selenium + ChromeDriver 实战系列之启信宝(一)
之前写了一篇selenium + ChromeDriver的一些入门的知识,这篇博客里面找了启信宝这个网站,简单的进行了一个实战练习。本篇博客的结构如下:
首先会给出一些使用selenium + ChromeDriver的入门的一些友情链接
其次讲解一下本人在爬取网站的一些思路和流程
最后给出github地址并总结经验。
1. 友情链接
环境配置以及入门知识参考我的之前一篇博客:
详细使用方式参考webDriver中文社区:
使用过程的常见异常参考他人博客:
2. 爬取思路及流程
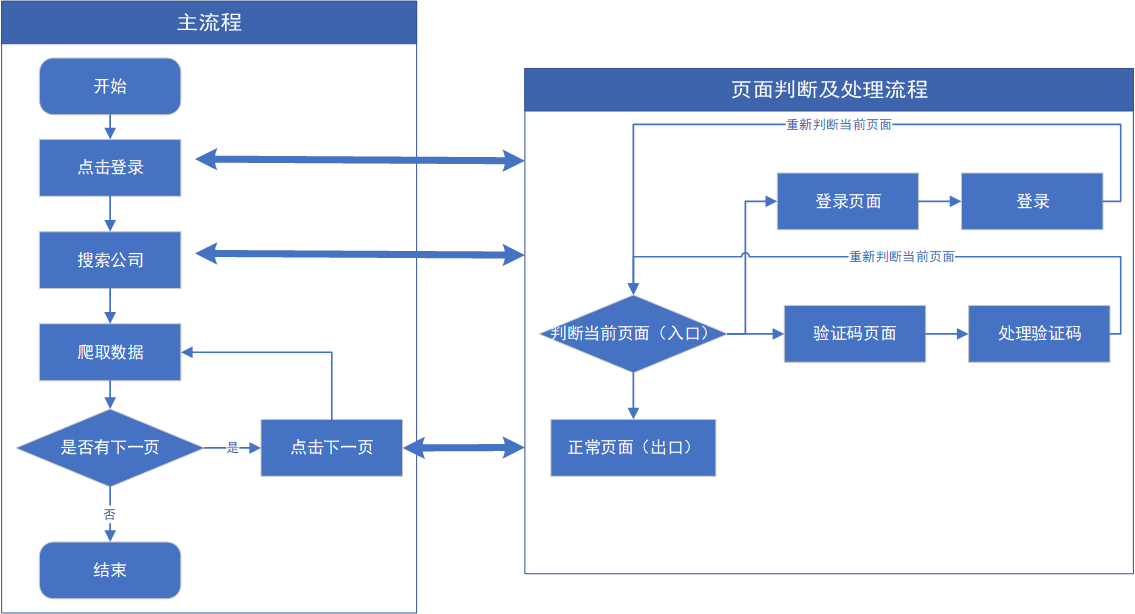
整体的爬取思路见上图,分为两个流程的原因是:在点击页面去向另一个页面时会出现让你登陆或者数据验证码的情况。如果每一步都要进行判断不好管理,还不如直接放在一个方法里面进行管理。只要每次有点击页面链接或者按钮的情况都进入到页面判断及处理流程中去。通过这个方法判断你新进入的页面是什么情况,并且对不同的页面进行不同的处理。下面对每个步骤进行详细讲解
2.1 点击登录
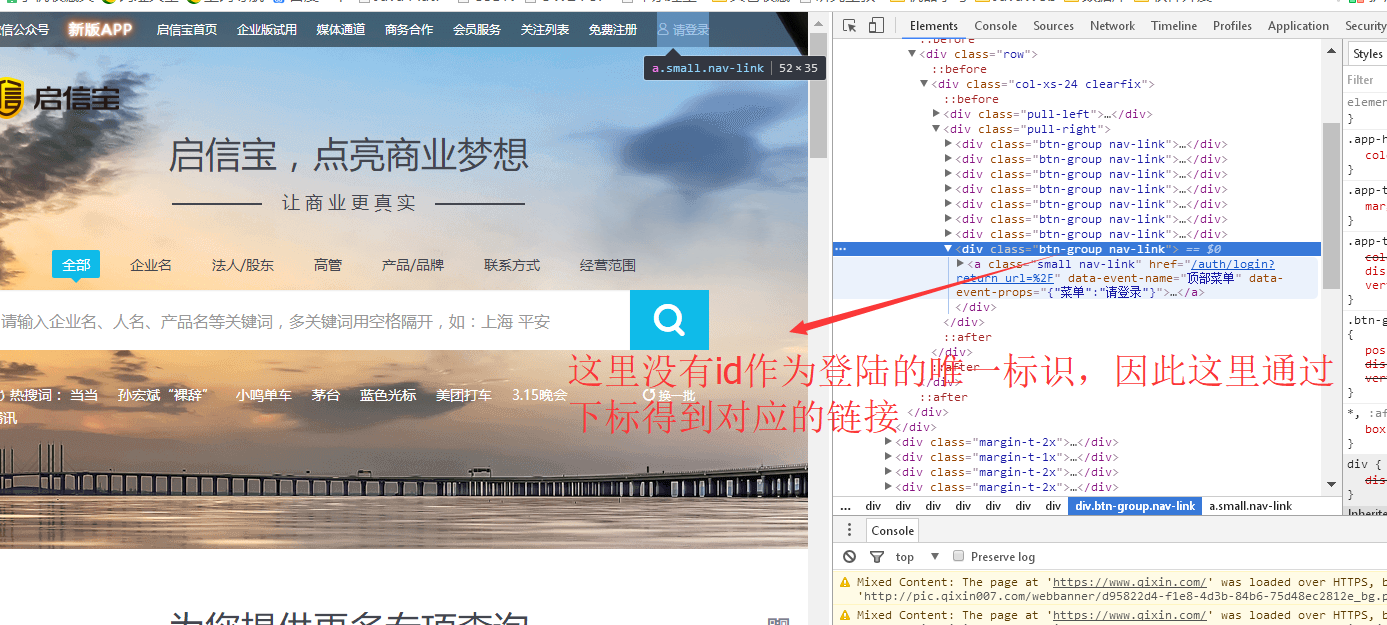


1 //去登陆页面并且登录 2 public static void toLoginAndLogin(WebDriver driver) { 3 //1、去登陆页面 4 List<WebElement> elements = driver.findElements(By.cssSelector("div.pull-right a")); 5 //2、通过下标得到对应的登录链接 6 WebElement loginElement = elements.get(elements.size() - 1); 7 loginElement.click(); 8 //2、该方法判断当前页面是登录页面,则进行登录 9 CompanyInfoPageHandle.handleDifferentPage(driver); 10 }
2.2 搜索公司
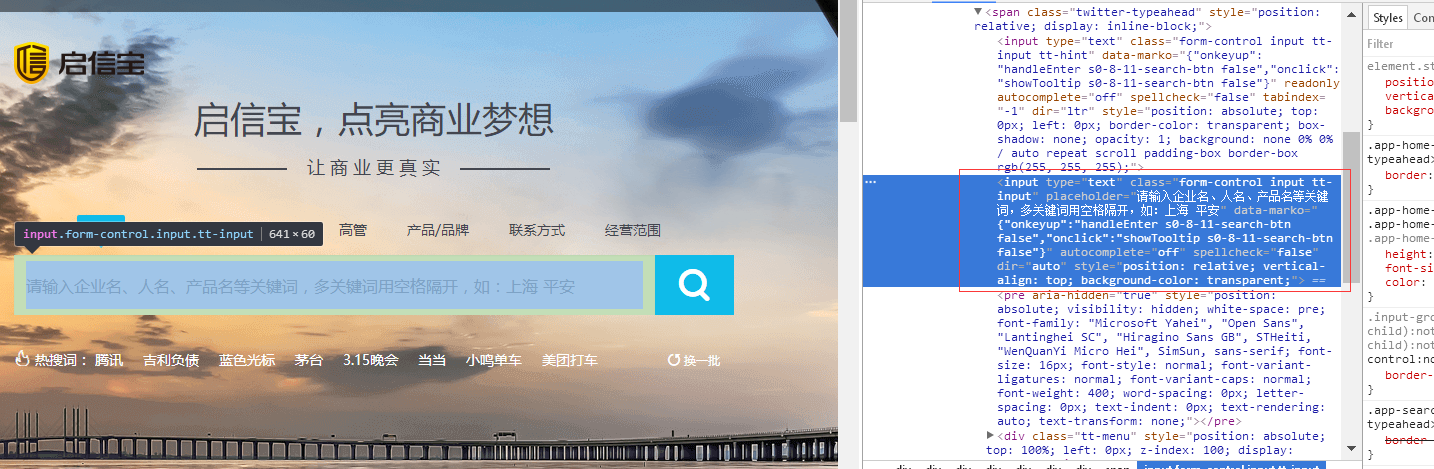
//查询公司名称 public static void searchCompanyName(WebDriver driver, String CompanyName) { //1、查询公司名称 try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } //2、选取输入框 WebElement search = driver.findElement(By.cssSelector("input[placeholder=\"请输入企业名、人名、产品名等关键词,多关键词用空格隔开,如:上海 平安\"]")); search.sendKeys(CompanyName); //3、选取按钮 WebElement submit = driver.findElement(By.cssSelector("i.input-group-addon.search-btn.icon.icon-search")); submit.click(); //4、判断当前页面的情况并进行处理 CompanyInfoPageHandle.handleDifferentPage(driver); }
2.3 爬取当前数据
/** * 保存信息 * @param driver * @param companyName */ private void saveResult(WebDriver driver, String companyName) { try { Thread.sleep(2000); //1、首先遍历每行的公司信息 List<WebElement> companyElementList = driver.findElements(By.cssSelector("div.col-xs-24.padding-v-1x.margin-0-0x.border-b-b4.company-item")); //2、保存当前一行公司的信息 for (WebElement companyElement : companyElementList) {//保存信息 try { List<WebElement> companyInfoElementList = companyElement.findElements(By.cssSelector("div")); List<String> infoList = new ArrayList<>(); for (WebElement companyInfo : companyInfoElementList) { infoList.add(companyInfo.getText().replace("\n", "")); } String result = String.join("\t", infoList); FileUtils.saveLineAppend(companyName + ".txt", result); } catch (Exception e) { continue; } } } catch (Exception e) { e.printStackTrace(); } }
2.4 页面判断及处理
在之前的过程中,只要有点击事件触发则需要判断触发之后的页面是什么页面,才能够对当前的页面进行处理。主要分为两个过程,第一步判断当前页面是什么,第二步对不同的页面有不同的处理方式,具体见下面代码:
/** * 用来判别页面的情况 */ public class CompanyInfoPageClassification { /** * 页面判断的主方法,用来判断当前的页面是什么页面 * @param driver * @return */ public static String PageClassificationMain(WebDriver driver){ if (isVerificationCodePage(driver)){ return "验证码"; } if (is404Page(driver)){ return "404"; } if (isLoginPage(driver)){ return "登录"; } return "正常"; } /** * 判断当前页面是否是验证码页面 * @param driver * @return */ private static boolean isVerificationCodePage(WebDriver driver){ List<WebElement> buttonList = driver.findElements(By.cssSelector("button.btn4")); if (buttonList.size() != 0 && buttonList.get(0).getText().equals("点击按钮进行验证")) { return true; } else { return false; } } /** * 判断当前页面是否是404 * @param driver * @return */ private static boolean is404Page(WebDriver driver){ List<WebElement> buttonList = driver.findElements(By.cssSelector("div.error-container.error-404")); if (buttonList.size() != 0 ) { return true; } else { return false; } } /** * 判断当前页面是否是登录页面 * @param driver * @return */ private static boolean isLoginPage(WebDriver driver){ List<WebElement> buttonList = driver.findElements(By.cssSelector("input[placeholder=\"请输入手机号码\"]")); if (buttonList.size() != 0 ) { return true; } else { return false; } } }
** * 根据不同的页面进行不同的处理 */ public class CompanyInfoPageHandle { public static void handleDifferentPage(WebDriver driver){ try { Thread.sleep(2000); } catch (Exception e) { e.printStackTrace(); } String pageStatus = CompanyInfoPageClassification.PageClassificationMain(driver); switch (pageStatus){ case "验证码": //1、如果是验证码页面那么需要在这里进行处理,例如手动输入验证码。如果验证码比较简单可以使用字符识别的方法 System.out.println("验证码页面"); //2、登录完了之后再判断是什么页面,然后再对当前页面进行处理 handleDifferentPage(driver); break; case "登录": //1、如果是登录页面那就进行登录 login(driver, "用户名","密码"); //2、登录完了之后再判断是什么页面,然后再对当前页面进行处理 handleDifferentPage(driver); break; case "404": break; } } private static void login(WebDriver driver, String userName, String password){ WebElement phoneElement = driver.findElement(By.cssSelector("input[placeholder=\"请输入手机号码\"]")); phoneElement.sendKeys(userName); WebElement passwordElement = driver.findElement(By.cssSelector("input[placeholder=\"请输入密码\"]")); passwordElement.sendKeys(password); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } List<WebElement> elements2 = driver.findElements(By.cssSelector("div a.btn")); WebElement login = elements2.get(0); login.click(); } }
3. github地址并总结经验
经验总结:
1.在写代码时,会遇到一些错误,例如 li 标签下有 a 标签,如下面代码。如果只定位到 li 标签再调用 click() 方法会出现异常,还是要定位到 a 标签,再进行点击
<li><a href="/example" data-marko="{"onclick":"handleClickDebounce s0-9-20 false 0"}">2</a></li>
2.使用selenium + ChromeDriver进行爬虫并不能完全自动化,对于当前这个网站来说,当点击频率过高时需要你登录。因此我直接一开始就登录账号。登录之后点击频率再上来之后,就需要输入验证码,对于这种情况如果是一般的数字的验证码还可以用字符识别的技术。但是这个网站的验证码很难机器识别。
3.使用selenium + ChromeDriver进行爬虫其实是一个很鸡肋的东西,别人想要反扒你,其实很简单。
第一步:游客模式的时候对每个ip的请求频率做判断,只要超过某个频率那么需要你登录
第二步:第一步完成后你就有个账号,直接通过账号的请求频率或频次做判断,如果超过某个频率或频次那么需要你人机验证。目前的验证码都非常恶心,不再像以前那种字符的
4.当然使用selenium + ChromeDriver还是能够爬取一些数据,但是具体过程还需要人工干预,在碰到验证码的时候要暂停线程,然后输入验证码。不过 selenium 本身的主要目的也不是爬虫,而是做网页的自动化测试。具体想要爬取数据还是需要使用代理,直接发送接口请求恐怕才能获得持久稳定的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号