
zookeeper笔记
前言
zookeeper作为一个分布式协调服务,可以用来进行配置管理,分布式锁,集群管理等。大多数情况下,我们都是用作分布式服务架构中的注册中心。日常开发中,zookeeper对我们来说完全是个黑盒子,但是还是需要了解其中一二的。
选举
生产环境上,为了保证稳定性,一般都是集群模式,由3个或者5个server组成集群,而集群中server有几种角色,分别为leader,follower,observer。
leader负责写和读请求,进行写操作时,会发Proposal(事务)到Server,其他的Server对该Proposal进行Vote(投票),超过半数通过,则发出Commit 消息其他server,要求将上个Proposal提交。
follower负责读请求和转发写请求到leader,参与投票。
observer负责读请求和转发写请求到leader,不参与投票。
那么leader是怎么选举出来的,以3个server集群为例,分别为A,B,C服务器,在依次启动的时候,ABC的状态都为LOOKING。
先来看看A服务器是怎样的。
1.因为是初始状态,A会给自己投票,这时事务id(ZXID)为0,假设A的服务器id为1,那么A服务器将会向BC发出自己的投票vote(1,0),然后等待BC的投票。
2.这时,A收到B的投票(2,0),A会比较ZXID,ZXID大的胜出,因为都是0,所以下一步比较服务器id,B的id较大,A更新自己投票为(2,0),再次向其他BC发出投票,此时统计投票,发现AB服务器都选择B为leader,超过半数,所以更改自己状态为FOLLOWING。
B服务器
1.B发出(2,0),然后等待AC的投票。
2.B收到A发来的投票(2,0),统计投票后得到结果,将自己状态改为LEADING。
C服务器
1.启动后发现集群中已经有leader,将自己状态改成FOLLOWING。
此时选举结束,当然还有一种情况是,B服务器宕机了,这时会进行重新选举,过程和上面差不多。
上面提到无论选举还是写的投票都要过半数通过才行,其实就是为了防止脑裂情况。试试看,假如C和AB网络通信出现问题,C把自己选举为leader,而AB则以B为leader,一个集群中存在两个leader,会造成数据一致性问题。
注册中心
zookeeper提供的功能本质上相当于文件系统+监控机制,类似树的结构,由znode节点组成,节点类型分别为
-
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
-
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
另外,Watcher(事件监听器)可以允许客户端对特定节点进行监控,节点发生变化(数据改变、被删除、子目录节点增加删除)时,通知客户端。
以dubbo为例,下面是dubbo官方图
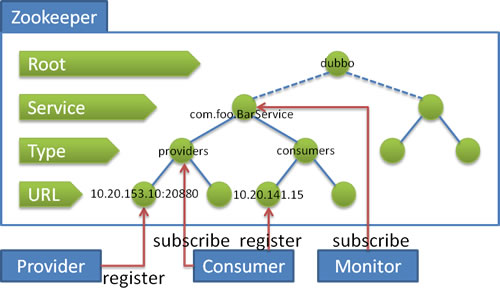
服务提供者Provider在providers节点下面新增一个临时节点,写入自己的url地址,当Provider下线或者宕机时,zookeeper会删除相应的节点。
服务消费者consumer则在consumers节点下面新增临时节点,写入自己的url地址,并且对providers节点进行监控,如果发生数据变化,重新拉取providers节点下面的数据。
实质上dobbo是利用zookeeper的临时节点和监控机制进行服务的发布和订阅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号