MLPerf 机器学习基准测试实战入门(三)recommendation
该任务对带有神经协同过滤模型的MovieLens 2000万(ml- 2000万)数据集进行隐式反馈的推荐基准。该模型根据关于用户是否与特定物品交互的二进制信息进行训练。
实现参考来自:https://codeload.github.com/mlcommons/training/zip/master
将MLPerf库拷到本地
sudo apt-get install unzip curl
git clone https://github.com/mlperf/training.git
安装基本环境
安装 python相关包
cd training/recommendation/pytorch
pip install -r requirements.txt
安装 CUDA and Docker
source training/install_cuda_docker.sh
构建镜像
# Build from Dockerfile cd training/recommendation/pytorch sudo docker build -t mlperf/recommendation:v0.6 .
数据下载和预处理
参考training/data_generation/fractal_graph_expansions/
通过运行download_dataset.sh下载数据,verify_dataset.sh进行数据检查
source download_dataset.sh
也可以手动下载,查看download_dataset.sh
function download_20m { echo "Download ml-20m" curl -O http://files.grouplens.org/datasets/movielens/ml-20m.zip } function download_1m { echo "Downloading ml-1m" curl -O http://files.grouplens.org/datasets/movielens/ml-1m.zip } if [[ $1 == "ml-1m" ]] then download_1m else download_20m fi
下载完成后验证数据集
source verify_dataset.sh

进入training/data_generation/fractal_graph_expansions/,更改data_gen.sh中的数据集地址
vim data_gen.sh
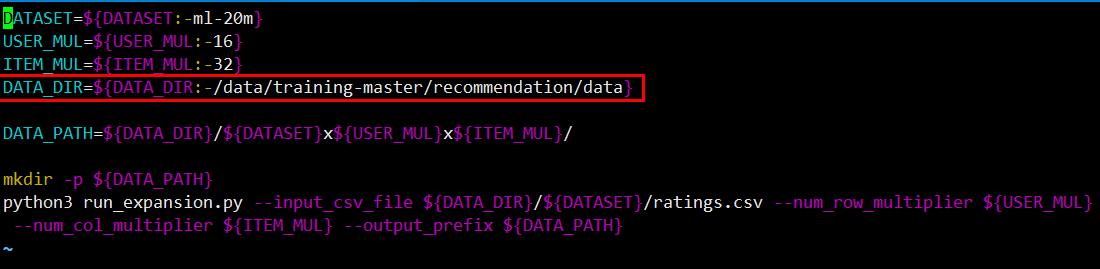
数据位置为刚才数据下载的地方,我的位置是
DATA_DIR=${DATA_DIR:-/data/training-master/recommendation/data}
由于我有两个python,所以我将python更改为了python3
运行data_gen.sh
./data_gen.sh

运行完成后的数据将存在数据目录里的/my_data_dir/ml-20mx16x32下