
大数据第十三周(上周补充)
大数据第十一周
1.物理集群的验证
- 开启本组所有电脑(4台),拷贝虚拟机映像,打开。在开启虚拟机之前,设置虚拟机内存是4G,处理器是4,网络连接是桥接模式。
![]()

也可以在图形界面配
![]()

- 把桥接网卡绑定到具体的物理网卡,不要使用自动绑定。
- 设置完成后,启动寻虚拟机。
![]()

2.设置网络连接
- 编辑网络配置文件:/etc/sysconfig/network-scripts/ifcfg-ens33。
![]()

- IP地址设置如下:(其中50要改成你自己的ip)
IPADDR=172.21.12.79(左1)
IPADDR=172.21.12.80(左2)
IPADDR=172.21.12.81(右2)
IPADDR=172.21.12.82(右1)
PREFIX=24
GATEWAY=172.21.12.254
DNS1=172.16.3.8
- 修改完成之后,输入systemctl restart network即可
![]()

3.设置hostname和域名解析
修改集群各个机器的名字和域名解析文件计算机名
- sudo vi /etc/hostname
80 master
79 slave0
81 slave1
82 slave2
50 slave4
- sudo vi /etc/hosts
172.21.12.80 master
172.21.12.79 slave0
172.21.12.81 slave1
172.21.12.82 slave2
172.21.12.50 slave4
![]()

4.关闭防火墙
- 检查防火墙状态:sudo systemctl status firewalld.service
- 关闭防火墙:sudo systemctl stop firewalld.service
- Disable防火墙:sudo systemctl disable firewalld.service
- 如果不执行Disable防火墙,下次启动时,防火墙还会启动。
- 重启三个节点,重启后,分别用sudo systemctl status firewalld.service命令检查所有节点的防火墙状态,要求看到inactive(dead)提示。
5.设置ssh免密登录
- 由于以前做过免密,所以会提示出错,看提示是否有修改错误的指令,如:删除~/.ssh文件后重做,命令:rm –r .ssh(ls –a查看隐藏文件)
- 先ssh 要登录的虚拟机,然后exit。
- 进入目录:cd .ssh/
- 产生密码:ssh-keygen -t rsa(只需要输入一次)
- 传送公钥:ssh-copy-id 要登陆的虚拟机名
- 验证:ssh 要登陆的虚拟机名
- 如果不需要密码就说明成功了。**如果在物理机集群上安装,需要安装时钟同步工具,保证每个节点的时钟相同。在虚拟机上安装不需要。**
- 我们有三个节点,所以每个虚机需要3个免密登录。
- 我们有三个节点,要传三个公钥,包括自己。
6.安装时钟同步
- 将时区设置为上海:sudo timedatectl set-timezone Asia/Shanghai
- 使用chrony,因为centos7已经内置chrony,所以只要配置就好。
- 选择一个本地时钟服务器,对于时钟服务器修改cd /etc sudo vi chrony.conf,要允许其他节点进行连接,
- 对于主节点:添加allow 172.21.12.0/24;
- 对于其他节点:删除已有的四行配置,添加server master iburst
![]()

- 时钟配置完成后检查,用命令:检查chronyc sources。除了主节点外,其它节点只会显示master。
7.修改配置文件
- 修改slaves文件,加入新的节点。
- slaves文件位置:hadoop-2.7/etc/hadoop
![]()

![]()

8.Namenode格式化
- 删除所有节点上的集群自动建立的文件夹:hadoopdata
- 在master上才做:hadoop namenode –format
- 要看到successfully提示,说明成功了。
9.启动集群
- 命令:start-all.sh
- 用jps查看java进程:按我们的配置,master是4个java进程,slave是3个java进程。
- 上传一个文件,查看是否正常
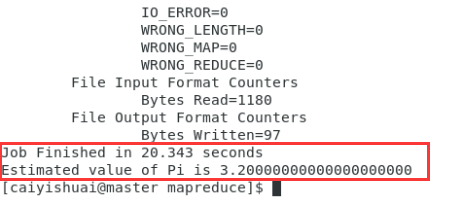
- 进入相应目录hadoop-2.7/share/hadoop/mapreduce,运行命令:hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 10 10
如果运行正常,说明集群工作一切正常。
![]()

![]()
10.安装spark
- Spark配置成:yarn模式运行。
- Spark集群需要配置两个文件,spark-env.sh、slaves。
- 建立spark-env.sh cp spark-env.sh.template spark-env.sh
![]()

- 编辑:vi spark-env.sh,添加如下内容,红色部分替换成自己的目录。
export SPARK_CONF_DIR=/home/caiyishuai/spark-2.4.5/conf
export HADOOP_CONF_DIR=/home/caiyishuai/hadoop-2.7/etc/hadoop
export YARN_CONF_DIR=/home/caiyishuai/hadoop-2.7/etc/hadoop
export JAVA_HOME=/home/caiyishuai/jdk1.8
![]()

- 建立slaves文件:cp slaves.template slaves
- 编辑:vi slaves
把文件原内容删除,添加slave节点名:例如
slave0
slave1
slave2
- 配置完成后,要将配置好的拷贝到其它的所有节点。每个节点的spark和hadooop配置应相同。
![]()

11.启动spark集群
- 由于我们是用yarn模式运行,首先要启动yarn,启动yarn的方式是用hadoop下的start-all.sh。
- 启动顺序是:hadoop的start-all.sh,spark的start-all.sh。
- 由于两个 文件同名,所以必须区分是哪一个。区分的方式可以是,spark路径不配置环境变量,而是用全路径执行。Spark要在master节点上启动。
- 启动后,用jps查看
master节点:
NameNode
Jps
ResourceManager
Master
SecondaryNameNode
Slave节点:
DataNode
NodeManager
Worker
Jps
说明启动成功。
![]()


