
JAVA基础
Colletion
常见的集合框架如下图
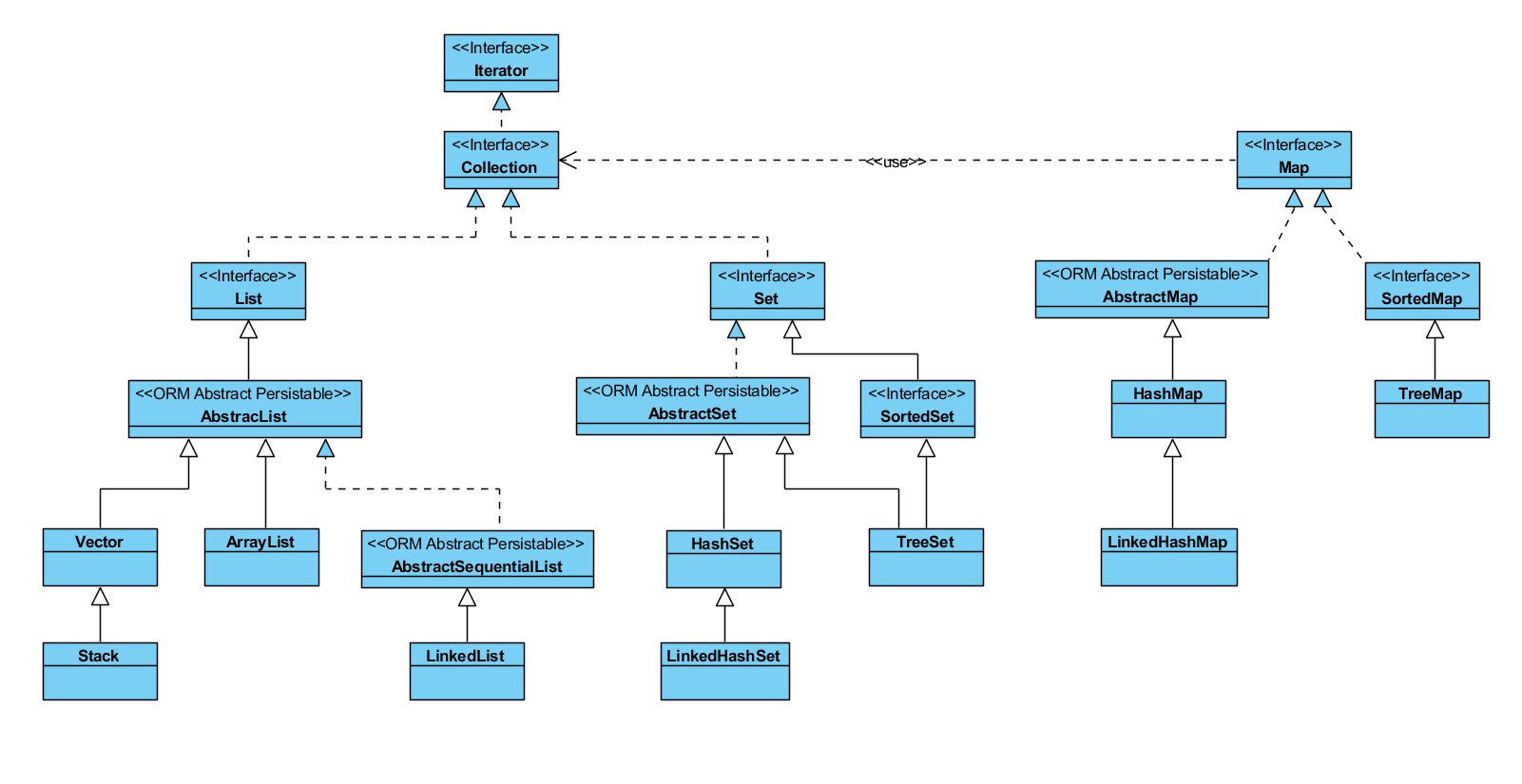
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 2 种子类型,List和Set ,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
| List | ArrayList | 该类也是实现了List的接口,实现了基于动态数组的数据结构,随机访问和遍历元素速度快。插入时较低,因为可能要移动元素 |
| LinkedList | 该类实现了List接口,允许有null(空)元素。主要用于创建链表数据结构,LinkedList 查找效率低,因为要移动指针。插入删除速度快。 | |
| Set | HashSet | 该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。是采用hash表来实现的。其中的元素没有按顺序排列,add()、remove()以及contains()等方法都是复杂度为O(1)的方法。 |
| LinkedHashSet | 介于HashSet和TreeSet之间,使用哈希表和链接列表实现。新增和删除复杂度为O(1)。 | |
| TreeSet | 构造函数可以传入Comparator,也可以元素实现Comparable.是采用树结构实现(红黑树算法)。元素是按顺序进行排列,但是add()、remove()以及contains()等方法都是复杂度为O(log (n))的方法。它还提供了一些方法来处理排序的set,如first(), last(), headSet(), tailSet()等等。 | |
| Map | HashMap |
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 用于插入、删除和定位元素 |
| TreeMap |
使用二叉树结构存储。Comparator为空时,使用默认比较器。 用于按自然顺序或自定义顺序遍历键 |
|
| LinkedHashMap |
使用元素的自然顺序对元素进行排序。HashMap的基础上加上双向链表结构维护元素顺序。 用于输出的顺序和输入的相同。 |
如果觉得眼花缭乱记不住这么多类区别,那么只需要理解他们里面的数据结构也可以更清晰区别开来
| 堆栈 | 先进后出 |
| 队列 | 先进先出 |
| 数组 |
查找快:通过索引。 |
| 链表 |
查找慢:移动指针,依次向后查找指定元素 增删快:简单来说,删除一个指针,增加两个指针 |
| 哈希表 | 底层也是数组结构,存放位置不是根据有序的索引,而是通过哈希算法计算出来 |
| 红黑树 | 查找时间复杂度logn,删除和新增需要做树平衡操作 |
Exception
Java中异常的层次结构以及一些常见的异常,如图

主要分为三大类异常:
1.Error:用来指示运行时环境发生的错误,如JVM 内存溢出。
2.Exception:检查性异常,编译时就需要处理的异常,代码上需要做响应的处理
3.RuntimeException及子类:运行时异常,运行时发生的异常,代码上无需做特别处理
举个例子
public class MyException extends Exception{ } public class MyRuntimeException extends RuntimeException{ } void throwException() throws Exception { throw new MyException(); } void throwRuntimeException() throws RuntimeException { throw new MyRuntimeException(); } Integer MyTest(){ //throwRuntimeException(); //不需要try catch try { throwException(); return 1; } catch (Exception ex) { return 2; }finally { return 3; } }
在上面代码中,MyException ,MyRuntimeException分别继承Exception,RuntimeException,用关键字throws声明方法,表示可能会抛出此异常。最终在MyTest方法上,需要对throwException作异常处理,否则编译不过,而throwRuntimeException不需要。
另外,值得一提的是。在mytest中最终return 3的,因为编译后的代码是这样的
Integer MyTest() { try { this.throwException(); Integer var1 = 1; } catch (Exception var6) { Integer var2 = 2; } finally { return 3; } }
Reflection
反射是一种动态创建对象和调用其方法字段注解等元数据的技术,可以降低系统的耦合度,相当于取得root权限,可以破坏原来的访问权限,调用其private方法。反射的使用上一般会用到这四个类型,Class,Constructor,Field,Method。
public class Calculator { public Calculator() { type = 1; } public Calculator(Integer t) { type = t; } private Integer type; public Integer plus(Integer num1, Integer num2) { return num1 + num2; } public Integer minus(Integer num1, Integer num2) { return num1 - num2; } } void reflectionCaluator() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException, ClassNotFoundException { //根据类全限定名称获取class类型 Class myCalculator = Class.forName("Calculator"); System.out.println(myCalculator.getName()); //遍历构造函数 Constructor[] constructors = myCalculator.getConstructors(); for (Constructor con : constructors) { System.out.println("构造函数:" + con.toString()); } //遍历所有方法 Method[] methods = myCalculator.getDeclaredMethods(); for (Method method : methods) { System.out.println("方法:" + method.toString()); } //遍历所有字段 Field[] fields = myCalculator.getDeclaredFields(); for (Field field : fields) { System.out.println("字段:" + field.getName()); } //实例化对象,执行方法 Object obj = myCalculator.getConstructor().newInstance(); Method plusMethod = myCalculator.getDeclaredMethod("plus", Integer.class, Integer.class); Object plusResult = plusMethod.invoke(obj, 1, 2); System.out.println("方法执行结果:" + plusResult); }
上面代码定义了Calculator类,简单演示了从字符串实例化Calculator对象到调用plus方法的过程。反射技术在java框架中有广泛应用,比较复杂的大型应用实例有spring框架的ioc,mybaits,动态代理等。
类加载
上面反射的例子其实就是一个类加载到实例化的过程,类加载器是有几种的
1.启动类加载器,Bootstrap ClassLoader,加载JAVA_HOME\lib,或者被-Xbootclasspath参数限定的类
2.扩展类加载器,Extension ClassLoader,加载\lib\ext,或者被java.ext.dirs系统变量指定的类
3.应用程序类加载器,Application ClassLoader,加载ClassPath中的类库
4.自定义类加载器,通过继承ClassLoader实现,一般是加载我们的自定义类
类加载采用的是双亲委派模型,即所有类加载请求都是由上到下加载,例如Bootstrap 在自己的范围找不到就委派下面的Extension 加载。
一个类的加载过程则如图
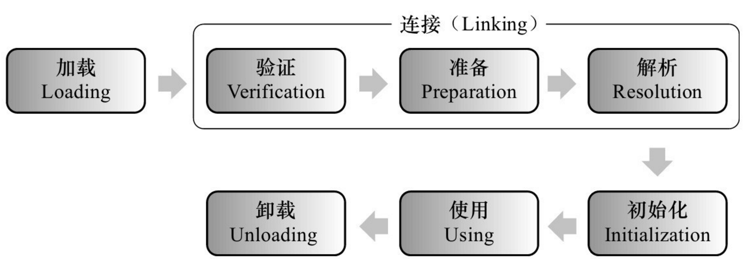
public class Calculator { static { i=1; } static int i=2; public static int j=1; public static final int k=1; }
结合上面过程,再看看这段代码。
1.在准备阶段会在方法区给类变量分配内存并设置初始值,也就是图中i,j,k,这个阶段的结果是只有k=1,其他的都是0。因为加上final关键字后,会被认为是常量,所以准备阶段就赋值了。
2.在初始化阶段(new,反射,调用静态字段或者方法),会按代码的自然顺序执行初始化,所以i的值是2。如果i=2放到static{}前面,那么i最终是1。
泛型
泛型在日常开发中有广泛应用,为什么需要引用泛型?泛型可以保证编码阶段的类型安全,节省繁琐的类型转换代码。泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法
public interface GenericTest<T extends List<?>> { public T get(); } public class GenericTestImpl<T extends Object> implements GenericTest<List<?>> { private T key; public static <E> List<E> plus(E num1, E num2) { List<E> list = new ArrayList<>(); list.add(num1); list.add(num2); return list; } public void setKey(T t) { key = t; } public T getKey() { return key; } @Override public List<?> get() { return new ArrayList<String>(); } }
在上面代码中分别演示了泛型应用在接口,类和方法例子,其中T代表的是任意引用类型,如果加上extends Object就限制T必须是 Object的子类,另外还有泛型通配符?,用于使用别的泛型而又不限制类型的情景,当然也可以继续加extends限制。另外的限制关键字还有super,代表只接受T或者T的父类。
List<Integer> list = new ArrayList<>(); list.add(12); //这里直接添加会报错 //list.add("a"); Class clazz = list.getClass(); Method add = null; try { add = clazz.getDeclaredMethod("add", Object.class); add.invoke(list, "kl"); } catch (NoSuchMethodException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } //但是通过反射添加,是可以的 for (Object item : list) { System.out.println(item); } //list.stream().forEach(x->{ // System.out.println(x); //});
再看看上面的代码,使用泛型接口List<T>定义了List<Integer>,正常情况add方法只能添加整型,但是通过反射调用add却能够正常添加string类型。但是因为由于JVM泛型的擦除机制,只是在编译阶段检测类型安全,在运行阶段都都会擦除成object,所以也解释了一个问题,泛型不能用基本类型,因为不是继承object。另外再看看最后被注释的代码,如果执行这段代码会抛错类型转换失败的异常,那是因为将元素强制转回来Integer。
注解
其实注释和注解的含义差不多,都是解释某种事物。但是不同的地方在于,注释是给人看的,而注解是给系统看的。在编码层面上,注解就像一个特殊的接口。
@Retention(RetentionPolicy.SOURCE) @Target({ElementType.FIELD}) public @interface MySourceAnnotation{ String value() default "MySourceAnnotation"; } @Retention(RetentionPolicy.CLASS) @Target({ElementType.FIELD}) @interface MyClassAnnotation{ String value() default "MyClassAnnotation"; } @Retention(RetentionPolicy.RUNTIME) @Target({ElementType.METHOD, ElementType.TYPE}) @interface MyRuntimeAnnotation { String author() default "zilin"; String remark() default "类"; String value() default "MyRuntimeAnnotation"; }
上面这段代码演示如果自定义注解,列举了一些常见的用法
1.可以使用default关键字设置默认值
2.使用@Target限制注解的应用范围,如ElementType.TYPE,ElementType.METHOD,ElementType.FIELD
3.使用Retention规定注解的生命阶段,分别是SOURCE(只存在于源码,就是.java源文件),CLASS(只存在于编译后的class文件),RUNTIME(运行阶段,可以被反射读取到)
@MyRuntimeAnnotation(author = "test",remark = "备注1") public class MyAnnotationTest { @MyClassAnnotation() private String myClassFiled; @MySourceAnnotation() private String mySourceFiled; } void Annotation() { Class testClass = MyAnnotationTest.class; Annotation[] annotations = testClass.getAnnotations(); for (Annotation annotation : annotations) { System.out.println("类的注解"+annotation.toString()); } Field[] fields = testClass.getDeclaredFields(); for (Field field : fields) { Annotation[] fieldAnnotations = field.getAnnotations(); for (Annotation annotation:fieldAnnotations){ System.out.println("字段的注解"+annotation.toString()); } } }
由于只有MyRuntimeAnnotation的生命阶段为runtime,所有上面的代码得到的结果是
类的注解@MyRuntimeAnnotation(value=MyRuntimeAnnotation, remark=备注1, author=test)
线程安全
我们一直都在说线程安全,到底在说什么。线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,而要保证线程安全应该是满足三个核心要素。
原子性
原子性是指操作的不可切割,其表现在于对于共享变量的某些操作,应该是不可分的,必须连续完成。对于访问同一个状态的所有操作(包括该操作本身)来说,这个操作是一个以原子方式执行的操作。在java的内存模型中,只有几种操作是满足,read,load,assign,use,store,write,lock,unlock。
可见性
可见性是指,当一个线程修改了共享变量的值,其他线程能立即得到最新值。
有序性
是指程序在执行的时候,程序的代码执行顺序和语句的顺序是一致的。在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
static int num; void startAddIntTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { num++; } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(num); }
8465 8008 8671 7327 7608
上面那段代码执行5次的结果如上,不是我们期待的10000,也没有呈现出规律性。为什么会出现这样的结果,原因在于num++并不是一个原子操作,num=num+1,分成两步,第一是获取num的值,这个时候可能有别的线程修改num的值,这个时候还是会将旧值+1写回去,简单来说就是某个线程计算结果被别的线程覆盖了。
ThreadLocal
那我们来尝试一下如何解决这个问题,java中有一个叫ThreadLocal类,把他用上去看看
private static ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<>(); public void startAddThreadLocalIntegerTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { threadLocalInteger.set(0); for (int i = 0; i < 1000; i++) { threadLocalInteger.set(threadLocalInteger.get() + 1); } System.out.println(Thread.currentThread().getName()+"结果"+threadLocalInteger.get()); } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println("最终结果: "+threadLocalInteger.get()); }
这段代码运行的结果会是什么?结果如下
Thread-1结果1000
Thread-0结果1000
Thread-4结果1000
Thread-3结果1000
Thread-6结果1000
Thread-2结果1000
Thread-5结果1000
Thread-7结果1000
Thread-8结果1000
Thread-9结果1000
最终结果: null
最终得到结果为空,但是每个线程结果为1000,不是我们期望的10000,很明显ThreadLocal并不能解决我们对共享变量操作的需求,它本质上是实现线程对变量的隔离,相当于把变量作用域变成为当前线程。具体是如何实现的,下面是set方法的源码
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } ThreadLocalMap getMap(Thread t) { return t.threadLocals; }
从源码里看到,是先获取了当前线程的实例,再得到当前线程的ThreadLocalMap,如果没有再创建新的,然后再把当前的ThreadLocal实例作为key,set的值作为value存放。各个实例关系如下图
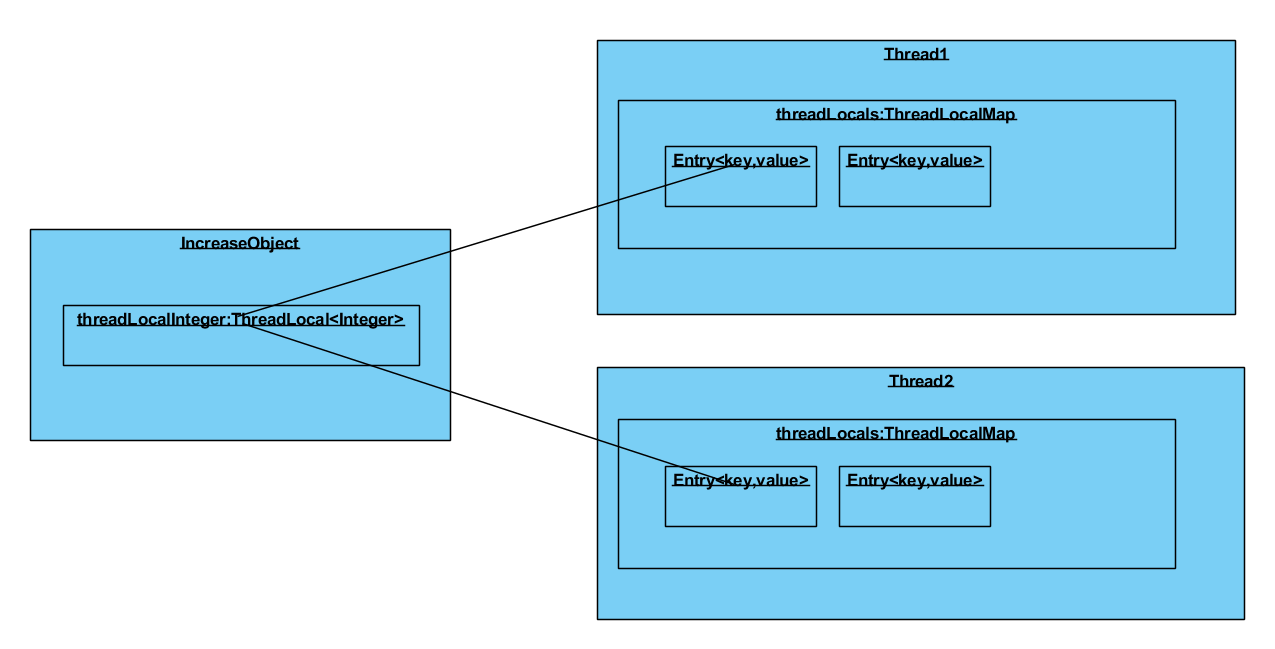
要注意的是,ThreadLocalMap里面的Entry源码如下,
static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
可以看得到Entry的key是弱引用的,如果上图中的IncreaseObject实例被GC了,那么下一个GC的将回收作为key的threadLocalInteger,但是Entry的实例还挂在Thread的ThreadLocalMap里面,value还在,却再也无法访问,造成内存泄露。
解决这个问题有2种办法,一种加上static关键字成为类的变量,另外一种是用完之后及时调用remove方法删除掉。
另外,刚才提到它是相当于将变量的作用域变成当前线程,生命周期最长可以跟线程一样,那么线程结束不就跟着一起回收了。是的,正常情况是这样,但是如果用线程池来管理的话,当前线程还是会回到线程池那里,并没有被回收,如果不注意的话可能会一直存在。
问题,如果key使用强引用会怎样。
synchronized
我们继续尝试用另外的方式,采用synchronized关键字看看
synchronized void addNum(){ num++; } void startSynchronizedAddIntTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { addNum(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(num); }
10000
输出结果为10000,符合我们的预期。那么为什么用了这个就能满足我们的需求了呢。
synchronized实际上是Java提供给我们的一种互斥同步手段,synchronized关键字经过编译后在同步块会分别生成monitorenter和monitorexit两个指令,这两个字节码需要一个引用类型的参数作为要锁定和解锁的对象。如果没有指定,那就根据修饰的是实体或者静态方法,获取响应的实例对象或者class对象作为锁对象。
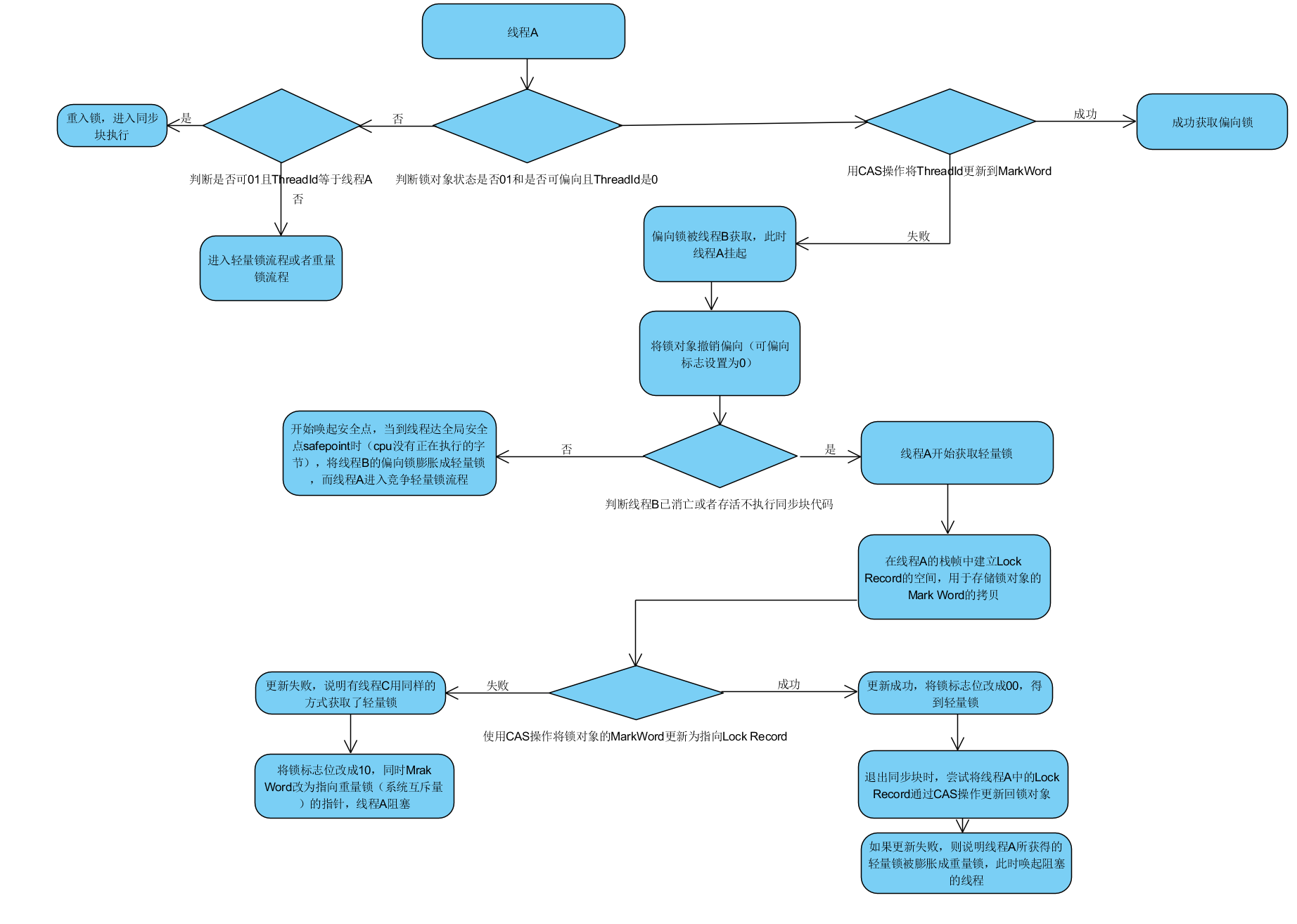
接下来我要说的是monitorenter和monitorexit这两个指令到底对锁对象做了什么。那要先从对象的内存布局图
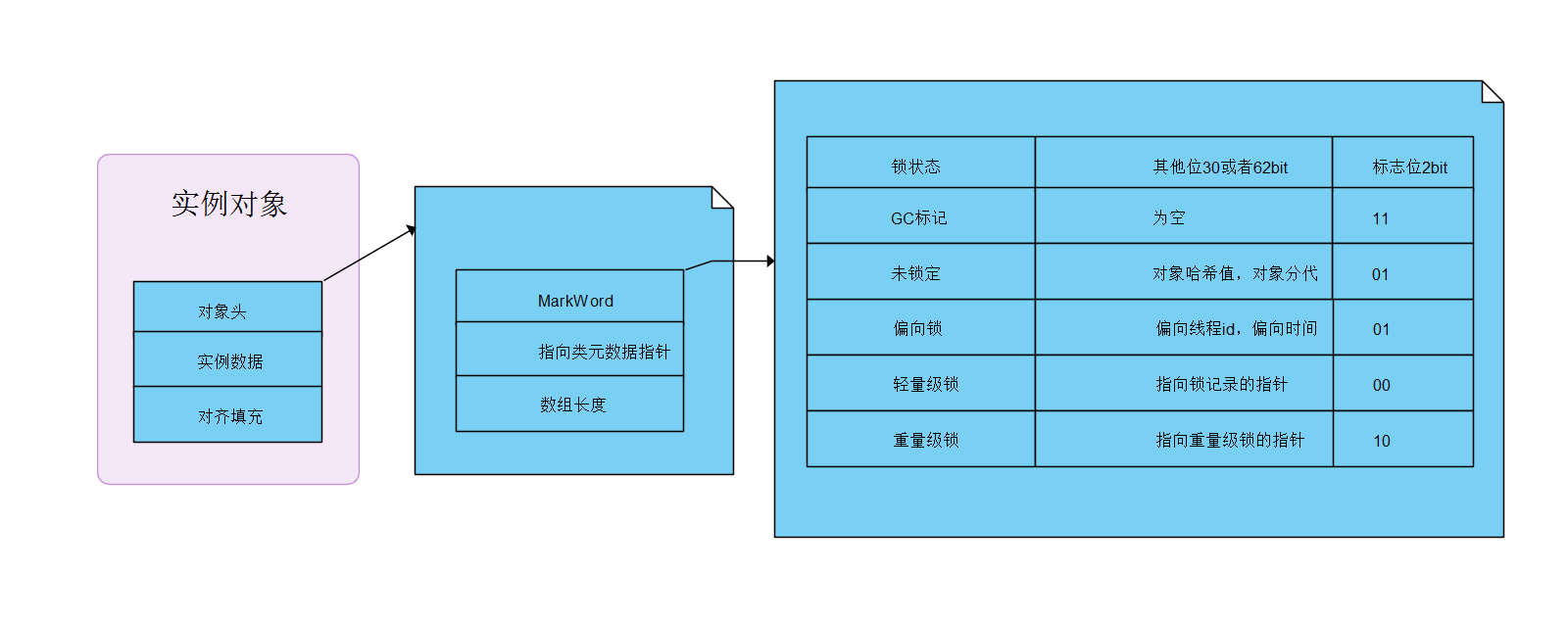
在jdk1.6版本对并发做了很多优化,例如自旋锁,锁消除,锁粗化,这些都是策略上优化。对于锁对象来说,无锁--偏向锁--轻量级锁--重量级锁这几种状态的转换才是真正意义上的锁。
自旋锁: 是一种非阻塞锁,也就是说,如果某线程需要获取锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取锁。
锁粗化:也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。
锁消除:通过运行时JIT编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护,通过逃逸分析也可以在线程本地Stack上进行对象空间的分配(同时还可以减少Heap上的垃圾收集开销)。
偏向锁: 来源是因为Hotsopt的作者研究发现大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程获得,在理想情况下,只需要做一次CAS操作,之后其他操作都不用做。
轻量级锁:如果说偏向锁是只允许一个线程获得锁,那么轻量级锁就是允许多个线程获得锁,但是只允许他们顺序拿锁,不允许出现竞争,也就是拿锁失败的情况,
重量锁: 就是使用操作系统层面的临界区(只允许一个线程访问) 互斥量(只允许一个线程访问,可以跨进程) 信号量(可以允许一定数量的线程访问)
锁转换状态如下
AtomicInteger
我们还可以用AtomicInteger类来实现,如下
static AtomicInteger atomicInteger = new AtomicInteger(0); void startAddAtomicIntegerTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { atomicInteger.incrementAndGet(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(atomicInteger.get()); }
10000
结果为10000,符合我们期望。那么,这里是怎么实现同步互斥的。先看incrementAndGet()的源码
public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; } public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; } public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
可以看到里面是最终还是依赖硬件层面CAS操作,利用循环不断做CAS操作,实质上是一种非阻塞同步,不挂起线程,在线程内部不断循环知道成功更新为止,实现了不覆盖别的线程计算结果。 如果是小于的判断?
ReentrantLock
另外我们还可以使用同样是JUC包中的ReentrantLock进行互斥同步操作,用法上也是比较简单,如下
ReentrantLock reentrantLock = new ReentrantLock(); void addLockNum() { reentrantLock.lock(); num++; reentrantLock.unlock(); } void startLockAddIntTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { addLockNum(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(num); }
和synchronized不一样的,ReentrantLock是api层面的,分别有公平锁和非公平锁的实现,公平锁比非公平锁主要多了一步判断是否头结点的下一个节点,我们还可以容易的看到源码,它的公平锁流程主要如下
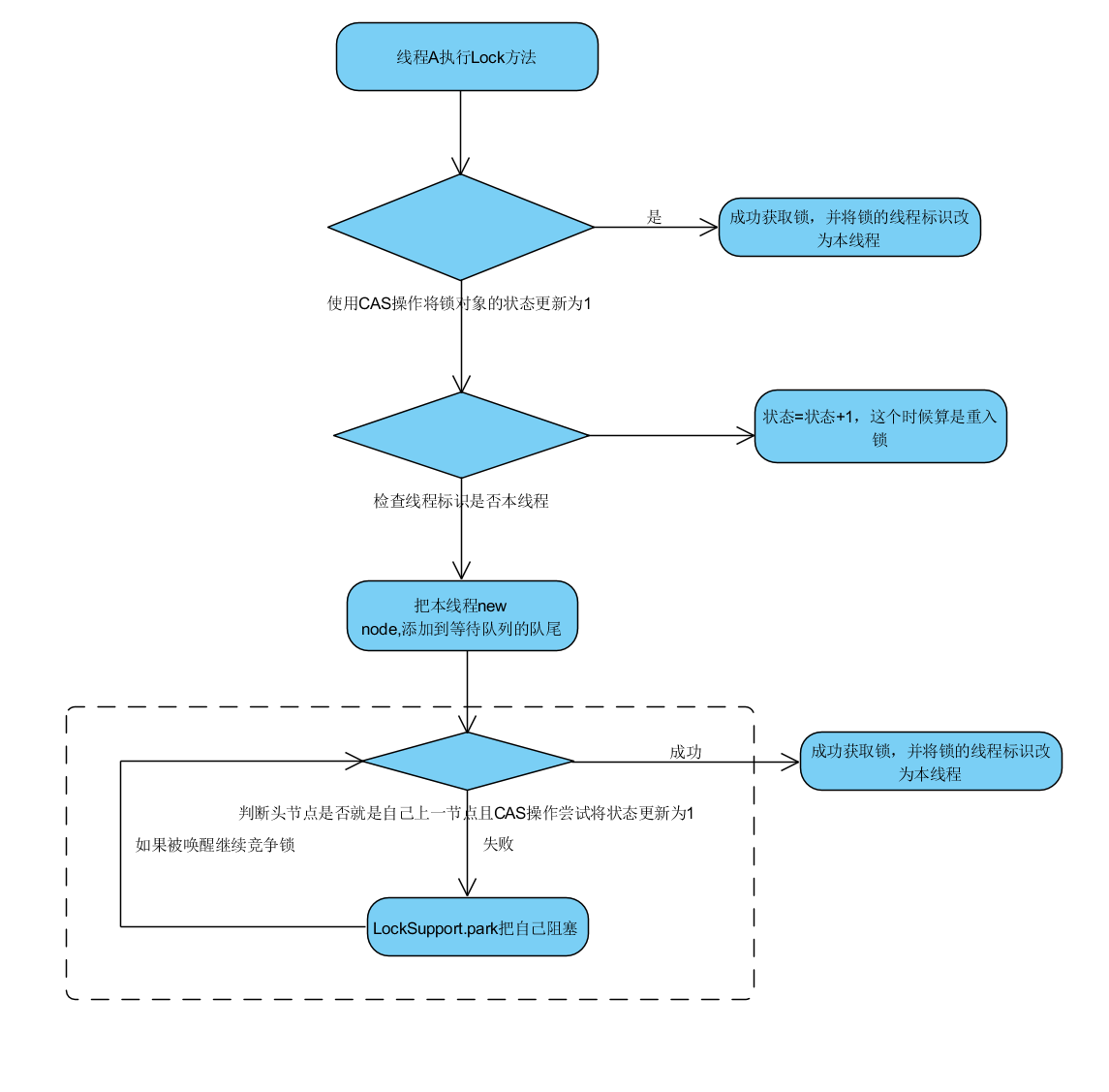
另外,说下lockSupport的阻塞和sleep,wait的不同,如下图,出处找不回了

CountDownLatch
前面说了两个互斥锁,现在说一下常用的辅助线程类,CountDownLatch维护一个state,当state为0时,阻塞的线程唤醒;而CyclicBarrier正好相反,维护一个目标值,当state达到目标值时,等待的线程唤醒。
//调用CountDownLatch构造函数,设置state为2 CountDownLatch countDownLatch = new CountDownLatch(2); new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(8000); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); //使用CAS操作将state-1,这时state==1,将队列的头线程唤醒,试图判断state==0,当然是失败的,然后又将自己阻塞掉 } }).start(); new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); //使用CAS操作将state-1,这时state==0,将队列的头线程唤醒,试图判断state==0,这时候成功了,然后唤醒下个一个阻塞的线程, } }).start(); try { new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(5000);//判断state!=0,添加到通过CAS操作成为队列的尾,并且将自己阻塞,这时候阻塞队列有2个线程 countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); countDownLatch.await();//判断state!=0,添加到队列,添加到通过CAS操作添加到队列的头,并且将自己阻塞,这时候阻塞队列有1个线程 } catch (InterruptedException e) { }
CopyOnWriteArrayList
在实际编程中,我们更多的是集合做操作,所以现在将类型换成线程不安全的ArrayList看看,如下
static List<String> intList=new ArrayList<>(); void startAddIntListTask() { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 10; i++) { intList.add(Thread.currentThread().getName()+" "+i); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(intList.size()); for (String x : intList) { System.out.println(x); } }
87 Thread-0 0 Thread-1 1 Thread-0 2 Thread-1 2 Thread-0 3 Thread-1 3 Thread-0 4 Thread-1 4 Thread-2 0 Thread-0 5 null Thread-0 6
上面是部分结果,已经可以看到总数不是我们期望的100,而且有的元素是null,这是为什么呢,看一下源码就很清晰了
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
第二行代码包含了三个步骤的操作,分别读取size,赋值size+1,赋值e,举个例子,
当线程一读取size=6,然后6+1=7赋值size,准备进行赋值elementData[size]=Thread-1 4,此时CPU时间片给了线程二
这时线程二读取size=7,然后7+1=8赋值size,准备赋值elementData[size]=Thread-1 4,此时CPU时间片给了线程一
所以线程一做的操作是elementData[8]=Thread-1 4,线程二的操作是elementData[8]=Thread-2 4,造成了elementData[7]没有赋值,elementData[8]赋值了两次
解决这种情况的可以使用CopyOnWriteArrayList类,原理就是在add和delete方法里面用了ReentrantLock锁,保证多线程环境下互斥对元素操作
参考
http://www.runoob.com/java/java-tutorial.html
http://www.cnblogs.com/skywang12345/p/java_threads_category.html
https://www.cnblogs.com/aspirant/p/7200523.html
https://www.cnblogs.com/sheeva/p/6366782.html
深入理解Java虚拟机
等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号