PhaseScorer:感慨高手写的代码就是精炼
PhaseScorer解决的是语句搜索场景,例如搜索hello world,这表示命中的文档中要hello world这样的句子,两个单词的前后顺序固定。PhaseScorer有两个实现类:ExactPhaseScorer和SloppyPhaseScorer,分别解决搜索脚本里多个单词中间没有其他单词和有其他单词的场景。
PhaseScorer实现了找出哪些文档中同时包含搜索脚本里的多个单词,两个子类实现从父类定位的文档中找出这个搜索句子在这个文档中出现的频次。
PhaseScorer找文档的算法类似BooleanQuery中使用的找文档算法,具体算法如下:
代码:
while (more && first.doc < last.doc) { // find doc w/ all the terms more = first.skipTo(last.doc); // skip first upto last firstToLast(); // and move it to the end }
这段代码执行的前提是搜索句子里的每个词元所属的文档编号是顺序排列的,这个在PhasePositions.next()方法中需要满足这样的前提。这个算法可以抽象成在多个队列中找到包含的相同的元素,队列中每个元素是一个int类型的数字,队列中的元素是从小到大排列好顺序的,每个队列支持next()方法获取下一个元素,支持skip(元素值)方法跳转到指定元素值位置处(如果指定元素值存在),或者比指定元素值大但是最接近指定元素值的位置处(如果指定元素值不存在),支持doc获取当前遍历的文档ID。
举例有以下三个队列:
队列A:1 -> 2 -> 3 -> 4 -> 5 -> 6
队列B:2 -> 3 -> 4 -> 5
队列C:3 -> 4 -> 5
现在找出这三个队列中同时包含的数字3。
-> 首先再建立一个临时队列D,队列D里每个元素是以上三个待处理的队列。
-> 根据队列A/B/C中当前遍历的文档对临时队列D排队:队列A、队列B、队列C
-> 判断队列D的队首(文档ID)是否小于队尾(文档ID)
-> 如果队首的文档ID小于队尾,则队首队列A调用skip方法跳转到队尾队列C的文档3
-> 队列D队首队列A移动到队尾
-> 然后再重复判断队首队列的文档是否小于队尾
-> 直到队首文档不小于队尾结束,则找到合适的数字
图示:
初始状态,红色箭头标示每个队列当前遍历的文档:
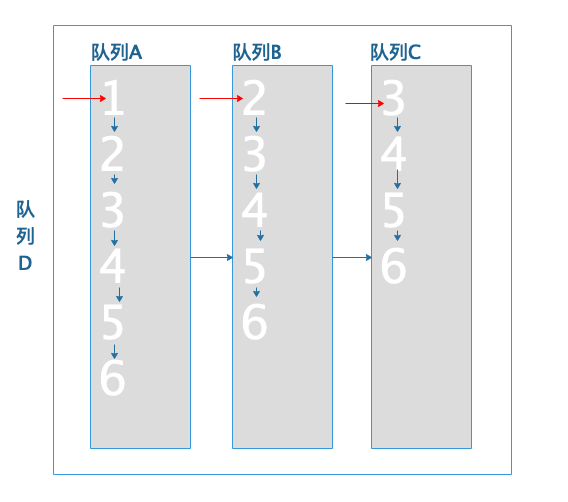
队列A文档ID1小于队列C文档ID3,队列A文档跳转到队列C文档3:
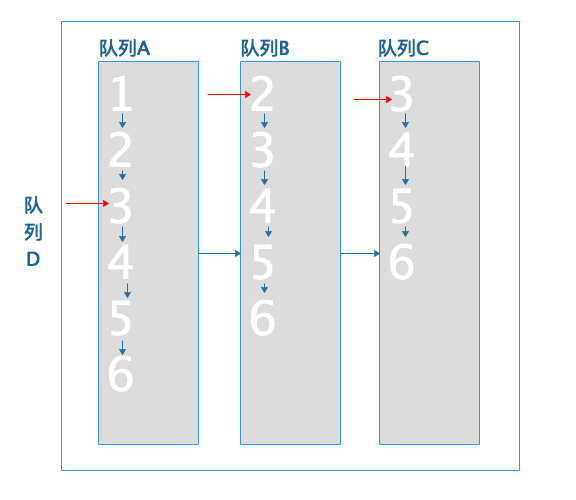
将队列A移动到队尾:
队列D队首 队列B的当前文档2小于队列D队尾队列当前文档3,队列B当前文档跳转到队列A的当前文档3:
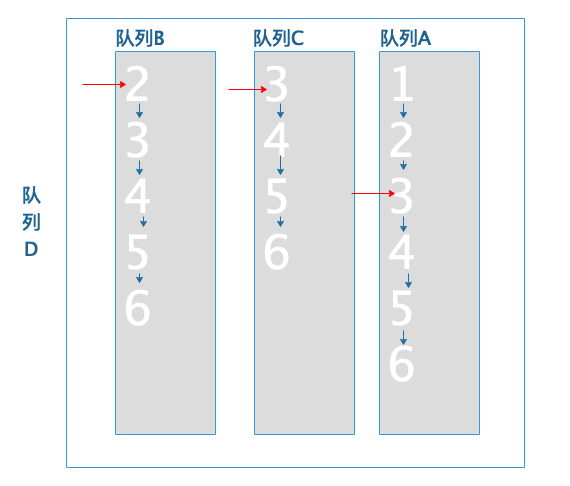
将队列B移动到队列尾:
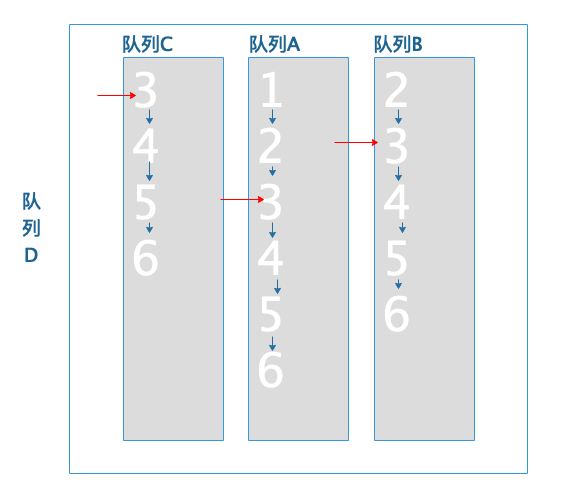
队列首队列-队列C的当前文档ID3不小于队列尾的队列-队列B当前文档3,所以3就是符合的文档。
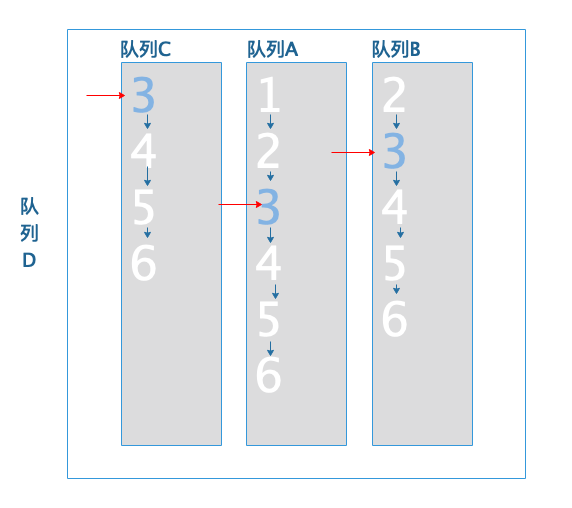
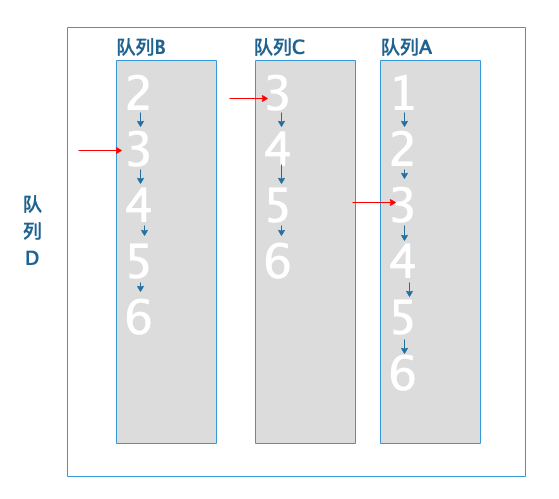
由于队列都还有没有遍历的文档数据,所以将队列尾的队列-队列B向下移动一个文档ID:

判断队列首队列-队列C的文档小于队列尾的队列-队列B文档4,队列C文档跳转到队列B当前文档4:
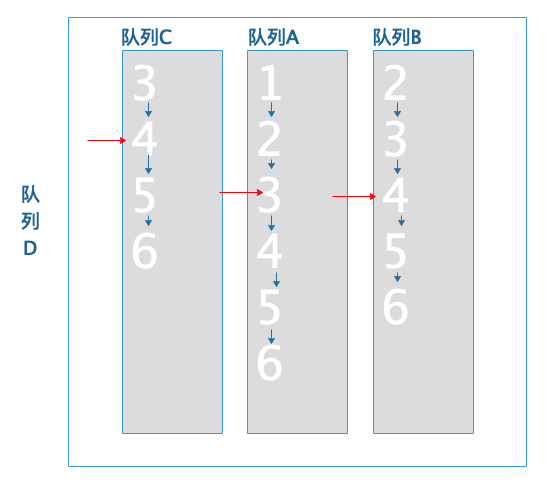
队列C移动到队尾:
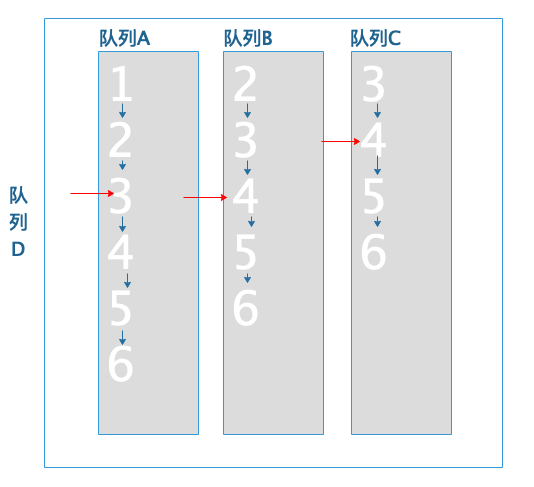
判断队列A的文档3小于队列C的文档4,所以将队列A的文档跳转到队列C的文档ID4:
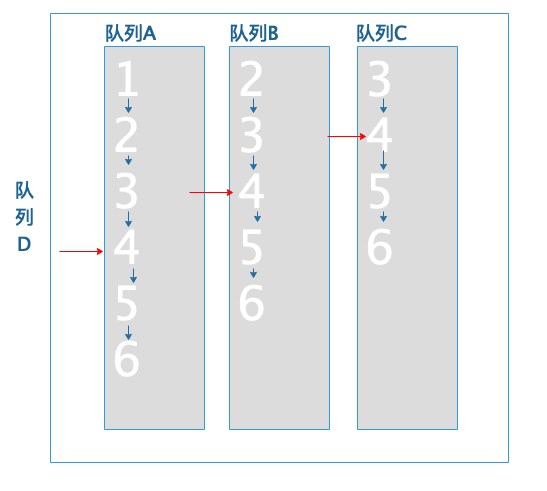
队列A移动到队尾:
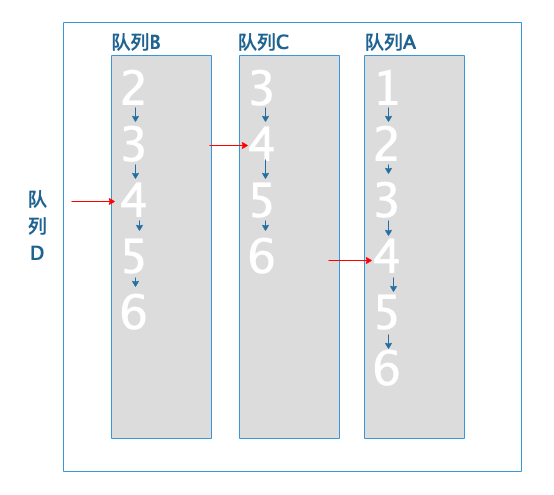
由于队列B的当前文档4不小于队列A的当前文档4,所以4是命中的文档ID:

以此类推,直到某一个队列走到末尾。
上面描述的就是PhaseScorer找文档算法的基本思路。子类ExactPhaseScorer继承PhaseScorer,解决的搜索场景是搜索句子中多个词元间没有其他单词的场景,ExactPhaseScorer实现了PhaseScorer唯一的一个抽象方法phaseFreq,该方法返回搜索句子在PhaseScorer类选定的文档中的出现频率。ExactPhaseScorer类从PhaseScorer中继承了搜索句子中每一个词元在当前选定文档中的位置,比如当前搜索a b c d,一个同时包含这四个单词的文档内容如下(括号里是单词的位置):
........a(5).........a(12).......a(20) b(21)......a(30) b(31) c(32)......a(40) b(41) c(42)......
从上面这个文档中可以得到:
a出现的位置:5、12、20、30、40
b出现的位置:21、31、41
c出现的位置:32、42
类似上面每个词元的位置可以通过段读取模块里得到,这个数据是前提,现在问题来了,如果通过上面的这个数据,得到a b c在这个文档中出现频率? 注意 a b c中间不能插入其他单词,且a、b、c的前后位置不能改变。
lucence实现的比较巧妙,因为要a、b、c的顺序不能变,且中间不能插入其他的单词,所以a、b、c中间的位置肯定都差1,把a、b、c的位置减去它们对应的这个搜索句子的偏移量就可以把它们在文档中的位置归一到单个位置上,比如如果a的位置在20处,那如果要命中这个单词,那b肯定是21,c肯定是22,把这三个位置都减掉offset得到a、b、c都在20处,这样就把问题简化成从a、b、c出现的位置列表里找到减掉offset以后值相同的位置,如果有这样的位置那这个位置就命中,否则就不命中。这样简化以后就可以利用PhaseScorer类中的在多个已排序列表中找到相同数值的算法。
比如上面的例子,可以转化成:
a位置:5、12、20、30、40 offset = 0
b位置:20、30、40 offset = 1
c位置:30、40 offset = 2
这样用上面PhaseScorer的算法可以得到30、40是都存在的,进而得到这个搜索句子在这个文档中出现的频率为2

