
Java进阶 - 线程池、Lambda、File类、过滤器
1.线程池
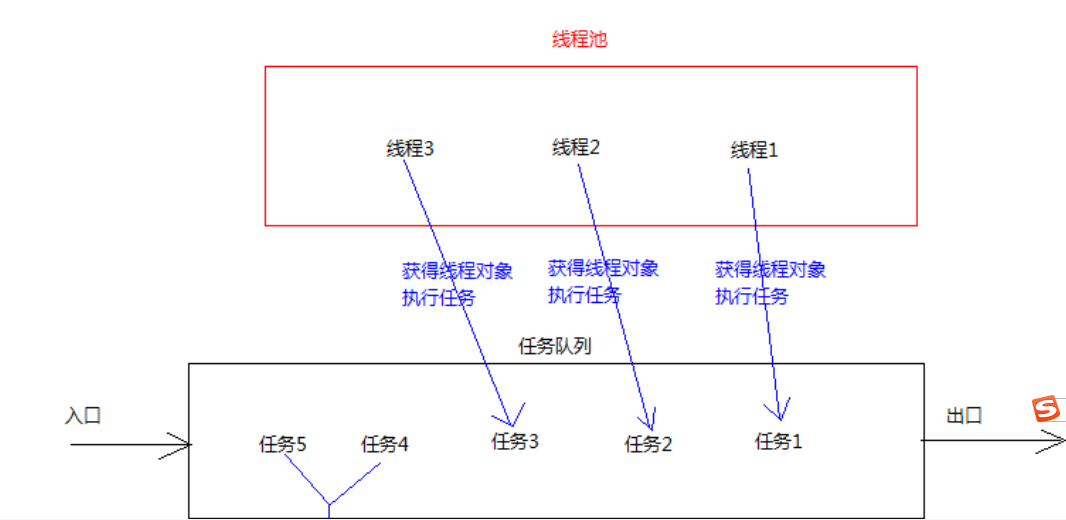
合理利用线程池能够带来三个好处:
1. 降低资源消耗。减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2. 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
3. 提高线程的可管理性。可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内
存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
Executors类中有个创建线程池的方法如下:
public static ExecutorService newFixedThreadPool(int nThreads) :返回线程池对象。(创建的是有界线
程池,也就是池中的线程个数可以指定最大数量)
使用步骤:
1.使用Executors工厂函数的newFixedThreadPool静态方法获取线程池对象
2.创建Runnable的实现类设置线程任务
3.调用线程池的submit方法开启一个线程
4.关闭线程(不建议使用)
主方法: public class DemoThreadPool { public static void main(String[] args) { ExecutorService es = Executors.newFixedThreadPool(2); es.submit(new RunImpl()); es.submit(new RunImpl()); es.submit(new RunImpl()); } } Run实现类: public class RunImpl implements Runnable { @Override public void run() { System.out.println(Thread.currentThread().getName()+"创建了一个新的线程"); } }
2.Lambda表达式
public class DemoLambda { public static void main(String[] args) { new Thread(()->{ System.out.println(Thread.currentThread().getName()); } ).start(); } }
练习,按年龄排序
public class DemoLambda { public static void main(String[] args) { Person p1 = new Person("chris",21); Person p2 = new Person("joe",20); Person p3 = new Person("Lin",23); Person[] pgroup = new Person[]{p1,p2,p3}; //按照年龄对该数组排序 /* Arrays.sort(pgroup, new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { return o1.getAge() - o2.getAge(); //升序排序 } });*/ //使用lambda表达式 Arrays.sort(pgroup, (Person o1,Person o2)->{ return o1.getAge()-o2.getAge(); }); //遍历数组 for (Person person : pgroup) { System.out.println(person); } } }
此时Comparator对象就不用匿名内部类来产生
省略规则
在Lambda标准格式的基础上,使用省略写法的规则为:
1. 小括号内参数的类型可以省略;
2. 如果小括号内有且仅有一个参,则小括号可以省略;
3. 如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。(三者必须一起省略)
Arrays.sort(pgroup, (Person o1,Person o2)->{ return o1.getAge()-o2.getAge(); }); 变为: Arrays.sort(pgroup, (Person o1,Person o2)-> o1.getAge()-o2.getAge()); new Thread(()-> System.out.println(Thread.currentThread().getName()));
可推倒既可省略,在JDK1.7之后,ArrayList集合后面的泛型可以省略
ArrayList<Person> array = new ArrayList<>();
Lambda的使用前提
1. 使用Lambda必须具有接口,且要求接口中有且仅有一个抽象方法。
无论是JDK内置的 Runnable 、 Comparator 接口还是自定义的接口,只有当接口中的抽象方法存在且唯一时,才可以使用Lambda。
2. 使用Lambda必须具有上下文推断。
也就是方法的参数或局部变量类型必须为Lambda对应的接口类型,才能使用Lambda作为该接口的实例。
备注:有且仅有一个抽象方法的接口,称为“函数式接口”
3.File类
路径分隔符:Windows系统:分号; Linux系统:冒号:
文件名称分隔符:Windows系统:反斜杠 \ Linux系统:正斜杠 /
以后操作路径不能写死:"+File.separator+"
D:\Baseball\_notes
变为:
"D:"+File.separator+"Baseball"+File.separator+"_notes"
绝对路径和相对路径:
绝对路径:是一个完整的路径
以盘符(c:d:)开始的路径,如D:\Baseball\_notes
相对路径:是一个简化路径
相对指的是相对于当前项目的根目录
如果使用当前项目的根目录,则可以省略
注意:路径不区分大小写,Windows路径中的文件名称分隔符是反斜杠,反斜杠是转义字符,所以要用两个反斜杠表示一个反斜杠
构造方法
public File(String pathname) :通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
public File(String parent, String child) :从父路径名字符串和子路径名字符串创建新的 File实例。
public File(File parent, String child) :从父抽象路径名和子路径名字符串创建新的 File实例。
4.File类获取的方法
public String getAbsolutePath() :返回此File的绝对路径名字符串。不管是绝对路径还是相对路径,都返回绝对路径
public String getPath() :将此File转换为路径名字符串。是相对路径就返回相对路径
public String getName() :返回由此File表示的文件或目录的名称。返回的就是路径结尾的文件名
public long length() :返回由此File表示的文件的长度。返回指定文件的大小,以字节为单位,如果给出的路径不存在,则返回0
5.File类判断功能的方法
public boolean exists() :此File表示的文件或目录是否实际存在。
public boolean isDirectory() :此File表示的是否为目录。
public boolean isFile() :此File表示的是否为文件。
6.File类创建删除文件的方法
public boolean createNewFile() :当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。声明抛出了IO异常,需要进行处理,路径不存在则会抛出异常
public boolean delete() :删除由此File表示的文件或目录。不走回收站,直接走硬盘,需谨慎!!
public boolean mkdir() :创建由此File表示的目录。创建单级文件夹
public boolean mkdirs() :创建由此File表示的目录,包括任何必需但不存在的父目录。既可以创建单级文件夹,也可以创建多级文件夹,若路径不存在,不会报错,但不会创建
public class DemoFile { public static void main(String[] args) { File f1 = new File("D:\\JA\\Part1-basic\\a.txt"); try { f1.createNewFile(); } catch (IOException e) { e.printStackTrace(); } File f2 = new File("D:\\JA\\Part1-basic\\a.txt"); f2.delete(); } }
7.File类遍历
public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。
public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。File数组存储的是多个File对象
如果构造方法中给出的路径不存在或给出的不是一个目录,会抛出空指针异常
public class DemoFile { public static void main(String[] args) { File f1 = new File("D:\\JA"); //获取目录文件的字符串数组 String[] array = f1.list(); for (String filename : array) { System.out.println(filename); } } }
练习:递归打印多级目录
public class DemoFile { public static void main(String[] args) { //递归打印多级目录 File f1 = new File("D:\\Baseball"); getAllFiles(f1); } public static void getAllFiles(File dir){ File[] files = dir.listFiles(); for (File file : files) { System.out.println(file); //判断是否是文件夹,是的话继续递归遍历 if(file.isDirectory()){ getAllFiles(file); } } } }
搜索以某后缀名结尾的文件:
public class DemoFile { public static void main(String[] args) { //递归打印多级目录 File f1 = new File("D:\\Baseball"); getAllFiles(f1); } public static void getAllFiles(File dir){ File[] files = dir.listFiles(); for (File file : files) { //判断是否是文件夹,是的话继续递归遍历 if(file.isDirectory()){ getAllFiles(file); } //对文件结尾进行判断 if(file.getName().toLowerCase().endsWith(".html")){ System.out.println(file);} } } }
8.文件过滤器FileFilter
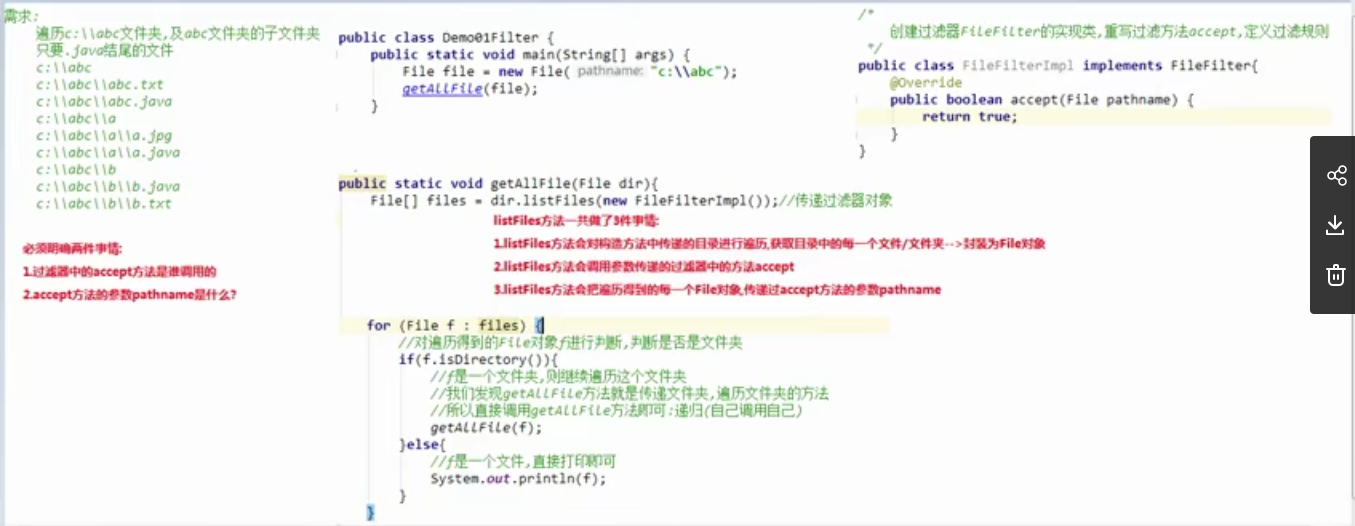
ListFiles方法一共做了3件事情:
(1)listFiles方法会对构造方法中传递的目录进行遍历,获取目录中的每一个文件/文件夹 - - > 每个都封装成File对象
(2)listFiles方法会调用参数传递的过滤器中的方法accept
(3)listFiles方法会把遍历得到的每一个File对象传递给accept方法的参数pathname
Accept方法的返回值是一个布尔值
如果返回的是true,就会把传递的FIle对象保存到File数组中,false就不会
主方法: public class DemoFile { public static void main(String[] args) { //递归打印多级目录 File f1 = new File("D:\\Baseball"); getAllFiles(f1); } public static void getAllFiles(File dir) { File[] files = dir.listFiles(new FileFilterImpl()); //传递过滤器对象 for (File file : files) { //判断是否是文件夹,是的话继续递归遍历 if (file.isDirectory()) { System.out.println(file); getAllFiles(file); } else { System.out.println(file); } } } } 过滤器实现类: public class FileFilterImpl implements FileFilter { //重写FileFilter方法,定义过滤规则 @Override public boolean accept(File pathname) { //如果pathname是一个文件夹,返回true,让它递归遍历 if(pathname.isDirectory()){ return true; } //看是否以html结尾 return pathname.getName().toLowerCase().endsWith(".html"); } }
使用lamda表达式优化:
public class DemoFile { public static void main(String[] args) { //递归打印多级目录 File f1 = new File("D:\\Baseball"); getAllFiles(f1); } public static void getAllFiles(File dir) { //使用lambda表达式优化 File[] files = dir.listFiles((pathname)-> pathname.isDirectory() || pathname.getName().toLowerCase().endsWith("html")); for (File file : files) { //判断是否是文件夹,是的话继续递归遍历 if (file.isDirectory()) { getAllFiles(file); } else { System.out.println(file); } } } }

