

第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
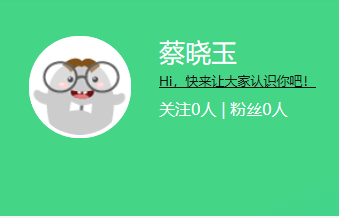
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
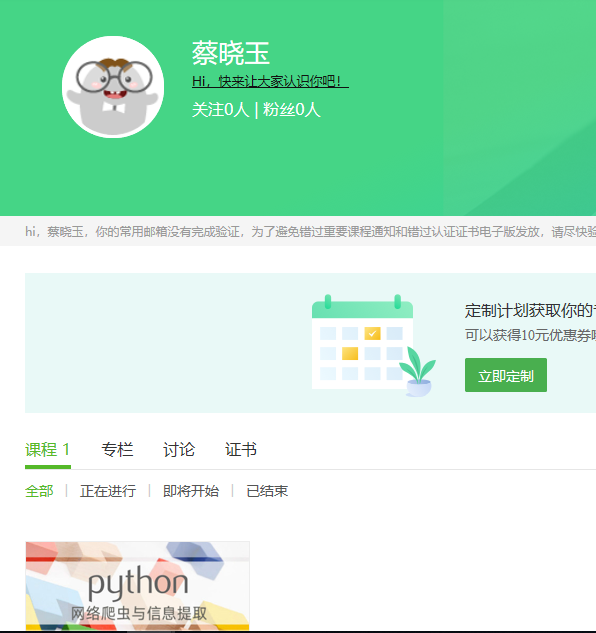
3.学习完成第0周至第4周的课程内容,并完成各周作业
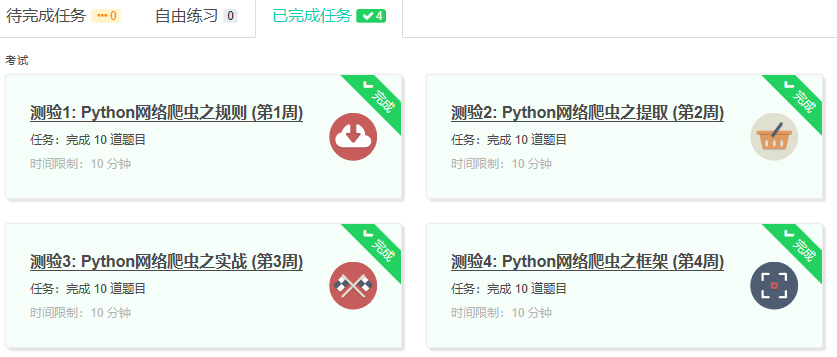
4.提供图片或网站显示的学习进度,证明学习的过程。


5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
在老师的介绍下第一次接触到了中国大学生慕课,通过此次对于《Python网络爬虫与信息提取》这门课的学习,让我对于Python有了更加深入的了解。刚开始接触到“爬虫”这个名词时充满了疑惑,不知道是什么东西,通过这几周的学习之后对于“爬虫”有了新的认识和感受。网络爬虫又被称为网页蜘蛛,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。这门课主要介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授了构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy。
在第一周的课程中我学习到了requests库的7个主要方法:requests.requests(): 构造一个请求,支撑以下各方法的基础方法;requests.get(): 获取HTML网页的主要方法,对应于HTTP的GET;requests.head(): 获取HTML网页头信息的方法,对应于HTTP的HEAD; requests.post(): 向HTML网页提交post请求的方法,对应于HTTP 的POST;requests.put(): 向HTML网页提交PUT请求的方法,对应于HTTP的PUT;requests.patch(): 向HTML网页提交局部修改请求,对应于HTTP的PATCH; requests.delete(): 向HTML页面提交删除请求,对应于HTTP的DELETE。通过学习让我知道了requests库是同步请求,也就是从发出请求到收到响应,它使用起来也比较方便,可以节省我们大量的工作时间,完全的满足HTTP的测试需求,给我们带来了便利。
之后我还了解到了scrapy框架,它是一个快速功能强大的网络爬虫框架。常用的命令有:startproject创建一个新工程(scrapy startproject<name> [dir]);genspider创建一个爬虫(scrapy genspider [options] <name> <domain>);settings获得爬虫配置信息(scrapy settings [options]);crawl运行一个爬虫(scrapy crawl <spider>);list列出工程中所有爬虫(scrapy list);shell启动URL调试命令行(scrapy shell [url]);scrapy是一种具有持续爬取,商业服务,高可靠性的功能和特点,而且是Python语言中最好的爬虫框架,可以具备千万级URL爬取管理与部署,是一种爬虫能力很强的框架,具备企业级专业爬虫的扩展性,可以很好的在企业中进行使用。
这几周的课程学习让我对网络数据爬取和网页解析的基本能力有了一个详细的梳理,从Requests自动爬取HTML页面自动网络请求提交→Robots.txt网络爬虫排除标准→Beautiful Soup解析HTML页面→Re正则表达式详解提取页面关键信息→scrapy框架。从requests库到scrapy框架的学习,让我意识到了Python的学习是一个漫长的过程,包含了许许多多的知识点,需要掌握的东西也很多,也让我感受到了爬虫在我们的日常生活中的重要性,现如今是互联网的时代,而网络爬虫已经成为自动获取互联网数据的一种主要方式,Python对于我们学习和工作都起到了很重要的作用,大大的降低了我们的时间,更快更好的对信息进行提取。接下来我会继续对Python网络爬虫与信息提取这门课程的学习,跟随老师的步伐,加深对知识点的学习与巩固,相信未来的某一天会对我们产生很大的帮助。
