Elasticsearch搜索
框架概述
一个主流的搜索框架
业务需求
需要模糊搜索数据库里多张表的所有数据
技术选型和架构设计
在服务器中安装Elasticsearch中间件,在java项目中引入对应jar包,调用jar包中的API将mysql的数据同步到Elasticsearch,最后使用jar包中的API调用Elasticsearch的增删改及搜索服务。
版本对应
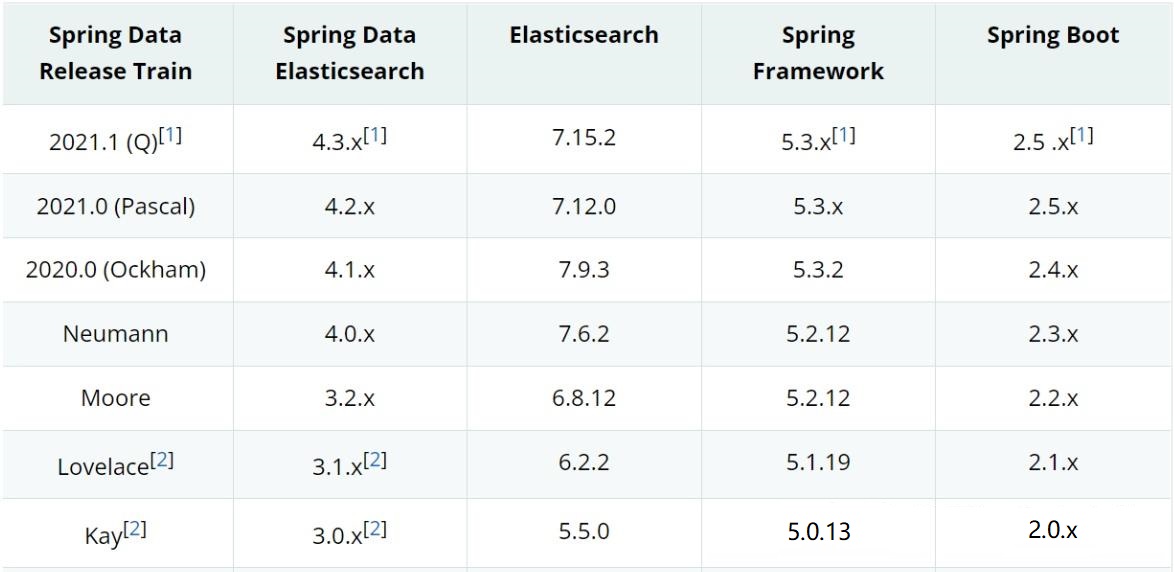
另附官网参考:https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/versions.html
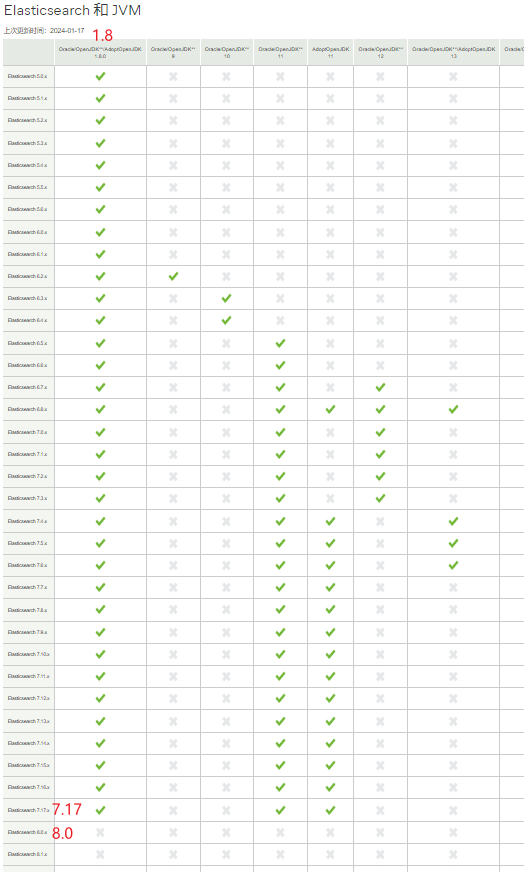
另附官网参考:https://www.elastic.co/cn/support/matrix#matrix_jvm
Elasticsearch(简称ES)的安装、配置、使用与删除
码神之路B站视频 https://www.bilibili.com/video/BV17v411V76S?p=1&vd_source=38f14506b4ac32b899b010f24c1ab966
Elasticsearch安装
#查看服务器是否有docker,若输出版本号则有,提示not found则没有,需要安装docker(方法见下方链接)
docker -v
##下载es的镜像(docder中没有7.15.2,有7.12.0和7.12.1等)
docker pull elasticsearch:7.12.1
##创建es的容器 并启动 single-node单机
##docker run指定容器中的某端口映射到宿主机的某端口的命令是:docker run -p <宿主机端口>:<容器内部端口> <镜像名称>
docker run -d --name es -p 92xx:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.12.1
##在浏览器中打开以下地址测试(如果服务器部署在云,则需要在服务商的安全组配置中开启端口92xx)
http://47.99.xx.xx:92xx/
Elasticsearch配置和使用
linux上docker中的ES的怎么重启、启动、关闭和配置端口号?
##关闭ES
##查看容器ID或名词
docker ps -a
##根据所获得的容器ID或名词,关闭容器
docker stop <容器ID或名称>
##如果你想充分停止和删除容器,可以使用docker rm命令,以删除容器资源,这样会清除所有数据
docker rm <容器ID或名称>
##如果你想保留旧容器的数据,可以在启动新容器时指定一个新的名称。-d表示后台运行,--name用于指定新的容器名称
docker start -d --name new_container_name old_container_name
修改Elasticsearch的配置文件elasticsearch.yml,将端口号9200修改为92xx
- 进入docker容器查找elasticsearch.yml配置文件,并修改
#使用es容器92xx端口映射到宿主机92xx端口的方式启动容器
# docker run -d --name es -p 92xx:92xx -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.12.1
#进入docker容器查找elasticsearch.yml配置文件,并修改
##查找es容器id
docker ps -a
##进入docker容器(容器是运行的状态)
docker exec -it <容器ID或名称> /bin/bash
##使用vi进入文件,按i编辑文件,按Esc退出编辑并:wq保存 http.port: 92xx 是端口号配置项
vi config/elasticsearch.yml
##退出容器
exit
#重启容器
docker restart <容器ID或名称>
- 直接在宿主机查找elasticsearch.yml配置文件,并修改
# 直接在宿主机查找elasticsearch.yml配置文件
find / -name elasticsearch.yml 2>/dev/null
# 使用vi进入文件,按i编辑文件,按Esc退出编辑并:wq保存 http.port: 92xx 是端口号配置项
vi config/elasticsearch.yml
# 重启容器
docker restart <容器ID或名称>
Elasticsearch设置密码和删除密码
参考:https://blog.csdn.net/kaysenliang/article/details/121171419 和 https://blog.csdn.net/cold___play/article/details/133956073
Elasticsearch配置账号和密码的详细步骤如下:
-
进入es的docker容器
docker exec -it <容器ID或名称> /bin/bash进入后的当前目录即为Elasticsearch安装目录
-
修改配置文件:
-
首先,找到Elasticsearch的配置文件
elasticsearch.yml,通常位于Elasticsearch安装目录下的config文件夹中。 -
打开
elasticsearch.yml文件,并添加或修改以下配置(启用X-Pack安全特性):xpack.security.enabled: true -
配置重启生效
# 在Elasticsearch安装目录下输入以下命令,停止es,且退出docker容器 ./bin/elasticsearch -d # 在宿主机查询es的容器的id或名称, docker ps # 启动es容器 docker start <容器ID或名称>
-
-
设置密码:
-
进入重启后的es容器,导航到Elasticsearch的安装目录的
bin文件夹。# 进入重启后的es容器 docker exec -it <容器ID或名称> /bin/bash # 导航到Elasticsearch的安装目录的bin文件夹 cd bin -
执行以下命令来设置密码:
elasticsearch-setup-passwords interactive -
这个命令会提示你为不同的内置用户设置密码。这些用户包括:elastic、kibana、logstash_system、beats_system。
-
为每个用户输入一个强密码,并记住这些密码,因为稍后需要用它们来访问Elasticsearch和Kibana。
-
其中,elastic账号是内置的超级用户,拥有superuser角色,可以执行任何操作。
-
每个用户的密码输入2次,交互流程如下(交互完成后输入exit退出es容器):
future versions of Elasticsearch will require Java 11; your Java version from [/kaysen/tools/java/jre] does not meet this requirement Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user. You will be prompted to enter passwords as the process progresses. Please confirm that you would like to continue [y/N]y Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana]: Reenter password for [kibana]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]: Enter password for [remote_monitoring_user]: Reenter password for [remote_monitoring_user]: Changed password for user [apm_system] Changed password for user [kibana] Changed password for user [logstash_system] Changed password for user [beats_system] Changed password for user [remote_monitoring_user] Changed password for user [elastic]
-
-
验证配置:
-
重新启动Elasticsearch服务,使配置生效。
# 在宿主机查询es的容器的id或名称, docker ps # 启动es容器 docker restart <容器ID或名称> -
使用新设置的用户名和密码,尝试连接到Elasticsearch和Kibana,确保一切正常。
- 本地浏览器访问http://47.99.xx.xx:92xx/,弹窗提示输入账号密码,输入后看到服务器返回的es版本等信息,则配置成功。
请注意,以上步骤假设您已经正确安装了Elasticsearch,并且具有适当的权限来修改配置文件和执行命令。此外,这些步骤可能因Elasticsearch的版本和安装环境而有所不同。
-
-
修改密码
进es容器在当前目录即Elasticsearch的安装目录下:
bin/elasticsearch-users passwd elastic在以上命令中,elastic是要修改密码的用户名。执行完命令后,输入新密码即可完成密码修改。
rest api:
curl -H "Content-Type:application/json" -XPOST -u elastic 'http://127.0.0.1:9200/_xpack/security/user/elastic/_password' -d '{ "password" : "123456" }' -
忘记密码处理
修改elasticsearch.yml 配置,将身份验证相关配置屏蔽掉,重启ES,查看下索引,发现多了一个.security-7索引,将其删除,到此就回到ES没有设置密码的阶段了,如果想重新设置密码,请重新开始。
-
在代码中携带账号密码请求链接(或者在项目配置文件中配置)
见下方的低级客户端的创建连接 创建连接
Elasticsearch的删除
要停止并删除一个运行的 Elasticsearch 容器,以及删除下载的镜像,可以按照以下步骤进行操作:
首先,使用以下命令查看正在运行的容器:
docker ps
这将列出所有正在运行的容器。找到 Elasticsearch 容器的 ID 或名称。
使用以下命令停止正在运行的容器,将 <container-id> 替换为 Elasticsearch 容器的 ID 或名称:
docker stop <container-id>
停止容器后,可以使用以下命令删除该容器:
docker rm <container-id>
这将彻底删除容器。
最后,使用以下命令列出已下载的镜像:
docker images
找到 Elasticsearch 镜像(如 elasticsearch:7.12.1)的仓库(REPOSITORY)和标签(TAG) 。
使用以下命令删除已下载的镜像,将 <image-name>:<tag> 替换为 Elasticsearch 镜像的仓库和标签:
docker rmi <image-name>:<tag>
这将彻底删除镜像。
请注意,删除容器和镜像是永久性的操作,请确保你不再需要它们之前进行删除。同时还要注意,如果你有其他容器或镜像依赖于 Elasticsearch 容器或镜像,删除操作可能会产生错误或导致这些依赖的中断。在删除之前,请确保你了解相关的容器和镜像之间的依赖关系,并在必要时进行调整。
查看ES日志
# 直接在宿主机查找elasticsearch.log日志文件
find / -name elasticsearch.log 2>/dev/null
# 容器中的es日志文件,如果你不是以root用户身份登录,可能需要在命令最前面添加sudo来获取必要的权限
cat /var/log/elasticsearch/elasticsearch.log
# 或者进入
# 容器中的es日志文件,查看最后100行(如果你不是以root用户身份登录,可能需要使用sudo命令来获取必要的权限)
tail -n 100 /var/log/elasticsearch/elasticsearch.log
# 容器中的es日志文件,使用grep命令搜索特定关键字
grep "error" /var/log/elasticsearch/elasticsearch.log
# 容器中的es日志文件,使用less或more命令分页查看
less /var/log/elasticsearch/elasticsearch.log
kibana(ES的图形化客户端)的安装与配置
##下载kibana的镜像
docker pull kibana:7.12.1
##准备kibana的配置文件
docker inspect es的容器id(docker ps -a 查看)
## 找到 "IPAddress": "172.17.0.2" 找出es对应的容器ip地址
## 找到上个命令输出的es文件中的"IPAddress":"172.17.0.2",即es对应的容器ip地址,然后在kibana的配置文件中进行修改
## 可以直接修改容器上的/usr/share/kibana/config/kibana.yml文件
## 去除文件映射配置启动docker,进入docker修改/usr/share/kibana/config/kibana.yml,退出,重启docker
## Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://172.17.0.2:92xx" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
##启动kibana
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5611:5601 -v /opt/docker/es/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.12.1
##在浏览器中打开以下地址测试
http://47.99.xx.xx:5611/
##在浏览器打开的kibana页面中的Dev Tools标签页中输入以下命令,点击▷运行,获取所有数据
GET _search
{
"query": {
"match_all": {}
}
}
kibana操作elasticsearch(增删改查):https://blog.csdn.net/mo_sss/article/details/133808562
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5611:5601 -v /opt/docker/es/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.12.1 这句命令每一个部分的详细意思是什么?
这个
docker run命令用于启动一个新的 Docker 容器,并配置该容器的各种参数。下面我会逐一解释这个命令中的每个部分:
- docker run - 这是 Docker 的一个基本命令,用于启动新的容器。
- -d - 该标志意味着“后台运行”(detached mode)。当你使用这个标志时,Docker 会启动容器并在后台运行,不会阻塞命令行界面。
- --restart=always - 这个标志意味着无论容器的退出状态如何,Docker 都会尝试自动重启它。这对于确保服务始终运行非常有用,特别是在容器崩溃或宿主机重启时。
- --log-driver json-file - 这指定了容器的日志驱动为
json-file。json-file驱动会将容器的日志写入 JSON 格式的文件中。- --log-opt max-size=100m - 这是一个与
json-file日志驱动相关的选项,它限制了单个日志文件的最大大小为 100MB。当日志文件达到这个大小时,Docker 会开始写入一个新的日志文件。- --log-opt max-file=2 - 这也是与
json-file日志驱动相关的选项,它限制了可以保留的日志文件的最大数量为 2。当达到这个数量时,最旧的日志文件将被删除。- --name kibana - 这为容器指定了一个名称,即 "kibana"。这样,你可以通过名称而不是默认的随机 ID 来引用或管理容器。
- -p 5611:5601 - 这是端口映射。它告诉 Docker 将宿主机的 5611 端口映射到容器的 5601 端口。这意味着,当你访问宿主机的 5611 端口时,你实际上是在访问容器内的 5601 端口。
- -v /opt/docker/es/kibana.yml:/usr/share/kibana/config/kibana.yml - 这是一个卷映射。它告诉 Docker 将宿主机的
/opt/docker/es/kibana.yml文件映射到容器内的/usr/share/kibana/config/kibana.yml文件。这允许你覆盖容器内的默认配置文件。- kibana:7.12.1 - 这指定了要运行的 Docker 镜像的名称和标签。在这里,你正在运行名为 "kibana" 且版本为 "7.12.1" 的 Docker 镜像。
综上所述,这个命令启动了一个名为 "kibana" 的 Docker 容器,使用 "kibana:7.12.1" 镜像,并在后台运行。容器配置为自动重启,并使用
json-file日志驱动来记录日志,每个日志文件最大为 100MB,最多保留 2 个日志文件。容器内的 5601 端口映射到宿主机的 5611 端口,并且容器的默认配置文件被宿主机的/opt/docker/es/kibana.yml文件覆盖。
SpringBoot整合spring data Elasticsearch和高级客户端
来自码神之路:https://www.mszlu.com/java/springboot/04/04.html#_5-springboot整合es
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
常用注解说明
-
@Document(indexname,type)
indexname:相当于mysql中数据库的概念,字母要小写
type:相当于mysql中表的概念
-
@id
相当于mysql中表的主键的概念
-
@Field(FieldType)
FieldType:相当于mysql中字段的类型的概念
FieldType的枚举值有:
Text,//会进行分词并建了索引的字符类型
Integer,
Long,
Date,
Float,
Double,
Boolean,
object,
Auto,//白动判断字段类型
Nested,//嵌套对象类型
Ip,
Attachment,
Keyword//不会进行分词建立索引的类型
ES在springBoot中的配置
写在springBoot项目的application.yml中,http://192.168.200.100:9200为服务器上ES发布的服务。
#es的配置
#通过继承ElasticsearchRepository类的方式来实现CRUD,所连接的端口
spring.elasticsearch.rest.uris=http://47.99.xx.xx:92xx
#开启Elasticsearch仓库
spring.data.elasticsearch.repositories.enabled=true
#通过声明ElasticsearchRestTemplate然后调用其中的方法来实现CRUD,所链接的端口
spring.data.elasticsearch.client.reactive.endpoints=47.99.xx.xx:92xx
通过回车的形式配置:
spring:
#es的配置
elasticsearch:
rest:
uris: http://47.99.xx.xx:92xx
data:
elasticsearch:
repositories:
enabled: true
client:
reactive:
endpoints: 47.99.xx.xx:92xx
ES的CRUD代码
spring data Elasticsearch中也有两种编码方式。一种是继承ElasticsearchRepository然后在类中按命名规则写方法,在需要用到的地方注入这个接口然后调用方法,会自动实现CRUD。一种是需要用到的地方注入ElasticsearchRestTemplate然后调用其中的方法来实现CRUD。
1. 继承ElasticsearchRepository来实现CRUD方法
下文这个ArticleRepository接口绑定了对Article这个对象的操作
Page和Pageable是springData统一的分页功能
SearchMaterialRepository
package com.mszlu.union.domain.repository;
import com.mszlu.union.model.es.Article;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.annotations.Query;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ArticleRepository extends ElasticsearchRepository<Article,String> {
//根据作者名称 搜索
Page<Article> findByAuthorsName(String name, Pageable pageable);
//搜索title字段
Page<Article> findByTitleIsContaining(String word,Pageable pageable);
Page<Article> findByTitle(String title,Pageable pageable);
}
2. 新增实体类
相当于存储进ES中的索引结构
package com.mszlu.union.model.es;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.List;
//注意indexName要小写
@Document(indexName = "blog")
@Data
public class Article {
@Id
private String id;
private String title;
@Field(type = FieldType.Nested, includeInParent = true)
private List<Author> authors;
public Article(String title) {
this.title = title;
}
}
public class Author {
private String name;
public Author(String name) {
this.name = name;
}
}
3. 编写测试用例
保存(继承ElasticsearchRepository的方式)
package com.mszlu.union.service;
import com.alibaba.fastjson.JSON;
import com.mszlu.union.domain.repository.ArticleRepository;
import com.mszlu.union.model.es.Article;
import com.mszlu.union.model.es.Author;
import org.checkerframework.checker.units.qual.A;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.Query;
import java.util.Arrays;
import static java.util.Arrays.asList;
import static org.elasticsearch.index.query.QueryBuilders.regexpQuery;
@SpringBootTest
public class ESTest {
@Autowired
private ArticleRepository articleRepository;
//新增
@Test
public void save(){
Article article = new Article("Spring Data Elasticsearch");
article.setAuthors(asList(new Author("god"),new Author("John")));
articleRepository.save(article);
article = new Article("Spring Data Elasticsearch2");
article.setAuthors(asList(new Author("god"),new Author("King")));
articleRepository.save(article);
article = new Article("Spring Data Elasticsearch3");
article.setAuthors(asList(new Author("god"),new Author("Bill")));
articleRepository.save(article);
}
}
查询(继承ElasticsearchRepository的方式)
@Test
public void queryAuthorName() {
Page<Article> articles = articleRepository.findByAuthorsName("chali", PageRequest.of(0,10));
for (Article article : articles.getContent()) {
System.out.println(article);
for (Author author : article.getAuthors()) {
System.out.println(author);
}
}
}
更新(继承ElasticsearchRepository的方式)
@Test
public void update() {
Page<Article> articles = articleRepository.findByTitle("Spring Data Elasticsearch",PageRequest.of(0,10));
Article article = articles.getContent().get(0);
System.out.println(article);
System.out.println(article.getAuthors().get(0));
Author author = new Author("chali");
article.setAuthors(Arrays.asList(author));
articleRepository.save(article);
}
删除(继承ElasticsearchRepository的方式)
@Test
public void delete(){
Page<Article> articles = articleRepository.findByTitle("Spring Data Elasticsearch",PageRequest.of(0,10));
Article article = articles.getContent().get(0);
articleRepository.delete(article);
}
4. 调用ElasticsearchRestTemplate方法来实现CRUD的方式
模糊查询
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
//使用Template进行关键字查询
//关于正则表达式可以参考https://www.runoob.com/java/java-regular-expressions.html
//.*data.* 可以匹配ddata, dataa等
@Test
void queryTileContainByTemplate() {
Query query = new NativeSearchQueryBuilder().withFilter(regexpQuery("title",".*elasticsearch2.*")).build();
SearchHits<Article> articles = elasticsearchRestTemplate.search(query, Article.class, IndexCoordinates.of("blog"));
System.out.println(JSON.toJSONString(articles));
}
ES的方法命名规则(可以根据接口命名自动实现CRUD方法)
| 关键字 | 使用示例 | 等同于的ES查询 |
|---|---|---|
| And | findByNameAndPrice | {“bool” : {“must” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}} |
| Or | findByNameOrPrice | {“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}} |
| Is | findByName | {“bool” : {“must” : {“field” : {“name” : “?”}}}} |
| Not | findByNameNot | {“bool” : {“must_not” : {“field” : {“name” : “?”}}}} |
| Between | findByPriceBetween | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| LessThanEqual | findByPriceLessThan | {“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| GreaterThanEqual | findByPriceGreaterThan | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}} |
| Before | findByPriceBefore | {“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}} |
| After | findByPriceAfter | {“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}} |
| Like | findByNameLike | {“bool” : {“must” : {“field” : {“name” : {“query” : “? *”,”analyze_wildcard” : true}}}}} |
| StartingWith | findByNameStartingWith | {“bool” : {“must” : {“field” : {“name” : {“query” : “? *”,”analyze_wildcard” : true}}}}} |
| EndingWith | findByNameEndingWith | {“bool” : {“must” : {“field” : {“name” : {“query” : “*?”,”analyze_wildcard” : true}}}}} |
| Contains/Containing | findByNameContaining | {“bool” : {“must” : {“field” : {“name” : {“query” : “?”,”analyze_wildcard” : true}}}}} |
| In | findByNameIn(Collectionnames) | {“bool” : {“must” : {“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“name” : “?”}} ]}}}} |
| NotIn | findByNameNotIn(Collectionnames) | {“bool” : {“must_not” : {“bool” : {“should” : {“field” : {“name” : “?”}}}}}} |
| True | findByAvailableTrue | {“bool” : {“must” : {“field” : {“available” : true}}}} |
| False | findByAvailableFalse | {“bool” : {“must” : {“field” : {“available” : false}}}} |
| OrderBy | findByAvailableTrueOrderByNameDesc | {“sort” : [{ “name” : {“order” : “desc”} }],”bool” : {“must” : {“field” : {“available” : true}}}} |
spring整合Elasticsearch和低级客户端
参考资料:【黑马Elasticseach全套教程,含DSL查询语法、数据聚合、ES集合,最后配有黑马旅游网案例】https://www.bilibili.com/video/BV1b8411Z7w5?vd_source=33f1ebaa37460447a79a3df9458341f4
引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.12.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.12.1</version>
</dependency>
创建连接
RestClient restClient = RestClient.builder(
new HttpHost("47.99.xx.xx", 92xx, "http"))
.build();
或者使用单例模式和验证账号密码:
package com.xxx.xxx.xxx;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import java.io.IOException;
/**
* @description: 获取ES连接
* @author:
* @time:
**/
public class ElasticSearchClient {
private static RestClient client;
private ElasticSearchClient() {
// 私有构造函数,防止外部实例化
}
public static synchronized RestClient getClient() {
if (client == null) {
createClient();
}
return client;
}
private static void createClient() {
RestClientBuilder builder = RestClient.builder(
new HttpHost("47.99.xx.xx", 9211, "http")
);
// 设置认证信息
BasicCredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "xxxxxxxx"));
// 自定义HttpClientBuilder以设置认证提供程序
builder.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
client = builder.build();
}
// 关闭客户端连接(在应用程序关闭时调用)
public static void closeClient(){
if (client != null) {
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
client = null;
}
}
}
低级客户端实现CRUD
新增
POST /products/_doc
{
"product_id": 1,
"name": "Laptop",
"description": "A powerful laptop for professionals",
"price": 1499.99,
"tags": ["electronics", "laptop", "workstation"]
}
更新
-
全量更新
与新增的相同
-
局部更新
POST /products/_update/1 { "doc": { "price": 1599.99 } }
删除
-
根据id删除
例如,假设我们有一个名为
products的索引,并且我们想要删除ID为1的文档:jsonDELETE /products/_doc/1或者,如果你在Elasticsearch 8.x或更高版本中,你可以省略类型部分:
jsonDELETE /products/1 -
根据条件范围删除(如下,根据price的值大于0小于100来删除文档,price需要是
float、double、integer或long等数值的属性类型)POST /products/_delete_by_query { "query": { "range": { "price": { "gt": 0, // 大于0 "lt": 100 // 小于100 } } } } -
根据某个属性等于某个值来删除
POST /my_index/_delete_by_query { "query": { "term": { "field_name": "specific_text" } } }在上方例子中,
term查询用于精确匹配field_name字段的值。如果你想要进行模糊匹配或基于分析器的匹配,你可以使用match查询。POST /my_index/_delete_by_query { "query": { "match": { "field_name": "specific_text" } } }
查询
-
根据条件范围查询
如果你想在Elasticsearch(ES)中根据某个字段的值大于或小于某个特定值来搜索记录,你可以使用
range查询。以下是一个基本示例,假设我们有一个名为
products的索引,并且我们想要找到价格大于10且小于100的所有产品:GET /products/_search { "query": { "range": { "price": { "gt": 10, // 大于10 "lt": 100 // 小于100 } } } }在这个查询中:
gt代表“大于”。lt代表“小于”。
你也可以结合使用
gte(大于或等于)和lte(小于或等于)来创建更复杂的范围查询。如果你需要根据多个条件进行范围查询,可以简单地添加更多的条件:
GET /products/_search { "query": { "bool": { "must": [ { "range": { "price": { "gt": 10 } } }, { "range": { "stock": { "lt": 100 } } } ] } } }在上面的查询中,我们同时搜索价格大于10且库存小于100的产品。
注意:确保你的字段已经被正确地映射为可以执行范围查询的类型(例如
float、double、integer或long)。如果字段是文本类型,你可能需要先将其转换为数字类型或使用其他查询方法。 -
字段值匹配的精准查询
GET /your_index/_search { "query": { "term": { "your_field": "your_value" } } }/** * 按字段查询ES * * @param baseinfo * @return * @throws Exception */ public List<BksMaterialBaseinfo> accurateSelectByEs(BksMaterialBaseinfo baseinfo) throws Exception { ArrayList<BksMaterialBaseinfo> bksMaterialBaseinfos = new ArrayList<>(); StringBuilder jsonString = new StringBuilder(); jsonString.append("{\"query\":{\"bool\":{\"must\":["); //遍历取出BksMaterialBaseinfo中不为空的属性 if (baseinfo == null) { throw new IllegalArgumentException("Object cannot be null"); } Class<?> clazz = baseinfo.getClass(); boolean isFirst = true; for (Field field : clazz.getDeclaredFields()) { //取消访问修饰符的限制 field.setAccessible(true); try { Object value = field.get(baseinfo); // 检查属性值是否为空 if (value != null && !field.getName().equals("serialVersionUID")) { //第一个非空的属性前面不加“,”号,后续非空的属性前面加“,”号 if (!isFirst) { jsonString.append(","); } jsonString.append("{\"match\":{\"").append(field.getName()).append("\":\"").append(value).append("\"}}"); isFirst = false; } } catch (IllegalAccessException e) { e.printStackTrace(); } } jsonString.append("],"); //排除已删除的记录 jsonString.append("\"must_not\": ["); jsonString.append("{\n" + " \"term\": {\n" + " \"delFlag\": \"0\"\n" + " }\n" + " }"); jsonString.append("]}}}"); // 创建 HttpGet 请求 Request indexRequest = new Request("POST", "/test/_doc/_search"); indexRequest.setJsonEntity(jsonString.toString()); //Request indexRequest = new Request("GET", "/test/_doc/1"); //查询id为1 // 执行同步请求并获取响应 Response response = restClient.performRequest(indexRequest); //es返回的json对象映射为javabean ObjectMapper objectMapper = new ObjectMapper(); String jsonResponse = EntityUtils.toString(response.getEntity()); BksElasticsearchResponse elasticsearchResponse = objectMapper.readValue(jsonResponse, BksElasticsearchResponse.class); for (BksElasticsearchResponse.Hits.Hit hit : elasticsearchResponse.getHits().getHits()) { BksMaterialBaseinfo source = hit.get_source(); bksMaterialBaseinfos.add(source); } return bksMaterialBaseinfos; } -
模糊查询
-
使用match查询进行模糊查询,其使用分析器来分析查询字符串和字段值,并尝试找到最佳的匹配。
GET /your_index/_search { "query": { "match": { "your_field": "your_text" } } } -
使用wildcard查询进行模糊查询,其使用通配符来匹配字符串。
GET /your_index/_search { "query": { "wildcard": { "your_field": "*your_text*" } } } -
使用regexp查询进行正则表达式查询
GET /your_index/_search { "query": { "regexp": { "your_field": ".*your_text.*" } } }在这个例子中,
.*your_text.*是一个正则表达式,表示任何包含your_text的字符串。正则表达式提供了更强大的匹配能力,但也更复杂。
-
创建响应体的解析对象
package com.bks.client.domain; import com.bks.material.domain.BksMaterialBaseinfo; import com.fasterxml.jackson.annotation.JsonIgnoreProperties; import java.util.List; /** * @description: ES响应体的实体类 * @author:czq * @time:2024/3/31 **/ @JsonIgnoreProperties(ignoreUnknown = true) // 忽略所有未知属性 public class BksElasticsearchResponse { private int took; private boolean timed_out; private Shards _shards; private Hits hits; public int getTook() { return took; } public void setTook(int took) { this.took = took; } public boolean isTimed_out() { return timed_out; } public void setTimed_out(boolean timed_out) { this.timed_out = timed_out; } public Hits getHits() { return hits; } public void setHits(Hits hits) { this.hits = hits; } public Shards get_shards() { return _shards; } public void set_shards(Shards _shards) { this._shards = _shards; } public static class Shards { private int total; private int successful; private int skipped; private int failed; public int getTotal() { return total; } public void setTotal(int total) { this.total = total; } public int getSuccessful() { return successful; } public void setSuccessful(int successful) { this.successful = successful; } public int getSkipped() { return skipped; } public void setSkipped(int skipped) { this.skipped = skipped; } public int getFailed() { return failed; } public void setFailed(int failed) { this.failed = failed; } @Override public String toString() { return "Shards{" + "total=" + total + ", successful=" + successful + ", skipped=" + skipped + ", failed=" + failed + '}'; } } public static class Hits { private Total total; private float max_score; private List<Hit> hits; public Total getTotal() { return total; } public void setTotal(Total total) { this.total = total; } public float getMax_score() { return max_score; } public void setMax_score(float max_score) { this.max_score = max_score; } public List<Hit> getHits() { return hits; } public void setHits(List<Hit> hits) { this.hits = hits; } @Override public String toString() { StringBuilder hitsStr = new StringBuilder(""); for (Hit hit:hits) { hitsStr.append(hit.toString()); } return "Hits{" + "total=" + total.toString() + ", max_score=" + max_score + ", hits=" + hitsStr + '}'; } public static class Total { private int value; private String relation; public int getValue() { return value; } public void setValue(int value) { this.value = value; } public String getRelation() { return relation; } public void setRelation(String relation) { this.relation = relation; } @Override public String toString() { return "Total{" + "value=" + value + ", relation='" + relation + '\'' + '}'; } } public static class Hit { private String _index; private String _type; private String _id; private float _score; private BksMaterialBaseinfo _source; public String get_index() { return _index; } public void set_index(String _index) { this._index = _index; } public String get_type() { return _type; } public void set_type(String _type) { this._type = _type; } public String get_id() { return _id; } public void set_id(String _id) { this._id = _id; } public float get_score() { return _score; } public void set_score(float _score) { this._score = _score; } public BksMaterialBaseinfo get_source() { return _source; } public void set_source(BksMaterialBaseinfo _source) { this._source = _source; } @Override public String toString() { return "Hit{" + "_index='" + _index + '\'' + ", _type='" + _type + '\'' + ", _id='" + _id + '\'' + ", _score=" + _score + ", _source=" + _source.toString() + '}'; } } } @Override public String toString() { return "BksElasticsearchResponse{" + "took=" + took + ", timed_out=" + timed_out + ", shards=" + _shards.toString() + ", hits=" + hits.toString() + '}'; } } -
发起模糊查询的请求
/** * 模糊查询 * * @param value 模糊查询的字符串 * @return 材料基本信息列表 * @throws Exception */ @Override public List<BksMaterialBaseinfo> blurredSelect(String value) throws Exception { ArrayList<BksMaterialBaseinfo> bksMaterialBaseinfos = new ArrayList<>(); String jsonString = "{" + " \"query\": {" + " \"bool\": {" + " \"must\": [" + " {\"query_string\": {\"query\": \"*" + value + "*\"}}" + " ]," + " \"must_not\": [" + " {\"term\": {\"delFlag\": \"0\"}}" + " ]" + " }" + " }" + "}"; // 创建 HttpGet 请求 Request indexRequest = new Request("GET", "/test/_doc/_search"); indexRequest.setJsonEntity(jsonString); // 执行同步请求并获取响应 Response response = restClient.performRequest(indexRequest); ObjectMapper objectMapper = new ObjectMapper(); String jsonResponse = EntityUtils.toString(response.getEntity()); BksElasticsearchResponse elasticsearchResponse = objectMapper.readValue(jsonResponse, BksElasticsearchResponse.class); for (BksElasticsearchResponse.Hits.Hit hit : elasticsearchResponse.getHits().getHits()) { BksMaterialBaseinfo source = hit.get_source(); bksMaterialBaseinfos.add(source); } return bksMaterialBaseinfos; }
-
批量导入
/**
* mysql批量导入ES
*
* @param pageSize 每页最多多少条记录,分页导入
* @param updateTime 查询更新时间大于updateTime的记录
* @return
*/
@Override
public String batchMysqlToES(int pageSize, String updateTime) {
if (pageSize <= 0 || updateTime.isEmpty() || updateTime.equals("")) {
log.error("参数错误");
return "参数错误";
}
log.info("batchMysqlToES分页导入开始,每页记录条数pageSize=" + pageSize + ",更新的起始时间点updateTime=" + updateTime);
String status = "未成功发送数据到ES";
//材料基本信息记录数
BksMaterialBaseinfo bksMaterialBaseinfo = new BksMaterialBaseinfo();
bksMaterialBaseinfo.setDelFlag("0");
int total = bksMaterialBaseinfoMapper.selectBksMaterialBaseinfoListBatchCount(updateTime);
if (total == 0) {
status = "记录条数为0";
}
//计算总页数(总记录数除以每页记录数向上取整)
int pageNumCount = (int) Math.ceil((double) total / pageSize);
//循环查询和发送每一页数据到ES
for (int i = 1; i <= pageNumCount; i++) {
Page<BksMaterialBaseinfo> page = PageHelper.startPage(i, pageSize)
.doSelectPage(() -> bksMaterialBaseinfoMapper.selectBksMaterialBaseinfoListBatch(updateTime));
status = dataToES(restClient, page.getResult());
if (!status.equals("200")) {
continue;
} else {
log.info("batchMysqlToES分页更新,在第" + i + "页更新了" + page.getResult().size() + "条记录!");
}
}
log.info("batchMysqlToES分页导入结束,status:" + status);
return status;
}
/**
* 将查询出来的数据,构造成json,批量发送到ES
*
* @param restClient ES客户端
* @param baseinfos 查询出来的数据
* @return ES的响应体的状态码或报错信息
* @throws Exception
*/
public String dataToES(RestClient restClient, List<BksMaterialBaseinfo> baseinfos) {
try {
//数据批量存储进ES
List<String> actions = new ArrayList<>();
for (BksMaterialBaseinfo baseInfo : baseinfos) {
//将实体转换成JSON串,批量更新到ES
String jsonString = JSON.toJSONString(baseInfo);
actions.add("{\"index\":" + "{\"_id\":\"" + baseInfo.getId() + "\"}}\n");
actions.add(jsonString + "\n");
}
// 合并所有文档到一个字符串中
String jsonString = String.join("", actions);
// 创建请求实体
StringEntity requestEntity = new StringEntity(jsonString, ContentType.APPLICATION_JSON);
// 发送POST请求到_bulk端点
Request indexRequest = new Request("POST", "/test/_bulk");
indexRequest.setJsonEntity(jsonString);
Response indexResponse = restClient.performRequest(indexRequest);
// 返回响应体状态
return String.valueOf(indexResponse.getStatusLine().getStatusCode());
} catch (Exception e) {
// 返回报错
log.error("batchMysqlToES报错:" + e);
return e.getLocalizedMessage();
}
}
ES的DSL语法
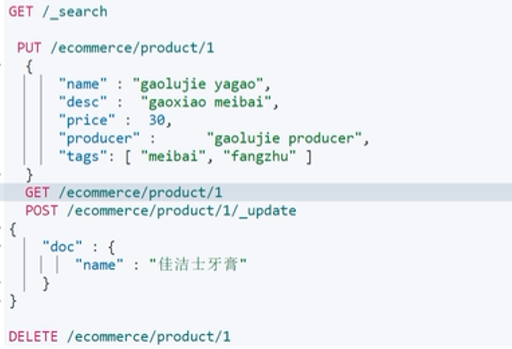
——来自【【码神之路】之Spring Boot教程,十年大厂程序员讲解,通俗易懂】https://www.bilibili.com/video/BV1L5411g7KP?p=21&vd_source=33f1ebaa37460447a79a3df9458341f4
——来自【尚硅谷SpringBoot整合教程(springboot框架实战)】https://www.bilibili.com/video/BV1KW411F7oX?p=21&vd_source=33f1ebaa37460447a79a3df9458341f4
数据同步方案
方案1~3来自黑马程序员B站教程:https://www.bilibili.com/video/BV1Gh411j7d6/?p=56&vd_source=38f14506b4ac32b899b010f24c1ab966
方案1:在业务接口中对应更新ES索引
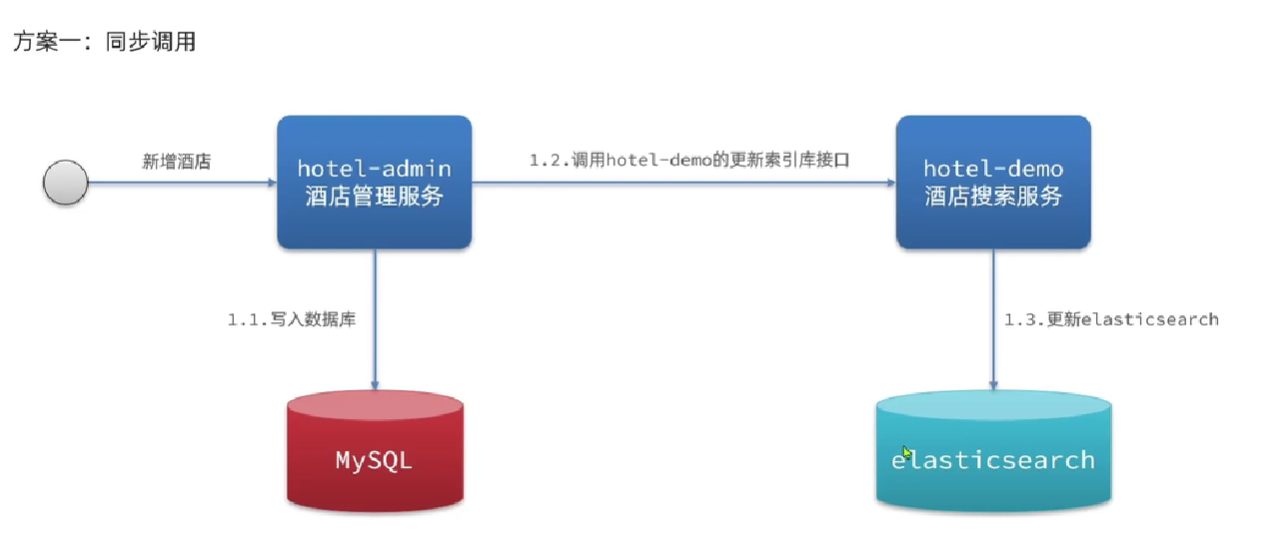
方案2:使用MQ异步通知后更新ES索引
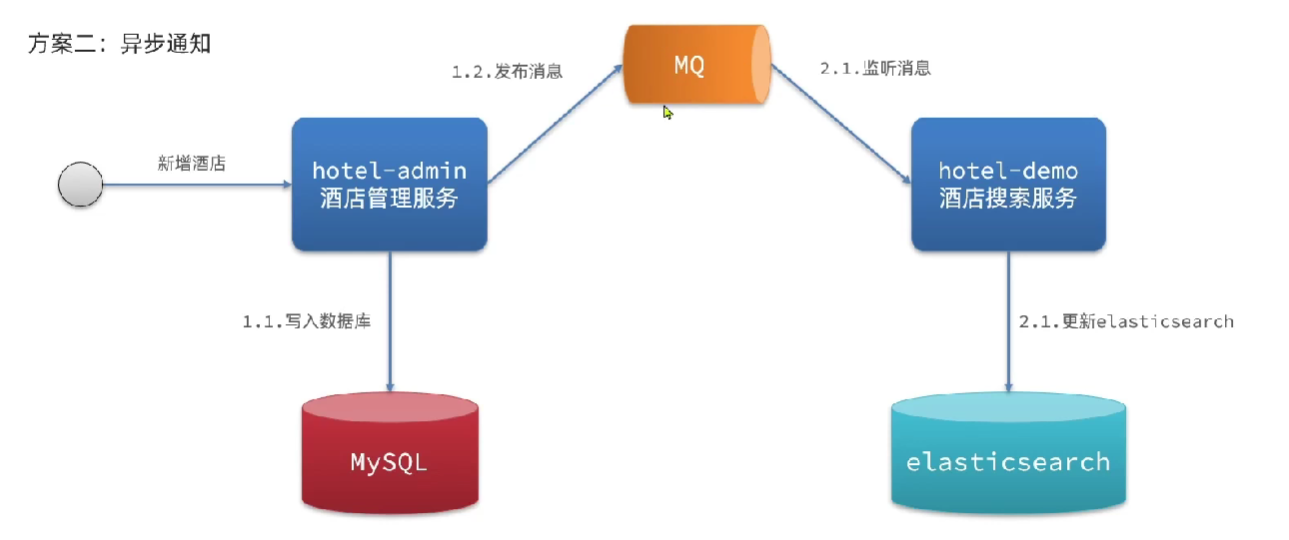
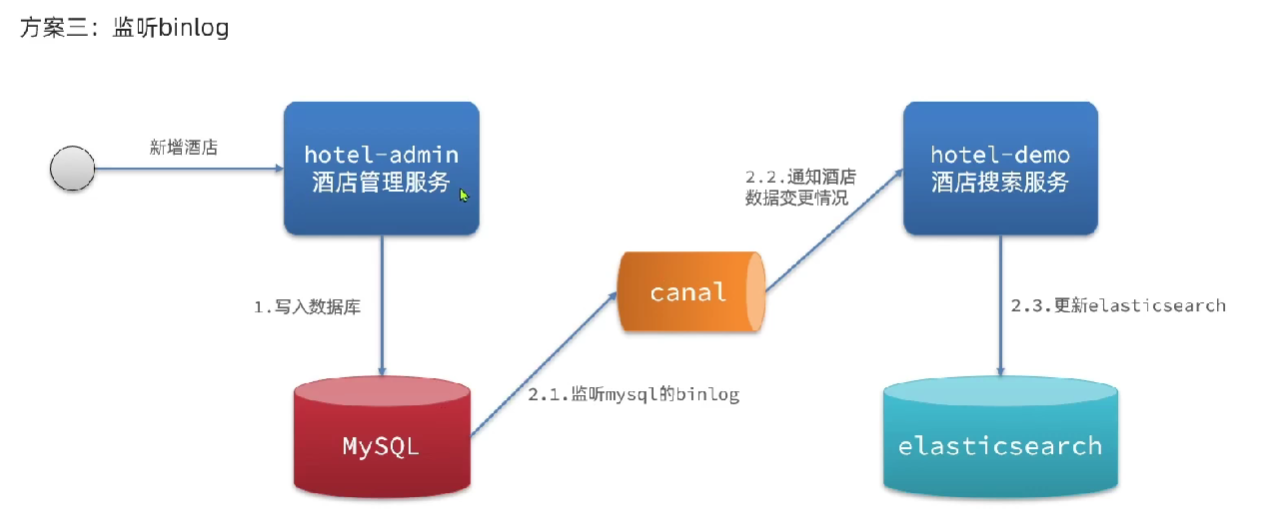
方案3:使用canal监听mysql变更,通知到MQ,MQ通知ES更新索引
canal github:https://github.com/alibaba/canal ,为阿里开源框架,是Otter中间件中的一小中间件。
采用Canal进行Mysql to ElasticSearch数据同步:https://zhuanlan.zhihu.com/p/159751188
方案4:当mysqL数据变动使用自定义spring监听器+事件方式
缺点:无法实现数据重做
拓展:异步事件监听器:@Async
1:自定义监听事件
2:自定义监所器,监所自定义事件定制事件触发之后执行逻辑
3:定制触发自定义事件逻辑--触发器
//ctx.publishEvent(new StrategyCRUDEvent(entity,1));
//ctx.publishEvent(new StrategyCRUDEvent(entity,2));
//ctx.publishEvent(new StrategyCRUDEvent(1L,3));
方案5:使用Logstash轮询mysql,有变更就更新到ES
详情见:https://blog.csdn.net/w1014074794/article/details/125249780
一些问题处理:
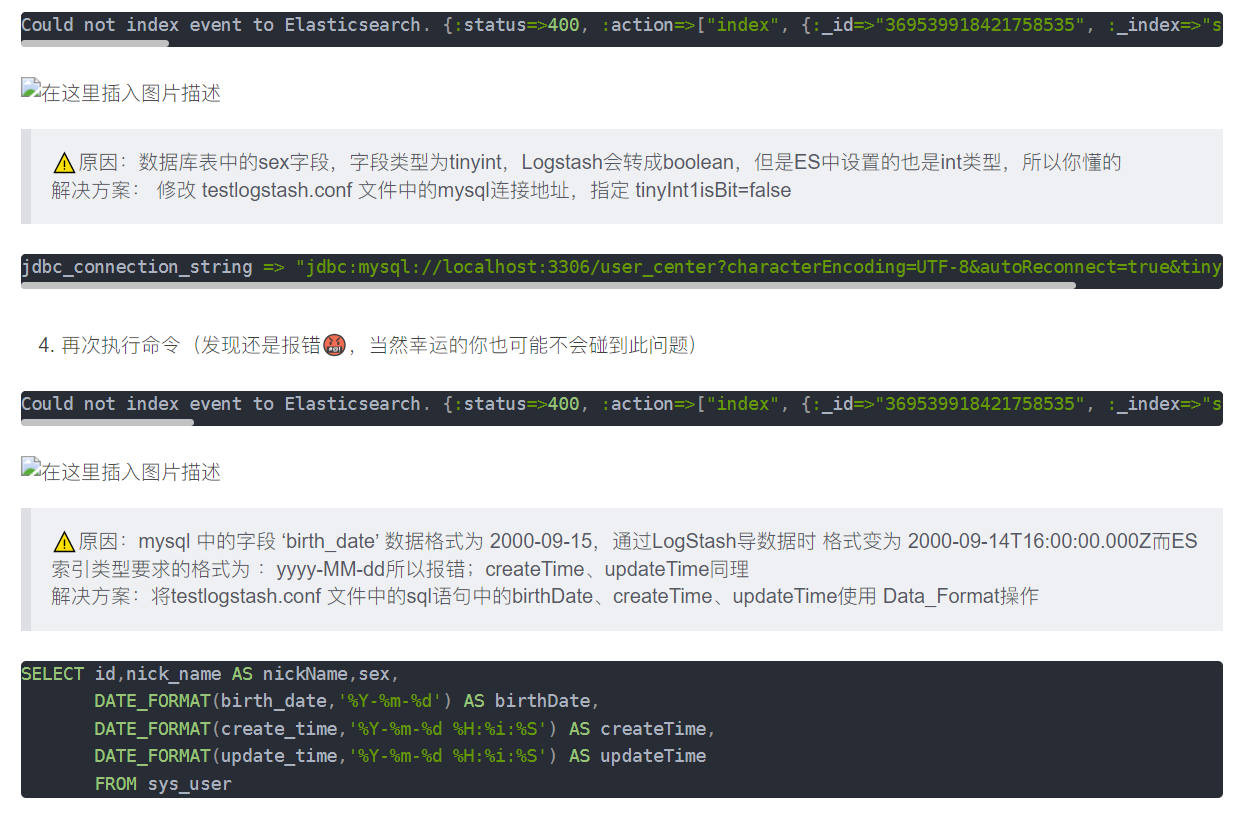
——https://blog.csdn.net/weixin_45394216/article/details/132906233
方案6:使用Logstash监听mysql变更,有变更自动更新到ES
-
下载并安装Logstash到服务器
对于部署在Docker容器中的Elasticsearch和Kibana,你可以选择在宿主机(服务器)上下载和安装Logstash,而不是在Elasticsearch的Docker容器中进行操作。这是因为Logstash通常用于处理和转发数据到Elasticsearch集群,而不是直接运行在Elasticsearch容器内。同时要注意Logstash版本号要与ES一致,都是
7.12.1。以下是在宿主机上下载和安装Logstash的步骤:
-
打开终端或SSH连接
打开终端或使用SSH等远程登录工具连接到宿主机(服务器)。 -
下载Logstash
在终端中,运行以下命令下载Logstash的压缩文件:curl -O https://artifacts.elastic.co/downloads/logstash/logstash-{version}.tar.gz其中,
{version}是指你想要下载的Logstash版本号。可以在官方网站上查找所需的版本号。 -
解压Logstash
接下来,在终端中运行以下命令解压下载的Logstash压缩文件:tar -xzf logstash-{version}.tar.gz这将创建一个名为
logstash-{version}的文件夹。 -
配置Logstash(可选)
在启动Logstash之前,你可能需要配置一些参数,例如输入、过滤和输出。在Logstash的安装目录下找到config文件夹,然后编辑其中的配置文件,如logstash.yml和pipeline.yml。 -
启动Logstash
在终端中运行以下命令启动Logstash:cd logstash-{version} bin/logstash -f your_config_file.conf其中,
your_config_file.conf是你提前准备好的Logstash配置文件,用于指定输入、过滤和输出等。
通过以上步骤,你可以在宿主机上下载和安装Logstash,并配置它与Elasticsearch和Kibana进行集成和数据传输。
-
-
浏览器打开kibana的Dev Tools创建ES索引
PUT /mytest_user { "mappings":{ "properties":{ "id":{ "type":"long' }, "name":{ "type":"text" }, "age":{ type":"long' } } } } -
配置 Logstash
-
新建logstash-X.X.X/sync/logstash-db-sync.conf配置文件或者在安装目录的config文件夹下的
logstash.yml和pipeline.yml,配置 MySQL 连接,并启用 binlog 监听:input { jdbc { jdbc_connection_string => "jdbc:mysql://your_mysql_host:your_mysql_port/your_database" jdbc_user => "your_username" jdbc_password => "your_password" jdbc_driver_library => "/path/to/mysql-connector-java.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" statement => "SET GLOBAL binlog_format = 'ROW';" use_column_value => true tracking_column => "your_primary_key_field" tracking_column_type => "numeric" clean_run => true record_last_run => true last_run_metadata_path => "/path/to/your/last_run_metadata" schedule => "* * * * *" } } -
配置Logstash输出
output { elasticsearch { hosts => ["your_elasticsearch_host:your_elasticsearch_port"] index => "your_index" document_id => "%{[your_primary_key_field]}" } }
-
-
启动 Logstash
在 Logstash 目录下,运行
bin/logstash -f your_config_file.conf命令来启动 Logstash。 -
数据同步
-
Logstash 将会监听 MySQL 的 binlog,当有数据变更时,会将变更的数据发送到 Elasticsearch。
-
通过查询 Elasticsearch,可以验证数据是否成功同步到了 Elasticsearch。
需要注意的是,使用 binlog 监听方式可以实现更实时的数据同步,但也会增加系统资源的使用,并对数据库产生一定的影响。因此,在使用这种方式时,建议根据实际情况进行性能评估和调优。
此外,还需要确保 MySQL 的 binlog 和 Logstash 的配置正确,以及正确配置 Elasticsearch 的连接等信息。根据具体需求和使用情况,可以进一步调整配置,例如根据不同的表进行筛选、转换数据等。
-
方案7:定时任务查询更新
配置定时任务,根据记录的updateTime查询最近更新的记录分页批量更新到ES。
Elasticsearch和spring data Elasticsearch
spring data Elasticsearch是spring对Elasticsearch的再次封装,使其与其他spring Data框架统一风格,但版本上一般落后于最新的Elasticsearch。
- spring data Elasticsearch:spring-boot-starter-data-elasticsearch
官方文档:Spring Data Elasticsearch - Reference Documentation - Elasticsearch:Java High Level Rest Client
官方文档:Java High Level REST Client | Java REST Client 7.6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号