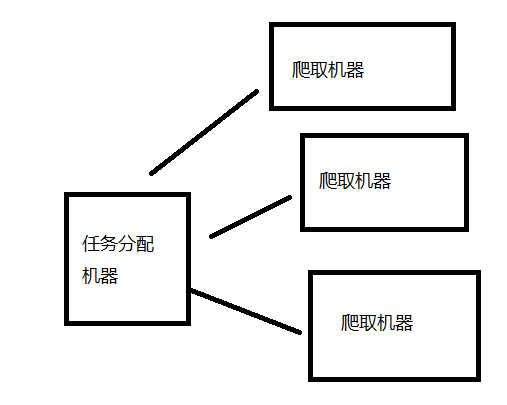
最简单的想法是,把一台机器当作任务分配中心,其他计算机当作爬取机器。也就是有一台机器单纯当作任务池以及错误URL记录器,而其他机器单纯当作下载器,用局域网连接替代原本的URL地址传递方式。
这时需要对原先的单机爬虫进行一些改进,比如把保存文件的操作,由原先下载器直接执行,改由任务池代替执行。
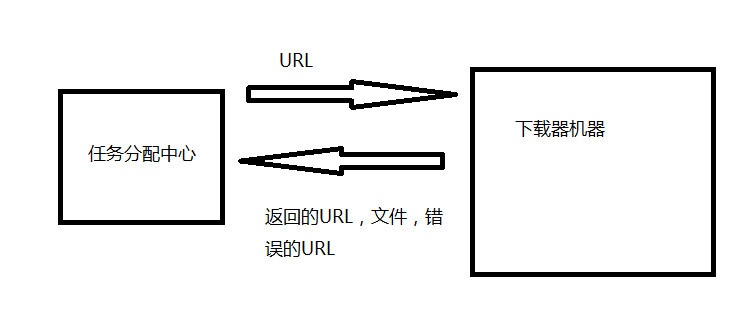
这样就能基本实现有中心局域网集群爬虫了,其业务场景类似工地上,工头指挥底下工人搬砖。
但这样的结构容错率不高,一旦任务分配中心出点故障,整个系统都无法执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号