


【集群监控】Docker上部署Prometheus+Alertmanager+Grafana实现集群监控
Docker部署
下载
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装
sudo yum install docker-ce
启动
sudo systemctl start docker
加入开机启动
sudo systemctl enable docker
如果想监控Docker容器,可以安装cAdvisor
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --publish=8080:8090 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
访问http://XXX:8090可以看container的详细信息(打开过程可能会比较慢)
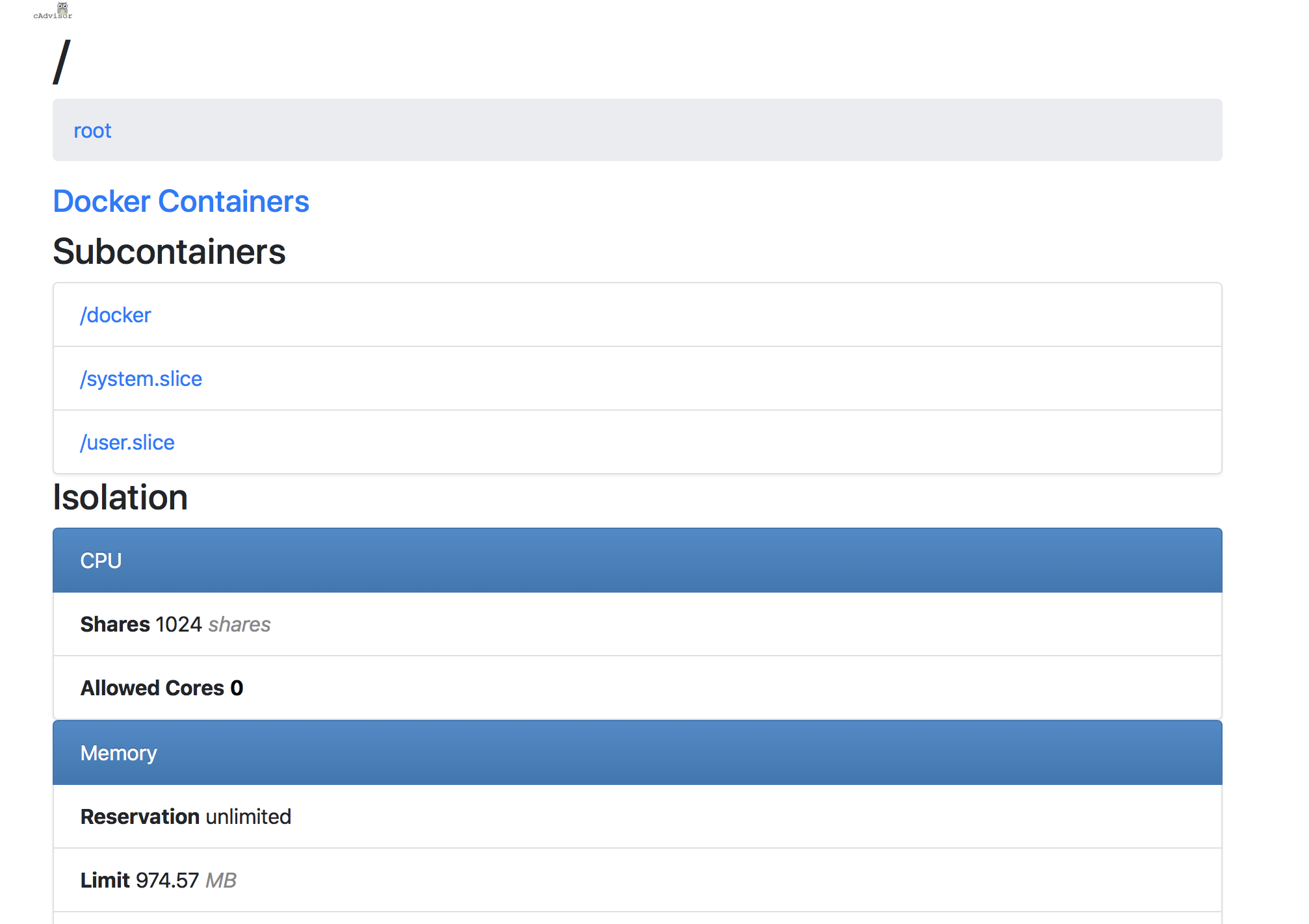
在Docker中部署Prometheus
修改prometheus.yml,添加cAdvisor监控
- job_name: cadvisor1 static_configs: - targets: ['XXXX:8090'] #XXXX最好用真实的IP,不然可能会出问题
找不到prometheus.yml可以下载prometheus(https://prometheus.io/download/),解压,包里有
运行prometheus容器(第一次运行会自动拉取镜像)
docker run -d -p 9090:9090 --name=prometheus -v /Users/caizh/fsdownload/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus #/Users/caizh/fsdownload/prometheus.yml为本地prometheus.yml路径,换成自己的,/etc/prometheus/prometheus.yml为容器中路径
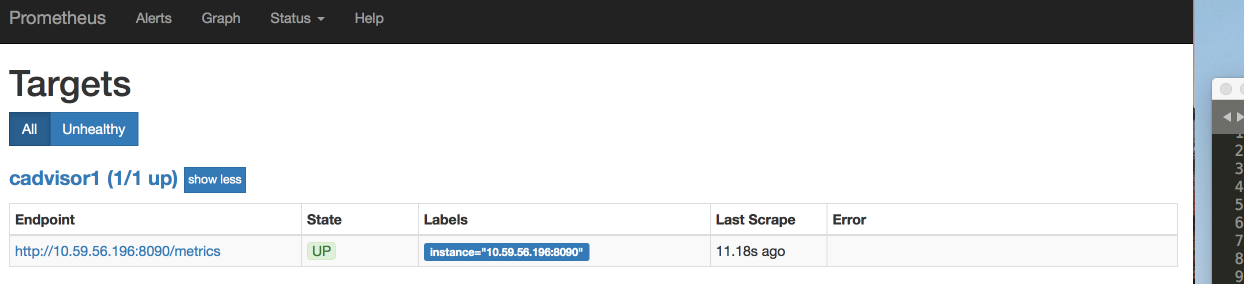
打开 http://XXXX:9090/targets 查看prometheus是否启动成功
成功界面如下
在Docker中部署Grafana
运行grafana容器
docker run -d -p 3000:3000 --name=grafana grafana/grafana
打开 http://XXXX:3000 查看grafana是否启动成功
成功界面如下

默认账号,密码都是admin
添加数据源,下载添加dashboard 参考另一篇:https://www.cnblogs.com/caizhenghui/p/9132414.html
可以在 https://grafana.com/dashboards 下载docker相关的dashboard,但是上边提供的dashboard效果不一定好,可以根据需要自己配
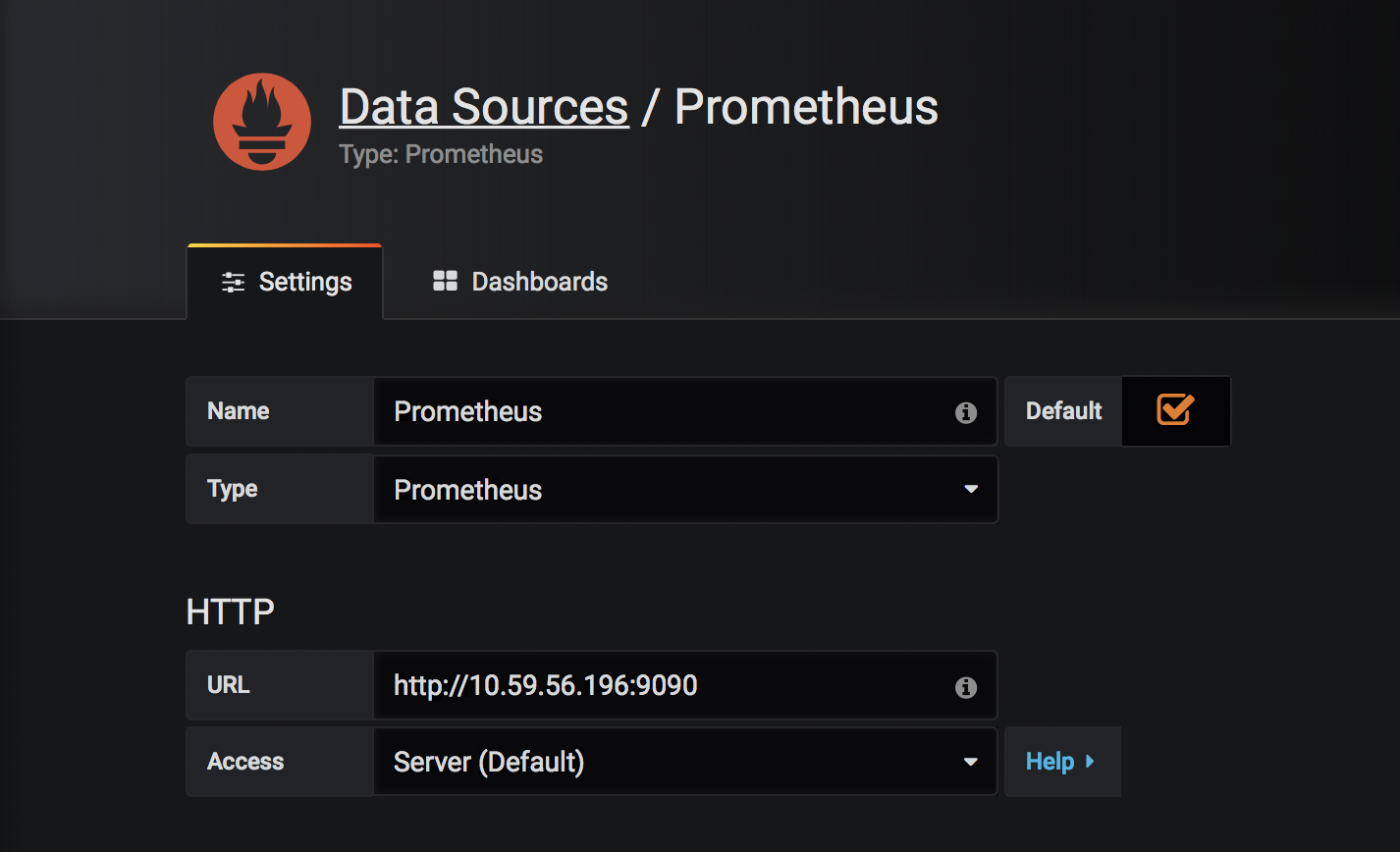
需要注意的是在docker中添加prometheus数据源,URL需要写真实IP,不然可能会出问题
如下图:
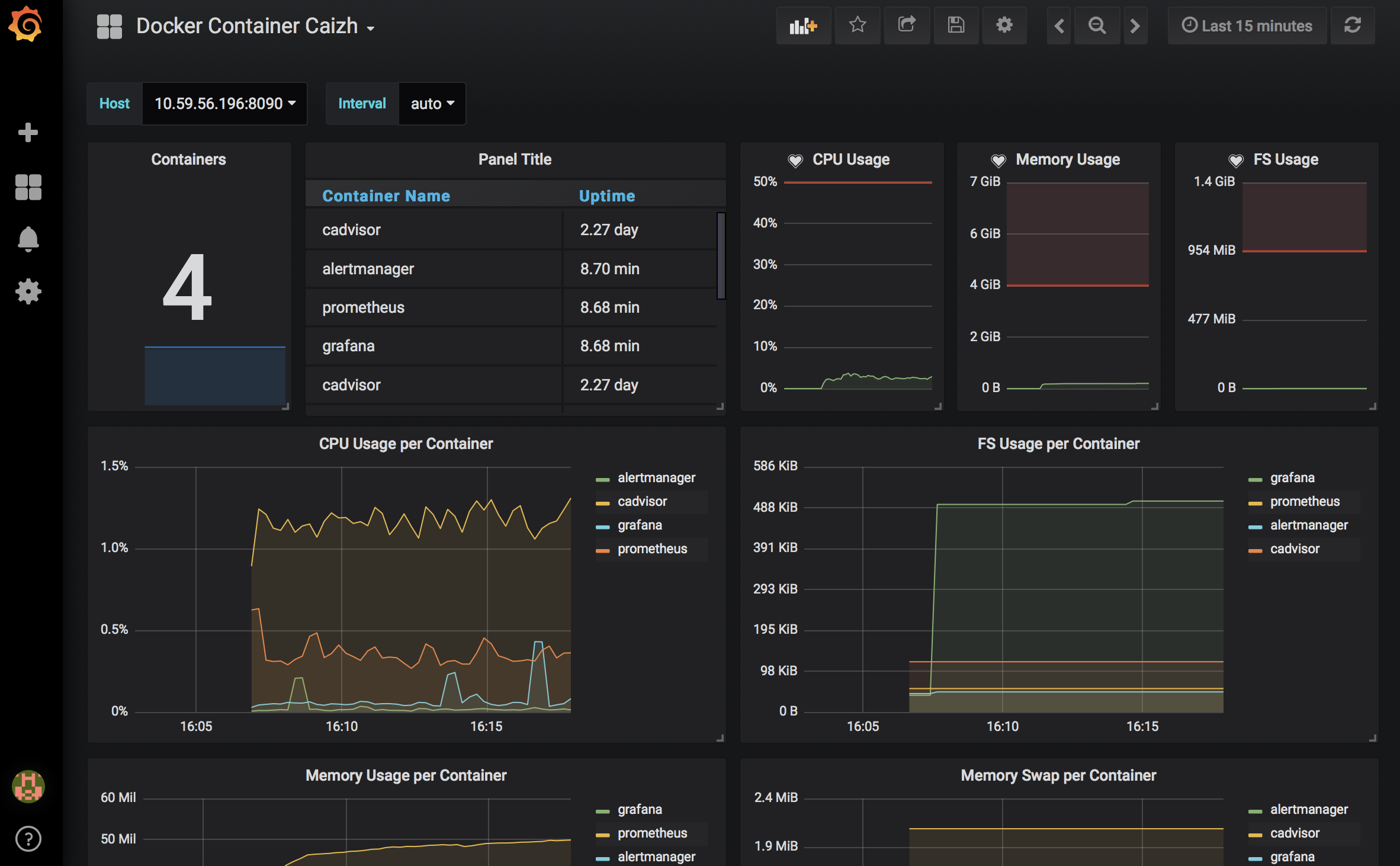
最后添加或配置好dashboard就可以看到容器的相关信息了
我配好的大体效果如下:
然后,就可以继续加入报警规则了
在Docker中部署Alertmanager
配置报警方式的配置文件config.yml
配置报警规则文件(我配置了两个,node_down.yml为 prometheus targets 监控,memory_over.yml节点内存使用率监控)
并在prometheus.yml中启用报警
配置过程参考:https://www.cnblogs.com/caizhenghui/p/9144805.html
启动alertmanager容器
docker run -d -p 9093:9093 -v /Users/caizh/fsdownload/:/etc/alertmanager/config.yml --name alertmanager prom/alertmanager
如果配置文件加载成功,在 http://XXXX:9093/#/status 会看到Config中是你的配置文件中的配置,如下图
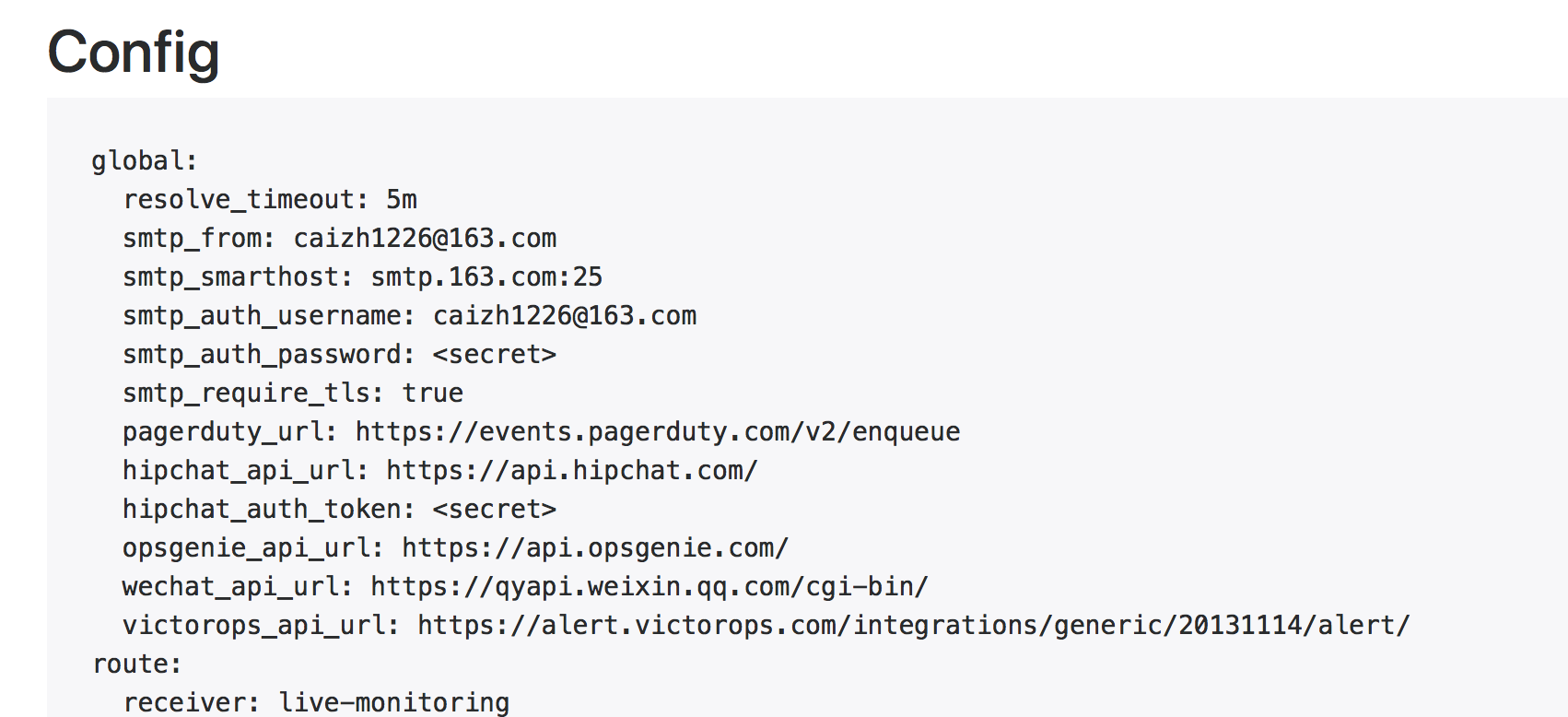
重新启动prometheus容器,来加载报警配置
docker run -d -p 9090:9090 --name=prometheus \ -v /Users/caizh/fsdownload/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /Users/caizh/fsdownload/node_down.yml:/etc/prometheus/node_down.yml \ -v /Users/caizh/fsdownload/memory_over.yml:/etc/prometheus/memory_over.yml \ prom/prometheus
报警规则配置成功在 http://XXXX:9090/alerts 可以看到报警规则已经添加到prometheus的Alerts中
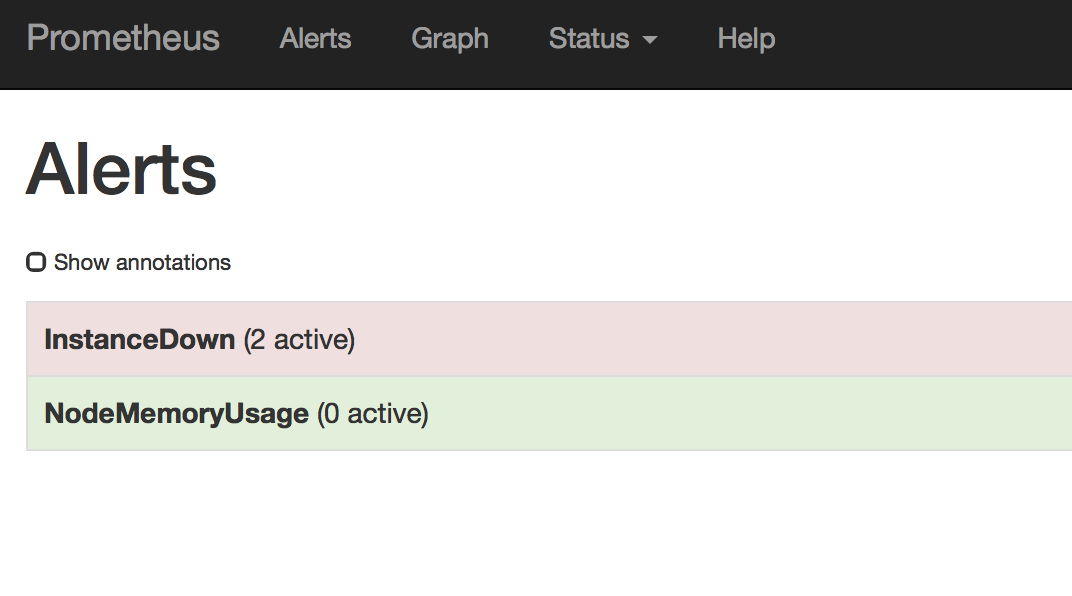
停掉cAdvisor容器
docker stop cadvisor
等待一会,看是否会给你配置的邮件报警
成功邮件类似下图:

配来配去很麻烦有木有T^T。。。
我们来一个简单粗暴的方式
docker-compose
version: '2' networks: monitor: driver: bridge services: prometheus: image: prom/prometheus container_name: prometheus hostname: prometheus restart: always volumes: - /Users/caizh/fsdownload/prometheus.yml:/etc/prometheus/prometheus.yml - /Users/caizh/fsdownload/node_down.yml:/etc/prometheus/node_down.yml - /Users/caizh/fsdownload/memory_over.yml:/etc/prometheus/memory_over.yml - /Users/caizh/fsdownload/record_rule.yml:/etc/prometheus/record_rule.yml ports: - "9090:9090" networks: - monitor alertmanager: image: prom/alertmanager container_name: alertmanager hostname: alertmanager restart: always volumes: - /Users/sf/fsdownload/config.yml:/etc/alertmanager/config.yml ports: - "9093:9093" networks: - monitor grafana: image: grafana/grafana container_name: grafana hostname: grafana restart: always ports: - "3000:3000" networks: - monitor
注:
解释一下上边的record_rule.yml是啥,不关心则删掉record_rule.yml那行,并跳过这段
record_rule.yml 配的是一个record rule的例子,是一个提前计算好的变量以方便grafana更快的调用
groups: - name: memory_sum_by_job rules: - record: jvm_memory_bytes_used_total expr: sum(jvm_memory_bytes_used) by (instance)
我的规则是计算各个节点JVM的堆和非堆内存使用量,当然要先装好jmx exporter,可参考 https://www.cnblogs.com/caizhenghui/p/9132414.html
更多信息参考官网:https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
启动容器:
docker-compose -f /Users/caizh/Desktop/docker-compose-monitor.yml up -d
停止容器:
docker-compose -f /Users/caizh/Desktop/docker-compose-monitor.yml down
需要注意,down之后grafana中的登陆信息,配置等就没了,会自动删除容器,若不想删除可以用 docker stop 容器名 来停止容器
虽然简单,但还是先配一次熟悉一下为好~
内容较多,不是很详细,可以多参考之前的随笔~

