
Java进阶 - 数据结构、List、Set、Collections工具类
1.常用的几种结构
数据存储的常用结构有:栈、队列、数组、链表和红黑树
(1)栈
-
栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
-
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
-
栈的入口、出口的都是栈的顶端位置。
这里两个名词需要注意:
-
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
-
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。

(2)队列
-
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
-
队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。

(3)数组
-
数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
查找元素快:通过索引,可以快速访问指定位置的元素

-
增删元素慢
-
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图
-
指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图
-

(4)链表
-
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
多个节点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
-
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
-
增删元素快:
-
增加元素:只需要修改连接下个元素的地址即可。
-
删除元素:只需要修改连接下个元素的地址即可。
-

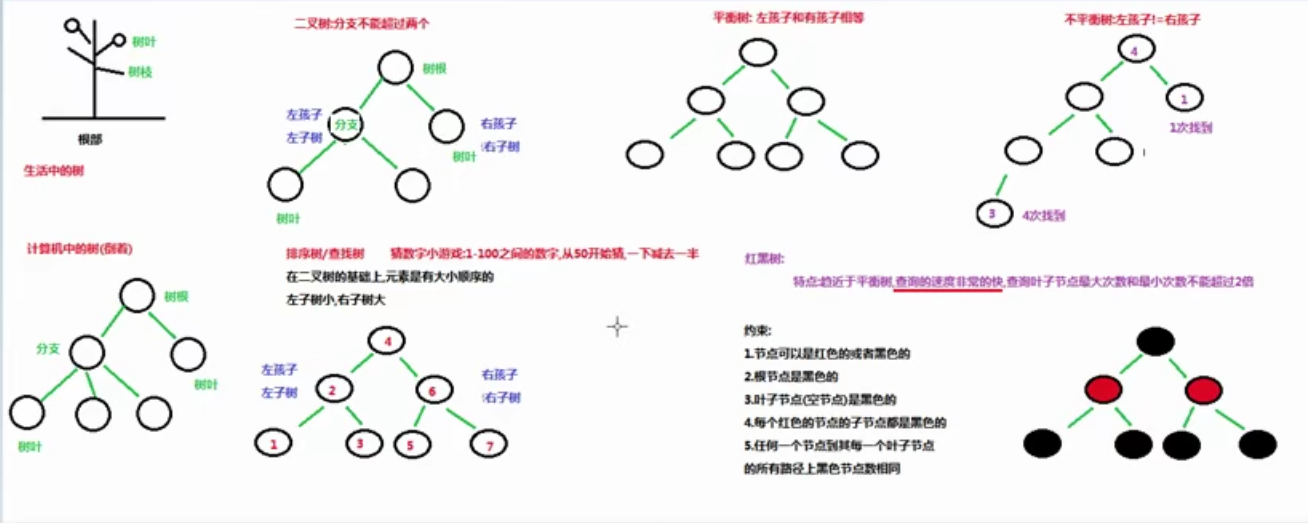
(5)红黑树
-
二叉树:binary tree ,是每个结点不超过2的有序树(tree) 。
简单的理解,就是一种类似于我们生活中树的结构,只不过每个结点上都最多只能有两个子结点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。
如图:
我们要说的是二叉树的一种比较有意思的叫做红黑树,红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
红黑树的约束:
-
节点可以是红色的或者黑色的
-
根节点是黑色的
-
叶子节点(特指空节点)是黑色的
-
每个红色节点的子节点都是黑色的
-
任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点:
速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
2.List集合
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。在List集合中允许出现重复的元素,所有的元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的指定元素。另外,List集合还有一个特点就是元素有序,即元素的存入顺序和取出顺序一致。
看完API,我们总结一下:
List接口特点:
-
它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
-
集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
特有方法:(操作索引的时候,一定要防止索引越界异常)
-
-
public E get(int index):返回集合中指定位置的元素。 -
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。 -
public E set(int index, E element)


public static void main(String[] args) { // 创建List集合对象 List<String> list = new ArrayList<String>(); // 往 尾部添加 指定元素 list.add("图图"); list.add("小美"); list.add("不高兴"); System.out.println(list); // add(int index,String s) 往指定位置添加 list.add(1,"没头脑"); System.out.println(list); // String remove(int index) 删除指定位置元素 返回被删除元素 // 删除索引位置为2的元素 System.out.println("删除索引位置为2的元素"); System.out.println(list.remove(2)); System.out.println(list); // String set(int index,String s) // 在指定位置 进行 元素替代(改) // 修改指定位置元素 list.set(0, "三毛"); System.out.println(list); // String get(int index) 获取指定位置元素 // 跟size() 方法一起用 来 遍历的 for(int i = 0;i<list.size();i++){ System.out.println(list.get(i)); } //还可以使用增强for for (String string : list) { System.out.println(string); } } }
3.
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
-
public void addFirst(E e):将指定元素插入此列表的开头。 -
public void addLast(E e):将指定元素添加到此列表的结尾。 -
public E getFirst():返回此列表的第一个元素。 -
public E getLast():返回此列表的最后一个元素。 -
public E removeFirst():移除并返回此列表的第一个元素。 -
public E removeLast():移除并返回此列表的最后一个元素。 -
public E pop():从此列表所表示的堆栈处弹出一个元素。 -
public void push(E e):将元素推入此列表所表示的堆栈。 -
public boolean isEmpty():如果列表不包含元素,则返回true。

LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。(了解即可)
4.Set集合 set集合使用add时会使用hashCode和equals方法先,所以不会存储重复的元素
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection
Set集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet这两个集合。
HashSet集合
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持,由于我们暂时还未学习,先做了解。
HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
public class HashSetDemo { public static void main(String[] args) { //创建 Set集合 HashSet<String> set = new HashSet<String>(); //添加元素 set.add(new String("cba")); set.add("abc"); set.add("bac"); set.add("cba"); //遍历 for (String name : set) { System.out.println(name); } } }
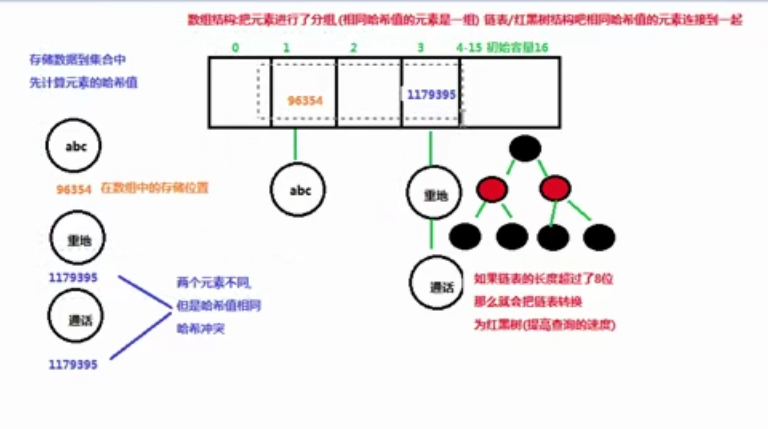
HashSet集合存储数据的结构(哈希表)
哈希值:是一个十进制的整数,由系统随机给出(就是对象的地址值,是一个逻辑地址,是模拟出来的地址,不是数据实际存储的物理地址)
在Object类中有一个方法,可以获取对象的哈希值 hasCode 由操作系统随机生成 String类重写了hashCode 方法 其中 重地 和 通话 两个词语的值相同
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一
public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, age); } }
5.LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。
6.可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化成如下格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }
其实这个书写完全等价与
修饰符 返回值类型 方法名(参数类型[] 形参名){ }
只是后面这种定义,在调用时必须传递数组,而前者可以直接传递数据即可。
JDK1.5以后。出现了简化操作。... 用在参数上,称之为可变参数。
同样是代表数组,但是在调用这个带有可变参数的方法时,不用创建数组(这就是简单之处),直接将数组中的元素作为实际参数进行传递,其实编译成的class文件,将这些元素先封装到一个数组中,在进行传递。这些动作都在编译.class文件时,自动完成了。
public class ChangeArgs { public static void main(String[] args) { int[] arr = { 1, 4, 62, 431, 2 }; int sum = getSum(arr); System.out.println(sum); // 6 7 2 12 2121 // 求 这几个元素和 6 7 2 12 2121 int sum2 = getSum(6, 7, 2, 12, 2121); System.out.println(sum2); } /* * 完成数组 所有元素的求和 原始写法 public static int getSum(int[] arr){ int sum = 0; for(int a : arr){ sum += a; } return sum; } */ //可变参数写法 public static int getSum(int... arr) { int sum = 0; for (int a : arr) { sum += a; } return sum; } }
注意:如果在方法书写时,这个方法拥有多参数,参数中包含可变参数,可变参数一定要写在参数列表的末尾位置
终极写法 (Object...obj)接收一切数量,一切类型的参数
7.Collections工具类
-
-
public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序。 -
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。 -
public static <T> void sort(List<T> list,Comparator<? super T> )
基本使用:
public class DemoCollections { public static void main(String[] args) { LinkedList<Integer> list = new LinkedList<>(); list.add(2); list.add(4); list.add(6); Collections.addAll(list,8,12,24); //加入多个元素 System.out.println(list); Collections.shuffle(list); //打乱集合中的顺序 System.out.println(list); Collections.sort(list); //排序,默认按升序 System.out.println(list); } }
排序自定义类: 注意:sort方法的前提: 被排序的集合里边的存储元素,必须实现Comparable,重写接口中的CompareTo定义排序的规则
Comparable接口的排序规则:
自己(this) - 参数:升序 反之 则降序
package basicpart.day01.DataStructure; public class Person implements Comparable<Person>{ private String name ; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } //重写排序的规则 @Override public int compareTo(Person o) { //自定义比较的规则,比较两个人的年龄 return this.getAge() - o.getAge();//年龄升序排序 } }
Comparator
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparator强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构(如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
基本使用: 在sort中定义匿名内部类Comparator,重写compare方法
ArrayList<Integer> in = new ArrayList<>(); Collections.addAll(in,24,54,23,66); Collections.sort(in, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1 - o2; //升序 // return o2 - o1; //降序 } }); System.out.println(in); //自定义类按照年龄降序排序 Collections.sort(list, new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { return o2.getAge() - o1.getAge(); } }); System.out.println(list);
多重规则:
//自定义类按照年龄升序排序 Collections.sort(list, new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { int result = o1.getAge() - o2.getAge(); //如果两个人年龄相同,按照名字首字母排序 if (result == 0){ result = o1.getName().charAt(0) - o2.getName().charAt(0); } return result; } }); System.out.println(list);

