消息队列总结
如何选型消息队列,需要从以下三个方面考虑:
1. 如何做负载均衡?
负载均衡直接影响系统的吞吐和横向扩展能力
2. 如何达到低延迟?
低延迟也是决定吞吐的一方面,另外对于低延迟的消息中间件对业务系统更友好
3. 如何做故障恢复?
运维成本是选型需要注意的一点,需要24小时值守的消息中间件运维起来也是一个噩梦
4. 功能完善度?
功能不完善就需要做二次开发,功能完善度作为最后一个考量的因素是因为基于一个非常健壮的消息队列做二次开发肯定要强于维护一个非常臃肿低效的消息中间件
从上面四点来自顶向下的分析目前比较主流的三款消息中间件:Kafka、RocketMQ、RabbitMQ和我目前正在使用的QMQ。

上图主要提现了这四种消息队列运行环境差异,RabbitMQ是Erlang语言开发的,所以运行环境和其他的基于Java的有差异,由于对于Erlang没有研究,所以对ERTS不做评价。
关于JVM做消息中间件底层运行环境需要考虑的事情,todo:
下面从架构方面来对比差异:
kafka架构:
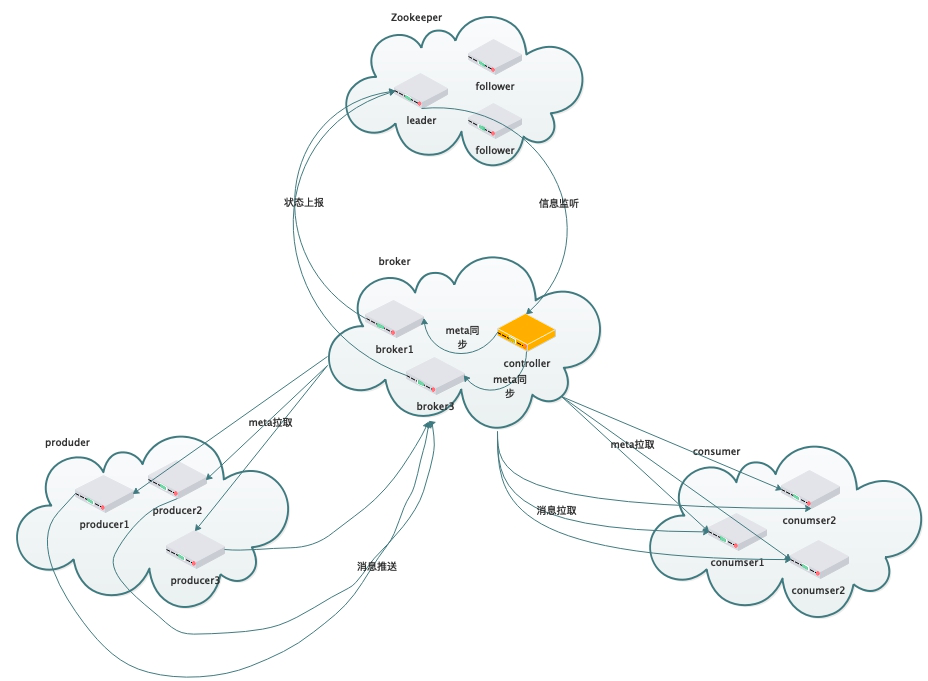
kafka主要架构思路:用kafka作为注册中心,broker的controller节点监听kafka znode变更做响应的集群调整,然后给meta信息同步给其他所有borker,客户端(生产者/消费者)从任何一个borker节点都能够拉取到全量的meta信息。
该架构优点:
1. 采用zookeeper作为注册中心,功能丰富,不需要再单独实现一套分布式一致性算法。
2. broker引入controller节点,只有controller节点监听zookeeper znode节点变更事件,防止产生羊群效应,导致zookeeper和broker集群性能波动,controller将meta信息同步给所有broker,有效均衡meta信息拉取负载。
3. broker引入consumer coordinator节点,每个consumer coordinator节点负责部分consumer group,有效均衡消费者状态存储压力。
缺点:
1. kafka内部再依赖zookeeper,会导致维护成本高,kafka和zookeeper都是分布式数据,但是底层组件都是不同的,导致kafka的学习成本、部署、维护复杂度高。
2. 因为controller节点需要全量拉取zookeeper里的状态,如果kafka集群比较大,会导致controller启动慢,这会限制kafka的发展。
3. zookeeper在做leader选举过程中集群不可用。
rocketmq架构:
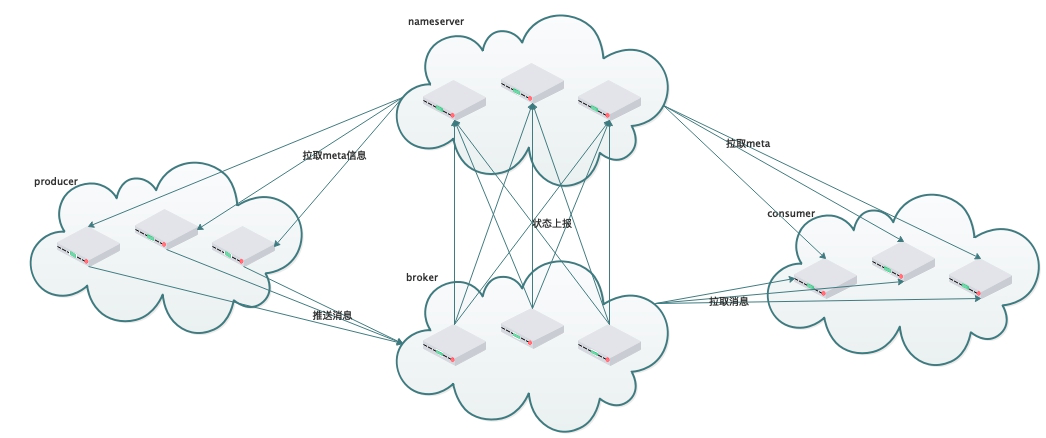
nameserver为无状态节点,每台broker都定时给每个nameserver节点提交当前节点状态,每个consumer跟broker集群中每个节点建立长链接,在心跳消息中上报当前消费者信息。
优点:
1. 相对于kafka,nameserver更加轻量级,维护简单。
2. broker集群状态变更和消费者重均衡都是通过定时心跳来完成的,逻辑简单且够用。
缺点:
1. 每个broker节点都要和所有的nameserver和consumer建立长连接,且在内存中存储所有consumer相关订阅信息,当消费集群非常大的时候,每台broker的内存会被占用掉一部分。
2. 集群状态同步全部都需要定时心跳来完成,相对于kafka只有在有数据变更的时候才会数据同步,rocketmq网络交互会比较高。
3. 由于都是通过定时心跳来完成状态更新,所以相对于zookeeper会有状态更新延迟的问题。
rabbitmq架构:

rabbitmq没有注册中心,集群元数据多个broker间进行同步。
优点:
少一个组件,系统更简单,维护成本更低。
缺点:
broker的压力更大,meta信息同步会耗费系统资源,所以rabbitmq相对于其他的mq系统吞吐会弱一些,当qps高一点或者broker节点数比较多,broker系统压力比较大。
下面从存储结构来分析:
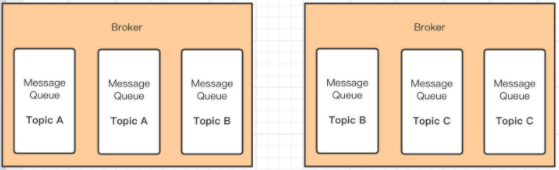
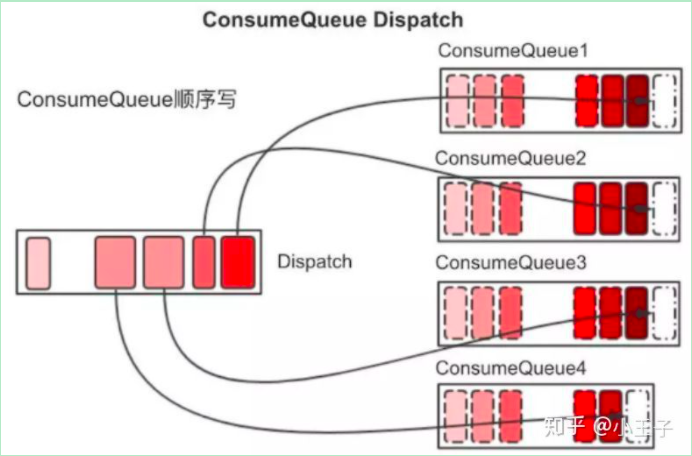
对于Kafka和RocketMQ都是采用对topic分成多份来分布式存储以提升扩展能力,Kafka叫Partition,RocketMQ叫ConsumerQueue,但是两者还有一些差别,partition存储的是实际消息,但是consumerqueue中存储的只是消息的偏移,真正的消息存储在rocketmq的commitlog中:
rabbitmq中也有topic的概念,但是同一个topic的消息是放在一起的:
从上面存储接口分析可以看出rabbitmq对于某个topic消息堆积比较大的情况下单节点系统压力会比较大,但是kafka和rocketmq采用分区就没有这个问题。
再看下对于消息可靠性存储是如何做的:
kafka对分区实现一主多从架构,主分区接受读写请求,从分区从主分区同步数据进行备份;RocketQM以broker节点纬度实现主从架构,从节点从主节点同步数据备份;rabbitmq以队列纬度配置镜像队列,镜像队列同步主队列。
分区可靠性保证:
kafka当主分区故障,由kafka控制器根据PaficA算法选举新的主分区接受读写;RocketMQ当主broker节点挂掉,从节点提供数据读取,但是到宕机主节点的写请求会拒绝,因为RocketMQ没有实现选举功能,所以如果节点宕机必须处理然后重启,否则节点上数据会丢失,rabbitmq也实现了选举逻辑,当主队列损坏,从镜像队列中选举新的队列接受读写(如何实现的? todo:)。
数据存储可靠性:
上面说的都是宏观的,如何保证数据可靠存储待看数据存储方式,是持久存储还是临时存储,kafka和rocketmq都使用了磁盘映射,所以消息是先写入内存,然后由操作系统异步刷盘,所以异步刷盘的时间如果宕机会有数据丢失;持久型的rabbitmq消息是会首先落盘再返回成功,所以持久性的rabbitmq消息理论上是可靠的。
数据清理:
kafka和rocketmq的数据消费都是基于offset,所以数据会一直存储,然后通过后台任务根据一定的策略清理历史数据。而rabbitmq的消息被消费了以后就会从队列中删除。
从上面的分析再来看看这几种mq的指标:
负载均衡:
kafka和rocketmq对topic都使用分区的方法给一个topic的数据分布到多个节点,但是rabbitmq没有分区,所以如果某个topic消息多,直接导致单台broker负载高。
低延迟:
kafka和rocketmq都是使用内存映射和zero copy技术提升文件和网络IO速度,理论上读写几乎达到内存读写。rabbitmq也是采用尽量用内存的思路,但是没有使用操作系统的功能,而是尽量让数据存储在内存,当内存不足时才刷盘。所以理论上都能达到很低的延迟。
故障恢复:
kafka当主分区损坏由controller节点选举新的主分区,rocketmq当主节点宕机,需要人工修复并重启,rabbitmq当主队列损坏也会自动选举镜像队列替换主队列,所以从这点看rocketmq的运维便利性比较差。
功能完善度:
上面没有分析过这点,从历史背景看kafka主要是为了流计算而生,而rocketmq和rabbitmq是为业务而生,相对的rocketmq和rabbitmq的功能更加完善,比如延迟队列、死信队列,当然也可以基于kafka做二次开发。从上面数据清理逻辑来看,rabbitmq无法实现消息回溯功能,因为消息消费后就删除了。

